자연어 처리가 어려운 이유
같은 자연어가 두 개 이상의 의미를 가지는 경우
한국어 자연어 처리 (교착어 : 어근에 붙은 접사에 따라 의미가 변하는 언어) - 접사와 조사 처리
유연한 어순
{단어 : 빈도}로 텍스트 정제
# 영어 데이터 : nltk
import nltk
nltk.download('punkt') # 마침표나 약어, 언어적 특성 같은걸 고려해줌
TEXT = """After reading the comments for this movie, I am not sure whether I should be angry, sad or sickened. Seeing comments typical of people who a)know absolutely nothing about the military or b)who base everything they think they know on movies like this or on CNN reports about Abu-Gharib makes me wonder about the state of intellectual stimulation in the world. At the time I type this the number of people in the US military: 1.4 million on Active Duty with another almost 900,000 in the Guard and Reserves for a total of roughly 2.3 million. The number of people indicted for abuses at at Abu-Gharib: Currently less than 20 That makes the total of people indicted .00083% of the total military. Even if you indict every single military member that ever stepped in to Abu-Gharib, you would not come close to making that a whole number. The flaws in this movie would take YEARS to cover. I understand that it's supposed to be sarcastic, but in reality, the writer and director are trying to make commentary about the state of the military without an enemy to fight. In reality, the US military has been at its busiest when there are not conflicts going on. The military is the first called for disaster relief and humanitarian aid missions. When the tsunami hit Indonesia, devestating the region, the US military was the first on the scene. When the chaos of the situation overwhelmed the local governments, it was military leadership who looked at their people, the same people this movie mocks, and said make it happen. Within hours, food aid was reaching isolated villages. Within days, airfields were built, cargo aircraft started landing and a food distribution system was up and running. Hours and days, not weeks and months. Yes there are unscrupulous people in the US military. But then, there are in every walk of life, every occupation. But to see people on this website decide that 2.3 million men and women are all criminal, with nothing on their minds but thoughts of destruction or mayhem is an absolute disservice to the things that they do every day. One person on this website even went so far as to say that military members are in it for personal gain. Wow! Entry level personnel make just under $8.00 an hour assuming a 40 hour work week. Of course, many work much more than 40 hours a week and those in harm's way typically put in 16-18 hour days for months on end. That makes the pay well under minimum wage. So much for personal gain. I beg you, please make yourself familiar with the world around you. Go to a nearby base, get a visitor pass and meet some of the men and women you are so quick to disparage. You would be surprised. The military no longer accepts people in lieu of prison time. They require a minimum of a GED and prefer a high school diploma. The middle ranks are expected to get a minimum of undergraduate degrees and the upper ranks are encouraged to get advanced degrees."""from nltk.tokenize import word_tokenize
tokenized_words = word_tokenize(TEXT)
import pandas as pd
dic = {}
for i in tokenized_words:
if i not in dic:
dic[i] = 1
else:
dic[i] += 1
a = pd.DataFrame({'WORD' : dic.keys(), 'FREQ' : dic.values()}) # 단어 : 빈도
a.sort_values('FREQ', ascending = False)
텍스트 마이닝 : 완성한 후에 결과를 보고 고쳐야함.
토픽 모델링 : 빈도가 아주 적은 것과 아주 많은게 문제
빈도수, 길이가 cut_off_count 이하인 단어를 제거
def clean_by_freq(tokenized_words, cut_off_count):
vocab = Counter(tokenized_words)
# 빈도수가 cut_off_count 이하인 단어를 제거하는 코드를 작성해 주세요
uncommon_words = {key for key, value in vocab.items() if value <= cut_off_count}
cleaned_words = [word for word in tokenized_words if word not in uncommon_words]
return cleaned_words
def clean_by_len(tokenized_words, cut_off_length):
cleaned_words = []
for word in tokenized_words:
# 길이가 cut_off_length 이하인 단어 제거하는 코드를 작성해 주세요
if len(word) > cut_off_length:
cleaned_words.append(word)
return cleaned_words
# 문제의 조건에 맞게 함수를 호출해 주세요
clean_by_freq = clean_by_freq(tokenized_words, 2)
cleaned_words = clean_by_len(clean_by_freq, 2)
cleaned_words
불용어 처리
# 불용어 처리
from nltk.corpus import stopwords
nltk.download('stopwords')
stopword_set = set(stopwords.words('english'))
stopword_set
불용어 추가
# 추가적으로 넣고싶은 불용어
added_stopwords = ['oh', 'the', 'i']
stopwords_set = set(stopwords.words('english'))
stopwords_set.update(added_stopwords)
stopwords_set
불용어 집합 추가 / 제거
# 불용어 집합에서 추가,제거하고 싶은 단어가 있을때
stopwords_set.add('hello')
stopwords_set.remove('the')
빈도가 적게 나온 단어, 길이가 짧은 단어, 불용어에 있는 단어 모두 제거
# 빈도가 적게 나온 단어, 길이가 짧은 단어, 불용어에 있는 단어 모두 제거
cleaned_words = []
for word in cleaned_by_freq_len:
if word not in stopwords_set:
cleaned_words.append(word)
print(f'불용어 제거 전 : {len(cleaned_by_freq_len)}')
print(f'불용어 제거 후 : {len(cleaned_words)}')
불용어 제거
# 불용어 제거 함수
def clean_by_stopwords(tokenized_words, stop_words_set):
cleaned_words = []
for word in tokenized_words:
if word not in stop_words_set:
cleaned_words.append(word)
return cleaned_words
정규화
소문자 처리
TEXT.lower()
규칙 기반 정규화 US, U.S, USA, Um, Umm, Ummm
# 규칙 기반 정규화 US, U.S, USA, Um, Umm, Ummm
import nltk
from nltk.tokenize import word_tokenize
dic = {'US' : 'USA', 'U.S' : 'USA', 'Ummmm' : 'Umm'}
text2 = 'she became a US citizen, Ummmm'
normalized_words = []
tokenized_words = word_tokenize(text2)
for word in tokenized_words:
if word in dic.keys():
word = dic[word]
normalized_words.append(word)
print(normalized_words)
어간 추출
NLTK(Natural Language Toolkit)를 사용하여 단어의 기본 형태(어간)를 추출
# 어간 추출 (원형으로 바꾸기)
from nltk.stem import PorterStemmer
# PorterStemmer 객체 생성
porter = PorterStemmer()
text3 = 'You are so lovely. I am loving you now'
tokenized_words = word_tokenize(text3)
stemmed_words = []
for word in tokenized_words:
stem = porter.stem(word)
stemmed_words.append(stem)
print(stemmed_words)
어간 추출 함수
from nltk.stem import PorterStemmer
# 포터 스테머 어간 추출 함수
def stemming_by_porter(tokenized_words):
porter_stemmer = PorterStemmer()
porter_stemmed_words = []
for word in tokenized_words:
stem = porter_stemmer.stem(word)
porter_stemmed_words.append(stem)
return porter_stemmed_words
실습 : 데이터 불러와서 자연어 처리
import pandas as pd
def clean_by_freq(tokenized_words, cut_off_count):
vocab = Counter(tokenized_words)
# 빈도수가 cut_off_count 이하인 단어를 제거하는 코드를 작성해 주세요
uncommon_words = {key for key, value in vocab.items() if value <= cut_off_count}
cleaned_words = [word for word in tokenized_words if word not in uncommon_words]
return cleaned_words
def clean_by_len(tokenized_words, cut_off_length):
cleaned_words = []
for word in tokenized_words:
# 길이가 cut_off_length 이하인 단어 제거하는 코드를 작성해 주세요
if len(word) > cut_off_length:
cleaned_words.append(word)
return cleaned_words
df = pd.read_csv('imdb.tsv', sep = '\t')
del df['Unnamed: 0']
# 1. 소문자 처리
df['review'] = df['review'].str.lower()
# 2. 토큰화
df['word_tokens'] = df['review'].apply(word_tokenize)
# 3. 불용어 처리
stopwords_set = set(stopwords.words('english'))
stopwords_set = set(stopwords.words('english')) # 불용어 집합 생성
df['cleaned_tokens'] = df['word_tokens'].apply(lambda x : clean_by_freq(x, 1)) # 빈도수가 1 이하인 단어를 제거
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x : clean_by_len(x, 2)) # 길이가 2 이하인 단어를 제거
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x : clean_by_stopwords(x, stopwords_set)) # 불용어를 제거
# 4. 어간 추출
df['stemmed_tokens'] = df['cleaned_tokens'].apply(stemming_by_porter) # 어미 잘라주기
df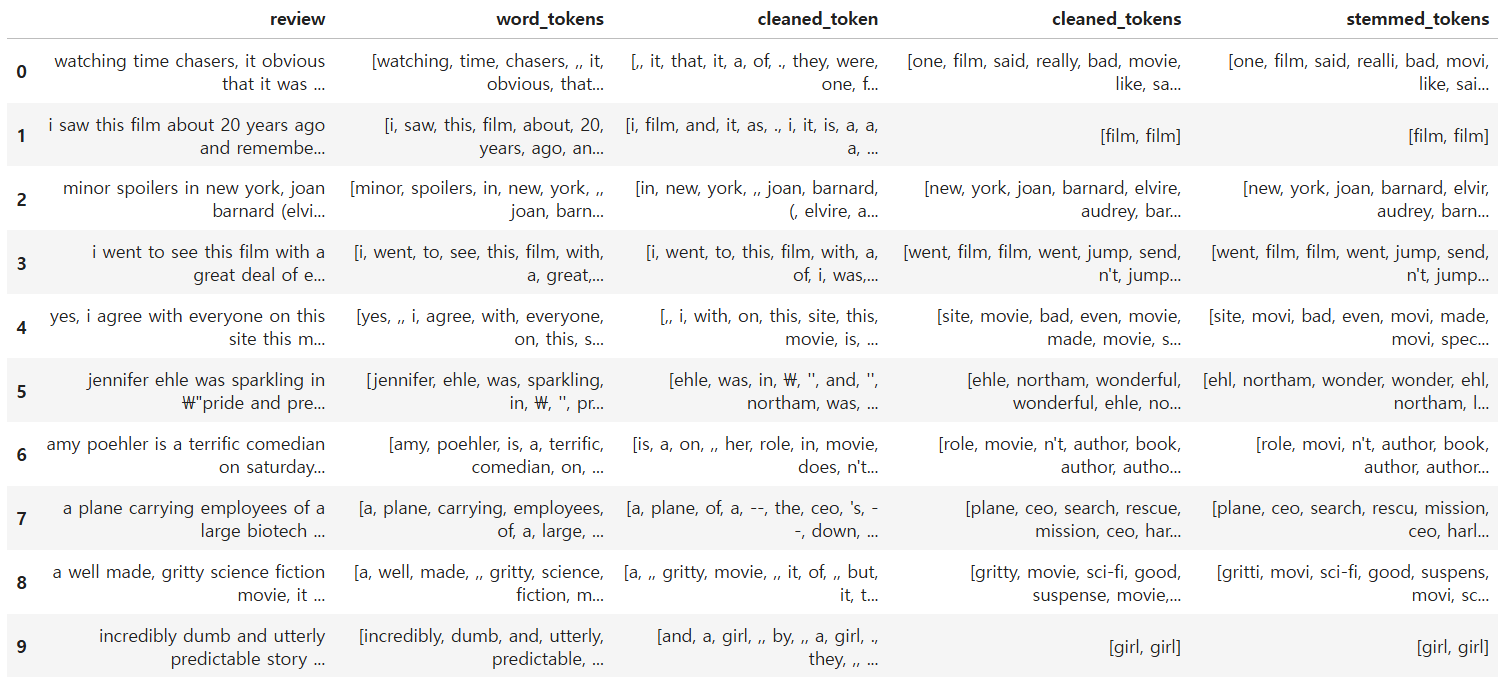
토큰화 하기 전에 문장 단위로 토큰화
# 토큰화 하기 전에 문장 단위로 토큰화
from nltk.tokenize import sent_tokenize
text4 = "My email address is 'abcde@codeit.com'. Send it to Mr.Kim."
sent_tokenize(text4)
주어진 텍스트에서 문장을 분리하고, 품사 태깅
# 빈도 분석 / 명사, 동사, 형용사
from nltk.tag import pos_tag
pos_tagged_words = []
tokenized_sents = sent_tokenize(TEXT)
for sentence in tokenized_sents:
tokenized_words = word_tokenize(sentence)
pos_tags = pos_tag(tokenized_words)
pos_tagged_words += pos_tags
print(pos_tagged_words)
품사 태깅 함수
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# 품사 태깅 함수
def pos_tagger(tokenized_sents):
pos_tagged_words = []
for sentence in tokenized_sents:
# 단어 토큰화
tokenized_words = word_tokenize(sentence)
# 품사 태깅
pos_tagged = pos_tag(tokenized_words)
pos_tagged_words.extend(pos_tagged)
return pos_tagged_wordst = 'hello world!'
tokenized_words = word_tokenize(t)
tagged_words = pos_tagger(tokenized_words)
tagged_words
표제어 추출(lematization)
동사인 경우의 원형, 부사인 경우의 원형이 다를 수가 있음
→ 단어의 의미와 문맥을 고려하여 그 단어의 기본 형태를 반환
WordNet을 활용하여 단어의 의미와 품사를 보다 정교하게 처리할 수 있음.
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet as wn
lemmatizer = WordNetLemmatizer()
for word, tag in tagged_words:
a = lemmatizer.lemmatize(word, wn.NOUN)
print(a)
형용사, 명사, 부사, 동사만 추출
# 형용사, 명사, 부사, 동사만 추출하는 함수
def penn_to_wn(tag):
if tag.startswith('J'): # 입력한 값으로 시작하면 True
return wn.ADJ
elif tag.startswith('N'):
return wn.NOUN
elif tag.startswith('R'):
return wn.ADV
elif tag.startswith('V'):
return wn.VERB
else:
return tag
print(penn_to_wn('NNG'))
품사 태그를 기반으로 표제어 추출 함수
def words_lemmatizer(pos_tagged_words):
# WordNetLemmatizer 객체 생성
lemmatizer = WordNetLemmatizer()
# 표제어로 변환된 단어를 저장할 리스트 초기화
lemmatized_words = []
# 품사 태그가 있는 단어 목록을 반복
for word, tag in pos_tagger_words:
# Penn Treebank 품사 태그를 WordNet 품사 태그로 변환
wn_tag = penn_to_wn(tag)
# 변환된 품사 태그가 명사, 형용사, 부사, 동사 중 하나인지 확인
if wn_tag in (wn.NOUN, wn.ADJ, wn.ADV, wn.VERB):
# 표제어 추출 (lemmatization) 수행
stem = lemmatizer.lemmatize(word, wn_tag)
# 표제어를 리스트에 추가
lemmatized_words.append(stem)
else:
# 위의 조건에 해당하지 않는 단어는 그대로 추가
lemmatized_words.append(word)
# 변환된 표제어 리스트 반환
return lemmatized_words
빈도 1 이하 없애고, 길이 2 이하 없애고, 불용어 처리까지 해서 나온 결과 확인하기
df = pd.read_csv('imdb.tsv', sep = '\t')
del df['Unnamed: 0']
# 리뷰를 소문자로 변환
df['review'] = df['review'].str.lower()
# 문장 단위로 쪼개기
df['sent_tokens'] = df['review'].apply(sent_tokenize)
# 품사 태그 부여
df['pos_tagged_tokens'] = df['sent_tokens'].apply(pos_tagger)
# 빈도 1 이하 없애고, 길이 2 이하 없애고, 불용어 처리까지 해서 나온 결과 확인하기
df['lemmatized_tokens'] = df['pos_tagged_tokens'].apply(words_lemmatizer) # 각 단어의 표제어(원형)를 구하
df['cleaned_tokens'] = df['lemmatized_tokens'].apply(lambda x : clean_by_freq(x, 1)) # 빈도 수가 1 이하인 단어를 제거
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x : clean_by_len(x, 2)) # 길이가 2 이하인 단어를 제거
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x : clean_by_stopwords(x, stopwords_set)) # 불용어 리스트에 포함된 단어들을 제거
df['combined_corpus'] = df['cleaned_tokens'].apply(lambda x : " ".join(x)) # 한문장으로 만들기
df
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| Okt 형태소 분석기(빈도기반), 워드클라우드, 상대빈도분석(오즈비 분석), TF-IDF 분석 (1) | 2024.10.14 |
|---|---|
| 자연어 처리(NLP) - 감성분석, OpenAI (6) | 2024.10.11 |
| 영화 추천 시스템, 동적 크롤링 (4) | 2024.10.02 |
| 시계열, RNN, Seq2Seq, 어텐션, ARIMA, CNN (0) | 2024.09.09 |
| 오차역전파법, 미분과 체인룰, 브로드캐스팅, 텐서 조작 (2) | 2024.09.03 |


