한국어 데이터 : konlpy
- kkma : 서울대, 최신 단어 반영 X
- okt : 트위터에서 만든 형태소 분석기
# 한국어 데이터 : konlpy
# kkma : 서울대, 최신 단어 반영 X
# okt : 트위터에서 만든 형태소 분석기,
from konlpy.tag import Kkma, Okt
okt = Okt()
okt.nouns('아버지가방에들어가신다')→ okt.nouns() : 명사만 추출
Okt 형태소 분석기 기반 - 연설문 빈도 분석
#!pip install koreanize-matplotlib
import koreanize_matplotlib
import matplotlib.pyplot as plt
import pandas as pd
# 빈도 분석(문재인, 박근혜 대통령 연설문)
f = open('speech_moon.txt', 'rt', encoding = 'utf-8')
moon = f.read()
f.close()
f = open('speech_park.txt', 'rt', encoding = 'utf-8')
park = f.read()
f.close()
# 기본 빈도 분석
okt = Okt()
# 두글자 이상인 명사만 추출
moon_nouns = []
for i in okt.nouns(moon):
if len(i) >= 2:
moon_nouns.append(i)
park_nouns = []
for i in okt.nouns(park):
if len(i) >= 2:
park_nouns.append(i)
from collections import Counter
moon_counter = Counter(moon_nouns)
park_counter = Counter(park_nouns)
moon_top10 = moon_counter.most_common(10)
park_top10 = park_counter.most_common(10)
moon_df = pd.DataFrame(moon_top10, columns = ['단어', '빈도']).sort_values('빈도')
park_df = pd.DataFrame(park_top10, columns = ['단어', '빈도']).sort_values('빈도')
plt.title('문재인 대통령 빈도 분석')
plt.barh(moon_df['단어'], moon_df['빈도'])
plt.grid()
plt.show(0)
plt.title('박근혜 대통령 빈도 분석')
plt.barh(park_df['단어'], park_df['빈도'])
plt.grid()
plt.show(0)
워드클라우드
# 빈도수에 따라 색을 설정하는 함수 정의
def custom_color_func(word, font_size, position, orientation, random_state=None, **kwargs):
if moon_counter[word] >= a:
return "black" # 검은색
else:
return "gray" # 회색
a = pd.Series(moon_counter.values()).quantile(0.99) # 상위 1% 빈도
#!pip install wordcloud
from wordcloud import WordCloud
wc = WordCloud(background_color = 'white',
font_path = 'BMDOHYEON_ttf.ttf').generate_from_frequencies(moon_counter)
wc.recolor(color_func = custom_color_func)
plt.imshow(wc)
plt.axis('off')
plt.show()→ 특정 단어만 눈에 띄게 그릴 수 있음
모양 안에 워드클라우드 넣기
from PIL import Image
import numpy as np
from wordcloud import WordCloud
img = np.array(Image.open('하트.png')) # 이미지를 픽셀 단위로
wc = WordCloud(background_color = 'white',
font_path = 'BMDOHYEON_ttf.ttf',
mask = img).generate_from_frequencies(moon_counter)
wc.recolor(color_func = custom_color_func)
plt.imshow(wc)
plt.axis('off')
plt.show()
상대 빈도 분석 : 오즈비 분석
오즈비(odds ratio) : 특정 사건이 다른 사건에 비해 얼마나 더 자주 발생하는지를 비교하는 방법
# 상대 빈도 분석 : 오즈비 분석
moon_df = pd.DataFrame(moon_counter.most_common(), columns = ['단어', '빈도'])
moon_df['대통령'] = '문재인'
park_df = pd.DataFrame(park_counter.most_common(), columns = ['단어', '빈도'])
park_df['대통령'] = '박근혜'
df = pd.concat([moon_df, park_df], ignore_index = True)
# pivot_table()을 사용하여 각 단어의 빈도를 두 연설문에서 비교하는 피벗 테이블 생성
pivot_df = df.pivot_table(index = '단어', columns = '대통령', values = '빈도').fillna(0)
# 각 단어의 빈도를 해당 연설문의 전체 단어 수로 나누어 상대 비율을 계산
pivot_df['문재인 Ratio'] = (pivot_df['문재인'] + 1) / sum(pivot_df['문재인'] + 1)
pivot_df['박근혜 Ratio'] = (pivot_df['박근혜'] + 1) / sum(pivot_df['박근혜'] + 1)
# # 오즈비 계산 (문재인 연설문에서의 상대 비율을 박근혜 연설문에서의 상대 비율로 나눔)
pivot_df['Odds Ratio'] = pivot_df['문재인 Ratio'] / pivot_df['박근혜 Ratio']
# # 오즈비 값을 기준으로 정렬 (작은 값부터 큰 값까지)
pivot_df = pivot_df.sort_values('Odds Ratio')
pivot_df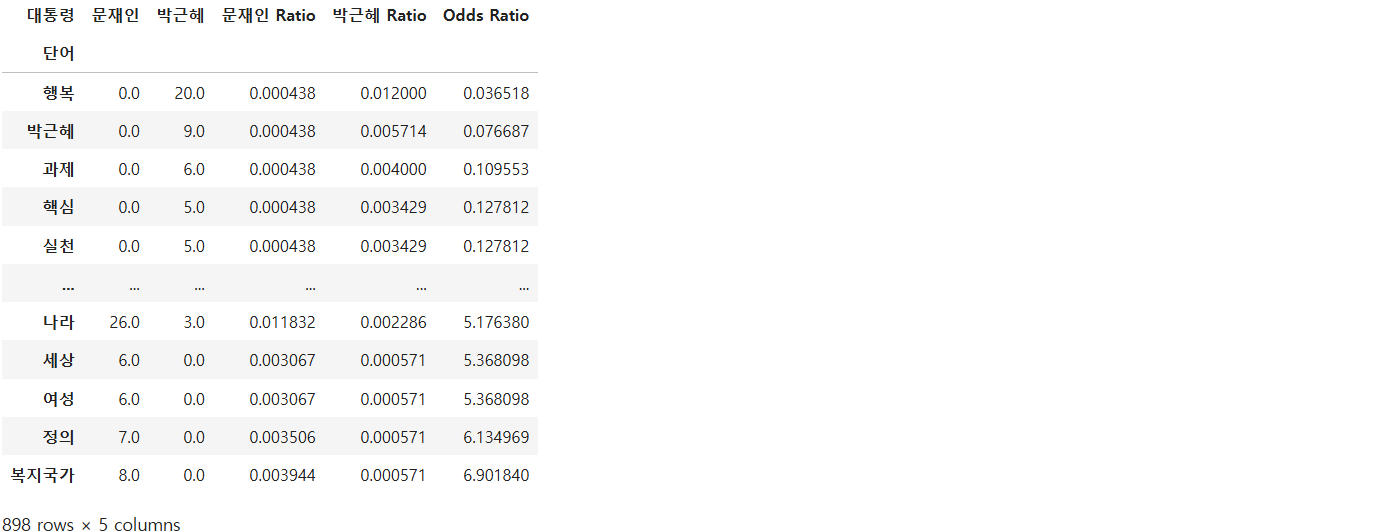
# 박근혜 : 행복
# 문재인 : 복지국가
# 연설문에서 해당하는 부분 보기
for i in kkma.sentences(park):
if '행복' in i:
print(i)
print(' ')
for i in kkma.sentences(moon):
if '복지국가' in i:
print(i)
퀴즈 : 이명박 대통령이 다른 대통령에 비해 많이 나온 단어 10개를 찾아보세요
total = []
df = pd.read_csv('speeches_presidents.csv')
for i in range(len(df)):
a = df.iloc[i]
president = a['president']
text = okt.nouns(a['value'])
box = []
for j in text:
if len(j) >= 2:
box.append(j)
counter = Counter(box).most_common()
sample = pd.DataFrame(counter, columns = ['단어', '빈도'])
if president == '이명박':
sample['대통령'] = '이명박'
else:
sample['대통령'] = '그 외'
total.append(sample)
df = pd.concat(total, ignore_index = True)
df2 = df.pivot_table(index = '단어', columns = '대통령', values = '빈도').fillna(0)
df2['그 외 Ratio'] = (df2['그 외'] + 1) / sum(df2['그 외'] + 1)
df2['이명박 Ratio'] = (df2['이명박'] + 1) / sum(df2['이명박'] + 1)
df2['Odds Ratio'] = df2['이명박 Ratio'] / df2['그 외 Ratio']
df2.sort_values('Odds Ratio', ascending = False)# 로그 변환함으로써, 오즈비의 비율을 대칭적으로 다룰 수 있다.
# 오즈비를 로그 변환하여 데이터의 분포를 더 대칭적으로 표현할 수 있음.
df2['Log Odds Ratio'] = np.log(df2['Odds Ratio'])
df2 = df2.sort_values('Log Odds Ratio', ascending = False)
# 상위 10개와 하위 10개 값을 각각 추출
a = df2.head(10)
b = df2.tail(10)
df3 = pd.concat([a, b])
# 상위 10개의 로그 오즈비 값을 수평 막대그래프로 시각화
plt.barh(a.index, a['Log Odds Ratio'], color = 'red', label = '이명박')
# 하위 10개의 로그 오즈비 값을 수평 막대그래프로 시각화
plt.barh(b.index, b['Log Odds Ratio'], color = 'blue', label = '그 외')
plt.grid(axis = 'x')
plt.legend()
plt.show()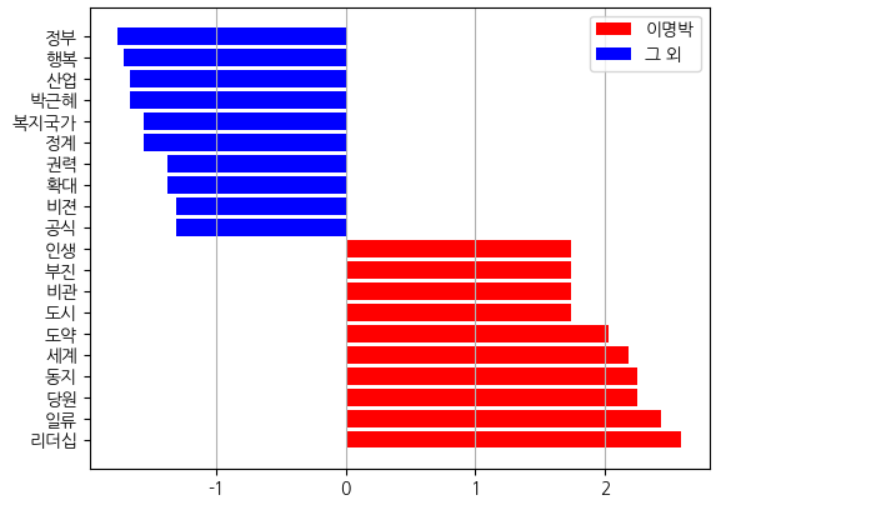
대통령 연설문에서 TF-IDF 분석을 통한 단어 중요도 평가
각 대통령의 연설문에서 단어의 출현 빈도(TF)와 역문서 빈도(IDF)를 사용하여 단어의 중요성을 평가
명사 추출 함수
okt = Okt()
# 명사 추출 함수
def make_nouns(x):
nouns = okt.nouns(x)
box = []
for i in nouns:
if len(i) >= 2:
box.append(i)
return box
df = pd.read_csv('speeches_presidents.csv')
df['value_nouns'] = df['value'].apply(make_nouns)
df
DF : 단어가 몇 개의 문서(대통령)에 출현했는지 구하기
unique_words = set()
for i in df['value_nouns']:
for j in i:
unique_words.add(j) # 중복 없이 고유한 단어만 넣기
# DF : 단어가 몇 개의 문서(대통령)에 출현했는지 구하기
DF_dic = {}
for i in unique_words:
count = 0
for j in df['value_nouns']: # 4명이라 4개의 데이터가 순차적으로 들어감
if i in j: # 단어가 연설문에 존재한다면
count += 1 # count + 1
DF_dic[i] = count
DF_dic
각 단어의 중요성을 평가하기 위해 TF-IDF(Term Frequency-Inverse Document Frequency) 값을 계산
df2 = df.explode('value_nouns')[['president', 'value_nouns']] # 데이터를 개별 행으로 분리
# 각 대통령과 각 단어의 조합을 기준으로 데이터를 묶고 행의 수를 계산한 다음 새로운 열의 이름을 TF(Term Frequency)로 지정
df3 = df2.groupby(['president', 'value_nouns']).size().reset_index(name = 'TF') # TF는 단어 출현빈도 (각 대통령과 단어 조합의 출현 빈도를 계산)
# 주어진 단어가 몇 개의 문서(대통령 연설문)에 출현했는지를 반환
def make_DF(x):
return DF_dic[x]
df3['DF'] = df3['value_nouns'].apply(make_DF)
# IDF : 총 문서 / DF = 4 / DF
df3['IDF'] = 4 / df3['DF']
df3['TF-IDF'] = df3['TF'] * df3['IDF'] # TF-IDF 값이 높을수록 해당 단어는 특정 문서에서 더 중요함.
df3[df3['president'] == '문재인'].sort_values('TF-IDF', ascending = False)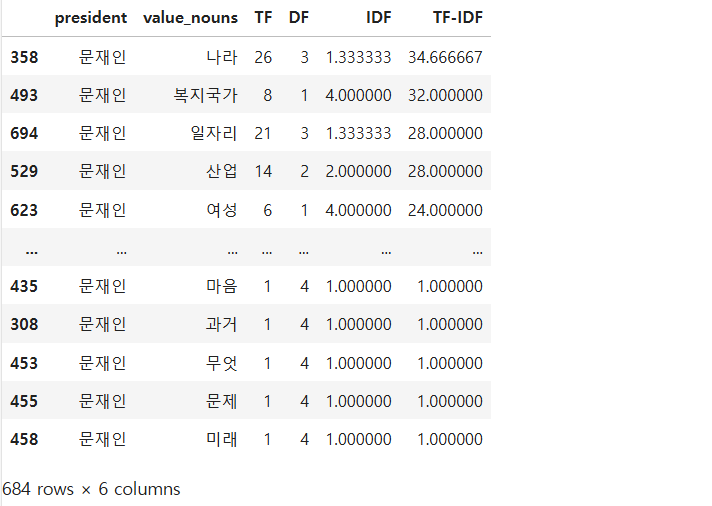
- DF : 단어가 출현한 문서의 수
- IDF : 총 문서 수를 DF로 나눈 값. 특정 단어가 전체 문서에서 얼마나 희귀한지를 측정.
- TF-IDF : 단어의 중요도를 나타내는 값으로, 특정 문서에서 그 단어가 얼마나 중요한지 나타냄.
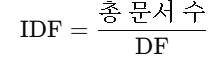
DF가 높을수록 IDF는 낮아짐

현재 대통령의 연설문에서 가장 중요한 단어(즉, TF-IDF 값이 가장 높은 단어) 5개를 출력
→ TfidfVectorizer를 사용하여 각 대통령의 연설문에서 추출한 명사들의 TF-IDF 값을 계산
TfidfVectorizer : 텍스트 데이터를 수치형 데이터로 변환해 주는 도구로, 각 단어의 TF-IDF 값을 계산
TF-IDF는 단어 빈도(TF)와 역문서 빈도(IDF)를 곱한 값으로,
특정 단어가 문서 내에서 얼마나 중요한지를 평가하는 데 사용함
from sklearn.feature_extraction.text import TfidfVectorizer
model = TfidfVectorizer()
# value_nouns 열의 각 리스트(명사들)를 공백으로 구분된 문자열로 변환하여 새로운 열 cb_nouns에 저장
df['cb_nouns'] = df['value_nouns'].apply(lambda x : ' '.join(x))
# cb_nouns 열에 있는 문자열을 기반으로 TF-IDF 값을 계산
tf_idf = model.fit_transform(df['cb_nouns'])
# 행은 각 대통령의 연설문을 나타내고, 열은 각 명사로
result = pd.DataFrame(tf_idf.toarray(),
index = df['president'],
columns = model.get_feature_names_out())
# TF-IDF 벡터화 과정에서 사용된 모든 명사(단어)의 목록을 가져오기
columns = model.get_feature_names_out()
for i in range(len(result)):
a = result.iloc[i]
idx = np.argsort(a)[-5:] # TF-IDF 값이 가장 높은 5개의 인덱스를 선택
print(columns[idx])
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 주식 포트폴리오 분석을 위한 시뮬레이션 - 몬테카를로 시뮬레이션, 샤프지수, KOSPI 통계분석, 종목간 상관관계, 최대 낙폭, 할로윈 투자 전략 (2) | 2024.10.21 |
|---|---|
| 금융 데이터 전처리 (주식 데이터월별, 분기별, 주별 데이터 집계, 거래량 변화 탐지, 모멘텀 전략 및 수익률 계산, 볼린저 밴드) (1) | 2024.10.21 |
| 자연어 처리(NLP) - 감성분석, OpenAI (6) | 2024.10.11 |
| 자연어 처리 - 소문자 변환, 토큰화, 빈도 분석 (7) | 2024.10.10 |
| 영화 추천 시스템, 동적 크롤링 (4) | 2024.10.02 |



