11. 파일과 예외처리
파일 열고 닫기
open(파일 이름, 파일 모드)
파일객체.close()
- "r" : 읽기 모드
- "w" : 쓰기 모드
- "a" : 추가 모드 (append mode)
- "r+" : 읽기와 쓰기 모드
f.close() : 메모리에 있는 거 파일에 flash 해주는 명령어
# 파일에 써보기
outfile = open("output.txt", "w", encoding = "utf-8")
outfile.write("김영희\n")
outfile.close() # 파일 닫기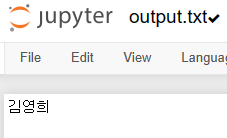
-> 파일에 쓸 때 write 명령어를 쓸 수 있고, print 명령어를 쓸 수도 있다.
outfile.write("김영희\n")와 print("김영희", file=outfile)는 동일하다.
# print문으로 파일에 쓰기
outfile = open("output.txt", "w", encoding = "utf-8")
print("print명령어로 출력한 내용\n", file=outfile)
outfile.close()
단어 입출력 방법
- for line in file: 처럼 for문 쓰기
- line.split() : 단어들로 분리
- infile.read() : 파일 전체 내용이 하나의 문자열로 저장
- infile.readlines() : 각 줄이 문자열로 저장
- infile.read(1) : 문자 단위로 읽기
한글 같은 경우 문자 인코딩 필요
encoding = "utf-8" 추가 : 각 문자를 1개에서 4개의 바이트로 인코딩
# 각 문자 횟수 세는 코드를 단어의 빈도수 출력으로 변경
filename = input("파일명을 입력하세요: ").strip()
infile = open(filename, "r") # 파일을 연다.
freqs = {}
# 파일의 각 줄에 대하여 문자를 추출한다. 각 문자를 사전에 추가한다.
for line in infile:
for char in line.split(): # split() 사용
if char in freqs: # 문자열 안의 각 문자에 대하여
freqs[char] += 1 # 딕셔너리의 횟수를 증가한다.
else: # 처음 나온 문자이면
freqs[char] = 1 # 딕셔너리의 횟수를 1로 초기화한다.
print(sorted(freqs.items(), key=lambda x:x[1], reverse=True))
infile.close()
파일에서 읽어오기
# 파일과 예외처리
# 파일에서 임의의 행을 읽는 프로그래밍 (첫번째 행의 번호는 0이라 가정)
fname = input("파일 이름을 입력 : ").strip()
n = int(input("행 번호를 입력 : "))
file = open(fname, "r")
for _ in range(n):
line = file.readline()
line.strip()
print(f"{n}번 행은 {line} 입니다.")
# 제일 긴 단어 찾기
fname = input("파일 이름을 입력 : ").strip()
infile = open(fname, "r")
maxLength = 0
for line in infile:
for word in line.split():
if len(word) > maxLength:
longest = word
maxLength = len(word)
print(f"가장 긴 단어는 {longest} 입니다.")
파일에 써보기
# "numbers.txt" 파일을 열어서 0부터 100 사이의 난수 10개를 추가하는 파일 작성
import random
f = open("numbers.txt", "w", encoding = "utf-8")
for _ in range(10):
print(random.randint(0, 100), file=f)
f.close()
# 학생들의 성적이 파일 number.txt에 저장되어 있다.
# 이 성적을 받아서 파일의 끝에 평균값 추가
f = open("numbers.txt", "r+", encoding = "utf-8") # 읽기쓰기모드
total = 0
count = 0
for line in f:
total += int(line)
count += 1
print(f"\n평균성적 : {total/count}", file = f)
f.close()
# 3번행 최저온도, 4번행 최고온도 일 때 10년치 날씨 중 최저 온도, 최고 온도 출력
import csv
f = open("대구기온.csv")
data = csv.reader(f)
next(data)
maxt = 0
mint = 100
for row in data:
if row[3] == "" or row[4] == "":
continue
t3 = float(row[3])
t4 = float(row[4])
if t3 < mint:
mint = t3
mindate = row[0]
if t4 > maxt:
maxt = t4
maxdate = row[0]
print(f"최고 온도 = {maxt}, 날짜 = {maxdate}")
print(f"최저 온도 = {mint}, 날짜 = {mindate}")
f.close()
# 각 시/군별로 20대, 30대, 60대, 70대 비율 출력
import csv
f = open("경북인구.csv")
data = csv.reader(f)
next(data)
S = {}
for row in data:
city = row[0].split()[2]
total = float("".join(row[1].split(",")))
a20 = float("".join(row[4].split(",")))
a30 = float("".join(row[5].split(",")))
a60 = float("".join(row[8].split(",")))
a70 = float("".join(row[9].split(",")))
# 각 시/군별로 20대, 30대, 60대, 70대 비율을 딕셔너리에 저장
S[city] = (a20 / total, a30 / total, a60 / total, a70 / total)
# 각 시/군별로 20대 비율을 기준으로 내림차순 정렬
slist = sorted(S.items(), key=lambda x: x[1][0], reverse=True)
# 결과 출력
for x in slist:
print(f"{x[0]} : {x[1]}")
# 전체 딕셔너리 출력
print(S)
디렉토리 작업
- os.getcwd() : 작업 디렉토리 얻기
- os.chdir(subdir) : 작업 디렉토리 변경
- listdir() : 작업 디렉토리 안에 있는 파일들의 리스트 얻기
- isfile() : 파일만 처리
# 현재 폴더 밑에 tmp폴더를 생성하고, 이 폴더로 이동하라.
# os.mkdir("폴더명") os.chdir("폴더명")
# tmp 폴더에 A.txt, B.txt,..., Z.txt 까지의 26개의 텍스트 파일 생성 후 해당 파일을 이름을 파일에 write
import os
os.mkdir("tmp")
os.chdir("tmp")
os.getcwd()
for x in range(26):
fname = chr(ord('A') + x) + ".txt"
f = open(fname, "w")
print(fname, file=f)
f.close()


# 사용자 ID와 패스워드를 입력받아, "id:패스워드" 형태로 login.txt에 저장
# 패스워드 입력 : p1 = getpass.getpass(prompt = "암호등록!") (import getpass 선언)
# 패스워드는 암호회된 형태로 파일에 저장
# encrypted = hashlib.sha256(p1.encode().hexdigest()) (import hashlib 선언)
import getpass
import hashlib
uid = input("사용자 id? ")
p1 = getpass.getpass(prompt="암호? ")
f = open("login.txt", "a")
encrypted = hashlib.sha256(p1.encode()).hexdigest()
print(f"{uid} : {encrypted}", file = f)
f.close()
# 사용자 ID와 패스워드를 입력받아 암호가 옳은지 틀린지 확인
import getpass
import hashlib
uid = input("로그인 id: ")
cpwd = getpass.getpass("password: ")
encrypted = hashlib.sha256(cpwd.encode()).hexdigest()
f = open("login.txt", "r")
for line in f:
key, value = line.strip().split(":")
if key == uid:
if encrypted == value:
print("등록된 사용자입니다.")
else:
print("잘못된 암호입니다.")
break
else:
print("등록되지 않은 id입니다.")
이진 파일에서 읽기
이진 파일에서 데이터를 읽으려면 open(filename, "rb") 형태
단일 바이트들은 immutable sequence
bytes 객체에 대응되는 mutable 객체
-2^31 ~ 2^31-1 까지가 integer로 표현 가능한 바이트수인데
파일의 내용을 바이너리로 써버리면 4byte로 쓸 수 있다.
이진표현으로 바꿔서 압축적으로 저장할 수 있다.
순차 접근 파일이 아닌 임의 접근 파일인 경우 seek 사용
읽을때 마다 파일 포인터가 증가
seek는 파일포인터 특정 위치로 이동하게 해주는 명령어
tell 에서는 파일 포인터의 현재 위치 알려줌
임의 접근
- file.seek(n) : 파일의 시작에서 n 바이트 이동
- file.seek(n, os.SEEK_CUR) : 현재 위치에서 n 바이트 이동
- file.seek(n, os.SEEK_END) : 마지막에서 n 바이트 이동
- file.tell() : 파일 포인터의 현재 위치를 알려준다.
객체 입출력
pickle 모듈
: 사전의 내용을 파일에 쓰고 싶을 때 사용
-> dictionary나 list와 같은 객체를 파일에 저장하고 다시 읽어서 메모리 객체에 저장하고 싶을 때 사용
import pickle 로 선언 후
dump(), load() 메소드로 객체를 쓰고 읽음
# 1부터 100 사이의 난수 10개를 저장한 리스트 A를 생성
# pf.dat파일에서 리스트를 읽어 B에 저장후 A와 B같은지 확인
import random
import pickle
A = random.sample(range(1, 101), 10)
print(A)
f = open("pd.dat", "wb") # dat는 바이너리 파일
pickle.dump(A, f)
f.close()f = open("pd.dat", "rb")
B = pickle.load(f)
print(B)
f.close()
****아래 코드 뭔지 정리**
import random
import pickle
A = random.sample(range(1, 101), 10)
print(A)
f = open("pd.dat", "wb") # dat는 바이너리 파일
pickle.dump(A, f)
f.close()
def dump(fname, container):
file = open(fname, "ab")
pickle.dump(container, file)
file.close()
D = {"김영수":72, "박진석":95, "이철수":80}
dump("pd.dat", D)
T = tuple("안녕하세요. 날씨가 좋습니다.")
dump("pd.dat", 1)
S = [1, 3, 5, 7, 8]
dump("pd.dat", S)
f = open("pd.dat", "rb")
try:
A=[]
while True:
A.append(pickle.load(f))
except EOFError:
f.close()
print(A)
# GUI에서 실습하였던 사용자 등록 프로그램을 아래와 같이 개선
# "파일에 저장" 버튼을 누르면 입력한 내용을 이용하여 {이름:(직업,나이)} 형태 사전 생성 후
# 이를 user.dat 파일에 pickle 객체로 append
# "파일 내용 출력" 버튼을 누르면 user.dat 파일에 저장된 모든 사전 객체들을 load하여 print
# pickle.load()를 EOFError 오류 발생할 때 까지 실행
from tkinter import *
import pickle
def save():
f = open("user.dat", "ab")
D = {}
name = entries[0].get()
job = entries[1].get()
age = entries[2].get()
D[name] = (job, age)
pickle.dump(D, f)
f.close()
reset()
def reset():
for x in range(3):
entries[x].delete(0, END)
entries[0].focus_set()
def display():
f = open("user.dat", "rb")
A = []
try:
while True:
A.append(pickle.load(f))
except EOFError:
f.close()
print(A)
window = Tk()
labels = ['이름', '직업', '나이']
entries = []
for x in range(3):
Label(window, text=labels[x]).grid(row=x, column=0)
entries.append(Entry(window))
entries[x].grid(row=x, column=1)
frame = Frame(window)
frame.grid(row=3, column=0, columnspan=2)
Button(frame, text="파일에 저장", command=save).pack(side=LEFT)
Button(frame, text="다시 입력", command=reset).pack(side=LEFT)
Button(frame, text="파일에 출력", command=display).pack(side=LEFT)
window.mainloop()

정규식 (regular expression)
: 문자열 처리하는 모듈

RE를 이용한 tokenizing
re.split(pattern, string) : 단어로 나뉘게 됨
예외처리
try-except 구조
- IOError : 파일을 열 수 없으면 발생한다.
- importError : 파이썬이 모듈을 찾을 수 없으면 발생한다.
- ValueError : 연산이나 내장 함수에서 인수가 적절치 않은 값을 가지고 있으면 발생한다.
- KeyboardInterrupt : 사용자가 인터럽트 키를 누르면 발생한다. (Control-C나 Delete)
- EOFError : 내장 함수가 파일의 끝을 만나면 발생한다.
- IndexError : list index out of range
내장함수(Built-in Function)
- abs() : 절대값 반환
- all() : 리스트를 주고 all을하면 리스트의 모든 항목이 참이면 True, 하나라도 참이 아니면 False
- eval() : 문자열로 수식을 주면 수식을 계산
- sum() : 인자가 두개면 리스트의 합 계산(set, tuple, dictionary의 key 에서도 가능)
- len() : 문자, 리스트의 길이를 알려줌
- list() : 리스트 생성
- map(funtion, iterable) : 리스트(iterable)의 원소 각각에 함수(function)를 적용 -> list(map()) 으로 리스트로 출력
- dir() : 객체가 사용할 수 있는 모든 메소드가 나옴
- enumerate() : 열거형 값의 쌍을 반환
- filter(fuction, iterable) : 리스트의 각각의 원소를 함수에 적용해 True인 것만 넘겨줌
- zip() : 2개의 원소를 하나로 묶어줌
문자열을 정수로 반환하는 방법
- a, b, c = map(int, input("정수? ").split())
- a, b, c = [int(x) for x in input("정수? ").split()]
# 양의 정수 n을 입력 받은 다음, 1부터 n까지의 정수 중에서 3의 배수의 개수를 출력
# len() 함수와 리스트 함축을 이용하여 프로그래밍
# sum() 함수와 리스트 함축을 이용하여 프로그래밍
n = int(input("양의 정수를 입력하세요 : "))
len([x for x in range(1, 101) if x % 3 == 0])
sum([1 for x in range(1, 101) if x % 3 == 0])
# 내장함수 eval() 함수를 사용하여 정수가 실수 인지 실수 인지 구분하여라
# eval의 결과가 정수면 int로 만들어주고 실수면 float로 반환
x = eval(input("정수나 실수를 입력 : "))
print(x, type(x))
# map()을 이용하여 입력받은 리스트의 원소들을 제곱한 값을 원소로 갖는
# 새로운 리스트를 반환하는 함수 squareList(input_list) 프로그래밍
def square(x):
return x * x
def squareList(L):
return list(map(square, L))
l1 = list(range(1, 10))
l2 = list(range(1, 50, 5))
print(squareList(l1))
print(squareList(l2))
# map()과 filter()을 사용하여 입력받은 리스트의 원소 중에서
# 짝수 값들을 제곱한 값을 원소로 갖는 새로운 리스트 반환하는 함수 squareEvenList(list) 프로그래밍
def even(x):
return x % 2 == 0
def squareEvenList(L):
return list(map(square, filter(even,L)))
l1 = list(range(1, 10))
l2 = list(range(1, 50, 5))
print(squareEvenList(l1))
print(squareEvenList(l2))
람다식 (Lambda Expressions)
: 이름은 없고 몸체만 있는 함수 (lambda 키워드를 사용하는 일회용 함수)
람다함수는 함수를 한줄로 표현한것이다 lambda 매개변수:리턴값
key 매개변수
정렬을 하다보면 정렬에 사용되는 키를 개발자가 변경해줘야 하는 경우 있다.
# 학번과 이름, 학점 속성을 갖는 학생 클래스를 선언하고 아래와 같이 3명의 학생을 포함하는 리스트 생성
# 이후, 각 속성에 대해 정렬한 결과를 출력하는 프로그래밍
class Student:
def __init__(self, sid, name, grade):
self.sid = sid
self.name = name
self.grade = grade
def __repr__(self):
return f"({self.sid}, {self.name}, {self.grade})"
def getId(s):
return s.sid
def getName(s):
return s.name
def getGrade(s):
return s.grade
s1 = Student(20152041, "kim", 3.7)
s2 = Student(20171132, "ahn", 3.2)
s3 = Student(220191234, "cho", 3.3)
li = [s1, s2, s3]
print(sorted(li, key=getId))
print(sorted(li, key=getName))
print(sorted(li, key=getGrade, reverse=True))
위 예제 squareEvenList를 Lambda를 사용해서 수정
# map()과 filter()을 사용하여 입력받은 리스트의 원소 중에서
# 짝수 값들을 제곱한 값을 원소로 갖는 새로운 리스트 반환하는 함수 squareEvenList(list) 프로그래밍
def squareEvenList(L):
return list(map(square, filter(lambda y : y%2 == 0, L)))
l1 = list(range(1, 10))
l2 = list(range(1, 50, 5))
print(squareEvenList(l1))
print(squareEvenList(l2))
# 뒤에꺼 기준으로 젤 큰 값 찾기
max([(1,5), (3,2), (5,10), (7,8), (9,4)], key = lambda x: x[1])
# 학생 이름과 수학, 영어 점수가 아래와 같이 리스트에 저장되어 있다.
# zip, max, min 함수 등을 사용하여 수학과 영어의 최고 점수와 최저 점수를 받은 학생 이름 출력
students = ["kim", "lee", "park", "ahn", "cho"]
math = [70, 80, 83, 67, 77]
eng = [95, 88, 90, 91, 92]
A = list(zip(students, math, eng))
print(A)
print(f"수학 최고 점수 = {max(A, key = lambda x: x[1])[0]}")
print(f"수학 최저 점수 = {min(A, key = lambda x: x[1])[0]}")
print(f"영어 최고 점수 = {max(A, key = lambda x: x[2])[0]}")
print(f"영어 최저 점수 = {min(A, key = lambda x: x[2])[0]}")
********** 아래코드 분석해보기****
A = [("국어", 97), ("영어", 87), ("수학", 71), ("과학", 70), ("한국사", 78)]
print(sorted(A, key=lambda x:x[0]))
print(sorted(A, key=lambda x:x[1]))
print(sorted(A, key=lambda x:x[1] , reverse=True))
이터레이터와 제너레이터
이터레이터 (Iterator)
: iter() , __next__() 함수 사용
next()를 호출해 for문 처럼 사용 가능
제너레이터 (Generator)
: 값을 리턴하는 것이 아니라 yield 하여 하나씩 꺼내는 것
return은 함수가 종료 되면 잊어버리지만 yeild는 함수를 기억
+ next() 함수를 이용하여 호출 가능
# MyEnumerate라는 iterator를 구현하는 클래스 작성
# 튜플의 첫번째 요소는 0으로 시작하는 인덱스이고,
# 두번째 요소는 주어진 자료구조의 현재 요소
# 각 반복마다 튜플을 반복
class MyEnumerater:
def __init__(self, seq):
self.counter = 0
self.seq = seq
def __iter__(self):
return self
def __next__(self):
if self.counter >= len(self.seq): # 끝나는 조건
raise StopIteration
item = self.seq[self.counter]
self.counter += 1
return self.counter - 1, item
for index, letter in MyEnumerater('abc'):
print(f"{index} : {letter}")
************ 아래코드 오류 수정**********
아래 이터레이터
# start <= x <= stop 인 소수(prime number) x를 차례대로 생성하는 iterator PrimeNumbers(start, stop) 작성
import math
class PrimeNumbers:
def is_Prime(self,n):
if n == 2:
return True
if n <= 1 or n % 2 ==0:
return False
for x in range(3, n//2 +1,2):
if n% x == 0:
return False
else:
return True
def __init__(self, start, stop):
self.current = start
self.stop = stop
def __iter__(self):
return self
def __next__(self):
while not is_prime(self.current):
self.current += 1
if self.current > self.stop:
raise Stopiteration
self.current += 1
return self.current - 1
for x in PrimeNumbers(1, 100):
print(x, end="")
아래 제너레이터
def isPrime(self,n):
if n == 2:
return True
if n <= 1 or n % 2 ==0:
return False
for x in range(3, n//2 +1,2):
if n% x == 0:
return False
else:
return True
def PrimeNumbers(start, stop):
current = start
while current < stop:
if is_prime(current):
yield current
current += 1
for x in PrimeNumbers(1, 100):
print(x, end =" ")아래 정상 동작 코드
class PrimeNumbers():
def __init__(self,start, stop):
self.current = start
self.stop = stop
def __iter__(self):
return self
def __next__(self):
while True:
if self.current > self.stop:
raise StopIteration
self.current+= 1
if self.isPrime(self.current-1):
return self.current - 1
def isPrime(self,n):
if n == 2:
return True
if n <= 1 or n % 2 ==0:
return False
for x in range(3, n//2 +1,2):
if n% x == 0:
return False
else:
return True
for x in PrimeNumbers(1, 100):
print(x, end =" ")
모듈
: 함수나 변수 또는 클래스 들을 모아 놓은 파일
copy 모듈
- 얇은 복사(shallow copy) : 객체의 참조값만 복사되고 객체 자체는 복사되지 x
- 깊은 복사(deep copy) : 객체까지 복사
sys 모듈
파있너 인터프리터(설치 경로, 참조 경로, 버전 등)에 대한 정보 참조시 사용
- sys.exit : 인터프리터 종료
- sys.path: 참조 경로 출력
- sys.version: 설치된 파이썬의 버전
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 6일차 - 다양한 Numpy 관련 기초 내용 및 Numpy를 활용한 기상데이터 분석 학습 (1) | 2024.01.11 |
|---|---|
| 5일차 - MySQL, pymysql, tkinter와 pymysql 연동, 기상청 데이터 분석, 인구 현황 분석 (1) | 2024.01.10 |
| 3일차 - 객체와 클래스, 상속, tkinter를 이용한 GUI 프로그래밍 (3) | 2024.01.08 |
| 2일차 파이썬 - 리스트, 튜플, 집합, 사전, 문자열 (1) | 2024.01.05 |
| 1일차 파이썬 - 입력과 출력, 변수와 수식, 조건문, 반복문, 함수 (4) | 2024.01.04 |



