Numpy 배열 (ndarray)
import numpy as np 선언
np.array()
: 리스트로 numpy 배열 만들기 가능

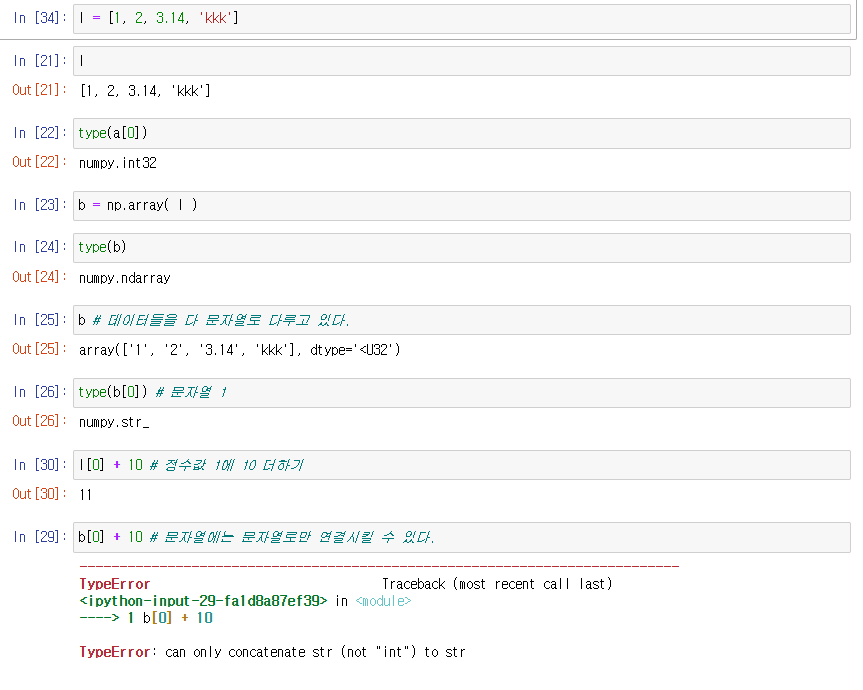
numpy 배열은 데이터들을 다 문자열로 다루고 있다.
- 배열안에 데이터타입이 여러개일때 각 배열안의 타입을 str로 통일 시킨다. => str로 된다면 연산이 불가능하기 때문에 주의가 필요하다.
- 배열안에 데이터타입이 모두 같다면 각 배열은 해당 데이터 타입을 사용한다.
np.zeros()
: 0 으로 채워진 numpy 배열 만들기
튜플 형태로 원하는 차원으로 만들기 가능

shift + Tab을 눌러주면 해당 함수의 사용법 매개변수등을 보여준다
단위 행렬
- np.eye() : k 값을 조절하여 대각 성분 1의 위치 바꿀 수 있음
- np.identity() : 대각 성분이 1 일때 사용
- np.full() : 채워줄 값을 지정할 수 있음



데이터를 저장하는데 데이터를 저장하는 곳은 메모리 (엄청 긴 일차원 배열)
컴퓨터의 모든 데이터는 0,1 의 비트로 메모리에 저장됨
저장된 데이터를 8bit씩 묶어서 한 개의 단위로 봄 -> 1byte
이 메모리의 원하는 곳에 데이터를 넣고 싶은 경우가 생겨 0, 1, 2, .. 로 번호를 붙임 -> 메모리의 주소
주소를 가리키고 있는 것이 변수
2차원 배열, 3차원 배열
3행 2열 같은 경우 메모리는 일차원 배열인데 어떻게 저장?
| 10 | 20 |
| 30 | 40 |
| 50 | 60 |
행을 기준으로 저장할 경우 10 20 30 40 50 순서로 넣기 -> row major -> c언어, c++ 등
열을 기준으로 저장할 경우 10 30 50 20 40 60 순서로 넣기 -> column major -> Fortran 등
numpy 경우 둘 다 할 수 있지만 기본은 'C'
np.empty()
: 배열을 만들때 데이터를 초기화 하지 않고 크기만 만들어 줄때 empty를 사용
원래 메모리 공간에 위치를 잡고 변수를 줘서 채우는데 empty는 채우지 않겠다는 것
백만개의 데이터로 배열 만들 때 굳이 0으로 채우고 덮어쓰기 번거로워 공간만 만들고 초기화 x

like
모양이 똑같은 배열을 제작 like는 값이 아닌 모양(shape)만 가져온다

np.arange()
range()는 실수값을 사용하여 sequence 싶을 때 안됨 -> 파라미터로 정수값만 올 수 있음
np.arange()는 실수값 범위의 sequence 만들기 가능

등간격으로 데이터를 나누기
: linspace(start, stop, 개수)
start에서 stop 까지 개수로 나누기

logspace()로 나눌 수도 있다.

ndarray 속성

astype()
: 정수형으로 만들고 다시 실수형으로 만든 경우 생각
astype()함수는 a자체를 바꾸는게 아니라
a를 astype으로 변경후 리턴해주는 것이다 -> 변경되지 않는다.

ndim, size, itemsize

복사 (Copy) - 얕은 복사, 깊은 복사
메모리의 배열을 복사한다고 생각한 경우
List b에 List a를 대입하여 복사한다고 생각했을 때 주소값을 복사해줌

but, 슬라이싱한 경우 별도의 메모리에 저장을 한 후 참조하여 a는 바뀌지 않는다.

슬라이싱하여 list_d를 list_a에 대입한 경우
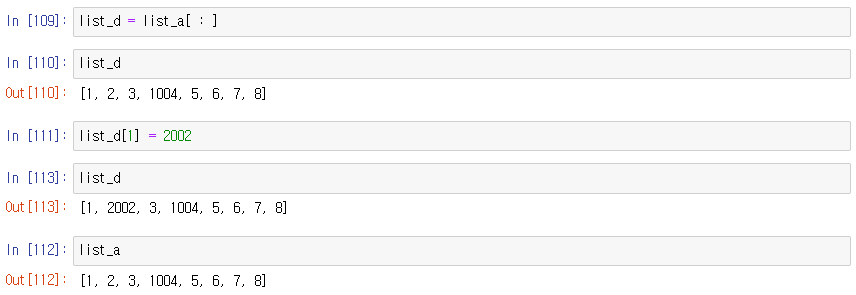
copy() 메소드를 사용 하면 슬라이싱을 하지 않고도 값만 복사 가능 -> 얕은 복사

단, 문제 발생
copy는 첫번째 []에 대해서만 copy진행하고 [] 내부에 있는 []는 copy진행하지 않았다.
-> 내부에 list들이 공유되었다.

한 번에 다 해결하고 싶은 경우 -> 깊은 복사 (deep copy)
깊은 복사 (deep copy)
import copy 선언
copy.deepcopy() 메소드 사용

ndarray에서의 복사
파이썬의 리스트는 슬라이싱하면 원래의 리스트와 연관 없다.
단, ndarray에서는 슬라이싱해도 데이터를 같이 공유하게 된다.(id는 다르다.)
-> View가 생성된다.
즉, view + 일반적인경우 슬라이싱을 하게되면 새로운 객체가 만들어지지만 ,
numpy의 경우는 view가 생성되고 b를 고치면 a도 고쳐진다.
numpy는 아주 큰 빅데이터라 데이터의 양이 엄청 많은데 한 번에 가져오려니까 데이터가 너무 많음
import copy 후 copy와 view는 새로운 객체가 생기는지에 대해 차이가 존재한다.
공유가 아니라 별도로 복사하고 싶을 때

view를 사용하는 이유 : shape과 data_type을 바꾸고 사용하기에 유리하기 때문
ndarray에서 값을 가져오는 방법
배열의 모양 바꾸고 싶을 때
a.reshape() 함수 사용

원소의 개수를 넘어서면 reshape 불가능 -> a.reshape( (3,-1) ) 같이 -1을 써서 알아서 하게함

값을 가져오기

Boolean Indexing
boolean 인덱싱은 값으로 하는 것이 아닌 boolean 값의 리스트로 함

비교 연산해보기

-> numpy의 배열 ndarray 는 비교 연산 가능
-> elementwise operation, broadcasting
: 각각의 요소별로 연산
vector와 scalar의 연산은 원래 불가능하지만 numpy 배열에서는 가능하다.
5보다 크거나 같고 9보다 작은 값 비교 연산

배열 값 중에서 짝수만 선택하여 2배한 다음 새로운 배열에 저장

Fancy Indexing
: 원하는 행을 적어 특정한 행을 선택하는 것

특정 열만 선택

특정한 영역만 선택


Vectorized Operation (벡터화 연산)
- elementwise operation

- elementwise 곱하기
- matrix dot operation, 행렬곱 -> 전치 행렬(행과 열의 위치 바꾸기)
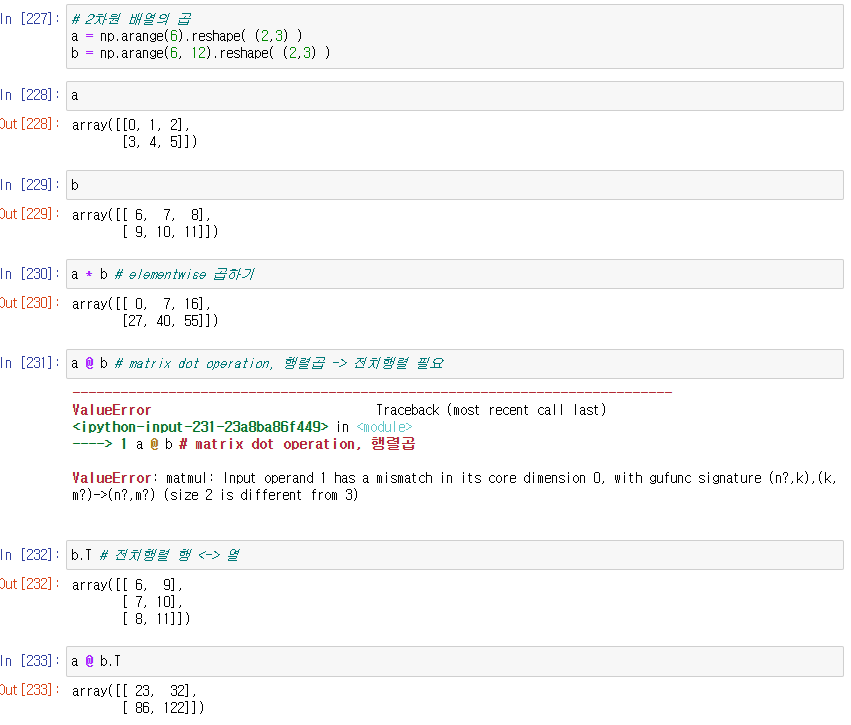
Broadcasting
- 배수가 맞아야 발생한다.
- array_name + 2 도 마찬가지로 내부적으로 Broadcasting 되어 array_name의 행렬 형태로 만들어 계산

축(axis)

행, 열 각각의 가장 큰 값 구하기

Universal Function : ufunc
벡터화 연산을 지원하는 함수
- function python에서 지원함
- ufunc 은 numpy에서 지원함
ufunc는 사용자가 만들 수 있다.

np.where(조건, 참일때값, 거짓일때값)


난수 생성
- rand() : 균등분포 (0~1)
- randn() : 표준정규분포, 표준 편차가 1이고 평균이 0인 값으로 만들어줌 (대체로 -1 ~ 1)
- randint() : 정수 [ low ~ high ) (high는 포함 x)
- shuffle() : 섞는다
- choice() : 랜덤하게 선택한다

numpy 배열로 난수 생성

Resize

- reshape : 데이터 소실 없이 모양만 바꾸기
- resize : 개수 자체를 바꾸기
파일 입출력
1부터 45까지 로또 번호 100개 생성하여 numpy 배열로

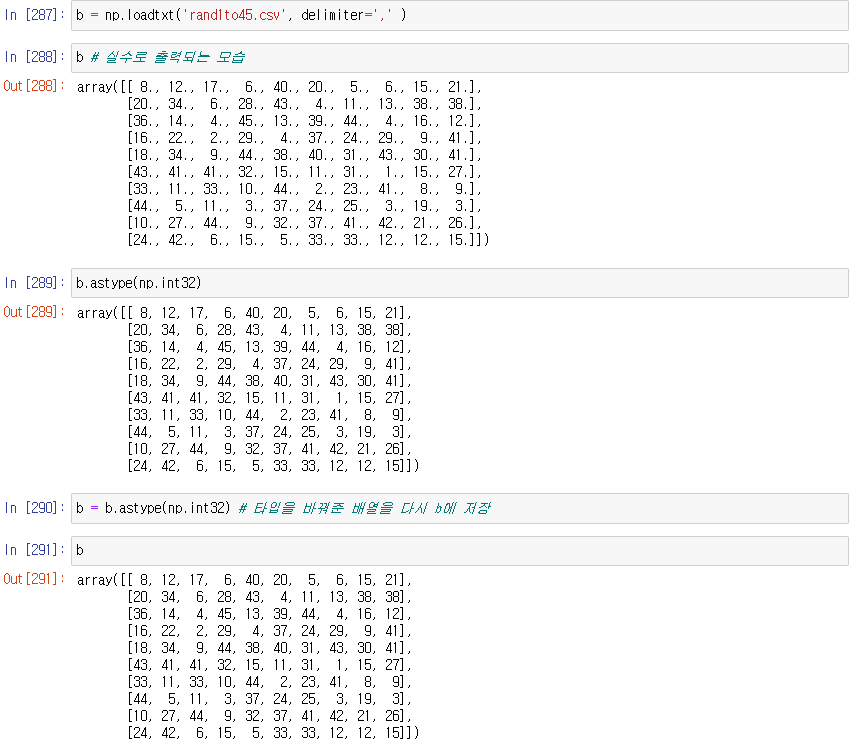

-> astype() 으로 타입 변경 가능
실습
1. 0~9까지 값을 가진 배열 a를 만들기

2. a에서 홀 수만 선택

3. a의 홀수 값만 -1로 변경

4. a의 모양을 (2.5)형태로 변경하고 b에 저장

5. b배열의 1번 열과 3번열의 위치를 바꿔서 c에 저장


6. b배열의 0번행과 1번행을 바꿔서 d에 저장하시오.

기상청 데이터를 분석
daeguTemp = np.loadtxt('daegu.csv', delimiter = ',')
daeguTemp.shape
1. 최고 기온은?
(1)
np.max(daeguTemp, axis=0)[4]
# 축을 행이 증가하는 방향으로 설정 -> 각각의 열의 최댓값을 구할 수 있다.
(2)
np.max(daeguTemp[:, 4]) # 4번 열만 선택
2. 최저 기온은?
np.min(daeguTemp[:, 3])
3. 최고 기온과 최저 기온은 언제인가?
(1) 최고 기온 날짜 구하기

(2) 최저 기온 날짜 구하기

4. 최저 기온, 최고 기온 Top 10 구하기
hint)
np.delete
예) a의 100번째 인덱스를 삭제하고 싶다.
a = np.delete(a, 100, axis=0)
def getTempTop10(tData, n=10):
# 최고, 최저 기온 저장할 수 있는 곳 사전으로 만들기 (key : 날짜, value : 온도)
highTempTop10 = {}
lowTempTop10 = {}
for i in range(n):
maxIndex = np.argmax(tData[: , 4])
highTemp = tData[maxIndex, 4] # 최고 기온 가져오기
highDay = tData[maxIndex, 0].astype(np.int32) # 최고 기온 날짜 가져오기
highTempTop10[highDay] = highTemp # 사전에 최고 온도 정보 저장
tData = np.delete(tData, maxIndex, axis=0)
minIndex = np.argmin(tData[ : , 3])
minTemp = tData[minIndex, 3] # 최저 기온 가져오기
minDay = tData[minIndex, 0].astype(np.int32) # 최저 기온 날짜 가져오기
lowTempTop10[minDay] = minTemp # 사전에 최저 온도 정보 저장
tData = np.delete(tData, minIndex, axis=0)
return highTempTop10, lowTempTop10
htop10, ltop10 = getTempTop10(daeguTemp)

5. 각 연도별 최고, 최저 기온을 구하기

def getYearStatistics(tData):
yStat={}
for year in range( int(tData[0, 0] // 10000), int(tData[-1, 0] // 10000 + 1)):
# range에 시작하는 연도와 끝나는 연도 넣기
condindex = tData[: , 0] // 10000 == year
yearData = tData[condindex] # 현재 보고싶은 연도의 데이터만 찾아짐
maxTemp = np.max(yearData[ : , 4 ])
minTemp = np.min(yearData[ : , 3 ])
yStat[year] = maxTemp, minTemp # 튜플로 yStat에 삽입
return yStat

'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 8일차 - 시계열 데이터를 위한 Pandas 응용 및 각종 데이터 시각화 기법 학습 및 실습 (1) | 2024.01.15 |
|---|---|
| 7일차 - Series, DataFrame 등과 함께 Pandas 학습 및 영화 캐스팅 정보를 활용한 실습 (0) | 2024.01.12 |
| 5일차 - MySQL, pymysql, tkinter와 pymysql 연동, 기상청 데이터 분석, 인구 현황 분석 (1) | 2024.01.10 |
| 4일차 - 파일과 예외처리, 내장함수, 람다식, 모듈, Top-K 텍스트 분석, CF기반 추천 시스템 (1) | 2024.01.09 |
| 3일차 - 객체와 클래스, 상속, tkinter를 이용한 GUI 프로그래밍 (2) | 2024.01.08 |



