뉴스기사 & 리뷰 (텍스트 데이터) 주가 예측
→ 뉴스 기사 수집
Selenium과 BeautifulSoup을 사용하여 네이버 뉴스에서 특정 키워드와 관련된 뉴스 기사를 수집
주식 키워드와 관련된 최신 뉴스 기사 제목 100개를 스크롤을 반복하면서 수집해, 리스트에 저장
# 필요한 라이브러리 임포트
import undetected_chromedriver as uc # 크롬 브라우저를 자동화하면서 탐지 방지 기능을 가진 드라이버
from bs4 import BeautifulSoup # HTML을 파싱해 텍스트 추출
import time # 일정 시간 지연을 위해 사용
# 크롬 드라이버를 사용하여 브라우저 시작
driver = uc.Chrome()
# 뉴스 검색 페이지로 이동
driver.get("https://search.naver.com/search.naver?sm=tab_hty.top&where=news&ssc=tab.news.all&query=iM%EB%B1%85%ED%81%AC")
# 뉴스 제목을 저장할 빈 리스트 생성
box1 = []
# 뉴스 제목을 반복적으로 수집할 루프 시작
while True:
# 페이지의 HTML을 BeautifulSoup으로 파싱
html = BeautifulSoup(driver.page_source, 'html.parser')
# 뉴스 기사 목록에서 각 기사 아이템을 찾기
news = html.find("ul", class_="list_news _infinite_list").find_all("li", class_="bx")
# 각 뉴스 기사에서 제목 추출
for i in news:
a = i.find("a", class_="news_tit")['title'].strip() # 뉴스 제목 텍스트 추출 및 양끝 공백 제거
if a not in box1: # 제목이 이미 리스트에 없으면 추가
box1.append(a) # 중복 방지를 위해 제목 저장
if len(box1) == 100: # 제목이 100개가 되면 수집 종료
break
# 수집된 뉴스 제목이 100개면 루프 종료
if len(box1) == 100:
break
# 페이지 스크롤을 최하단으로 이동 (다음 뉴스 불러오기 위해 사용)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 다음 페이지 로딩 대기
# 현재 수집된 뉴스 기사 개수를 출력
print(f"{len(box1)}개 뉴스기사 수집")
→ 수집 후 크롬창에 신한은행 검색해서 box2 코드 진행
box2 = []
while True:
html = BeautifulSoup(driver.page_source)
news = html.find("ul", class_ = "list_news _infinite_list").find_all("li", class_ = "bx")
for i in news:
a = i.find("a", class_ = "news_tit")['title'].strip()
if a not in box2:
box2.append(a)
if len(box2) == 100:
break
if len(box2) == 100:
break
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 자바 스크립트 명령어 사용할 수 잇는 것, 0에서 한번에 페이지 끝까지 내리겠다
time.sleep(3)
print(f"{len(box2)}개 뉴스기사 수집")
→ box1과 box2 리스트에 저장된 뉴스 제목 데이터를 저장
import pandas as pd
df1 = pd.DataFrame(box1, columns = ['내용'])
df1['은행'] = 'IM뱅크'
df2 = pd.DataFrame(box2, columns = ['내용'])
df2['은행'] = '신한은행'
df = pd.concat([df1, df2])
df.to_csv('news.csv', index = False)
df
→ konlpy 라이브러리의 Okt 형태소 분석기를 사용하여, 데이터에서 명사만을 추출한 후 새로운 열에 저장
from konlpy.tag import Okt # 한글 텍스트 처리를 위한 konlpy 라이브러리에서 Okt 형태소 분석기 임포트
okt = Okt() # Okt 형태소 분석기를 초기화하여 okt 변수에 할당
# make_nouns 함수 정의: 주어진 문자열 x에서 명사만 추출하여 공백으로 구분한 문자열로 반환
def make_nouns(x):
return ' '.join(okt.nouns(x))
# news.csv 파일을 읽어 데이터프레임으로 저장
df = pd.read_csv('news.csv')
# '내용' 열의 각 행에 make_nouns 함수를 적용하여 'Nouns' 열에 결과 저장
df['Nouns'] = df['내용'].apply(make_nouns)
# 결과 데이터프레임 df 출력
df
- make_nouns(x) 함수: 입력된 텍스트 x에서 okt.nouns(x)를 통해 명사 리스트를 추출한 후, join 함수를 사용하여 명사들을 공백으로 연결된 단일 문자열로 변환해 반환
- df['내용'].apply(make_nouns): 내용 열의 각 텍스트에 make_nouns 함수를 적용하여 명사들로만 이루어진 텍스트를 새로 만들어 "Nouns" 열에 추가

→ 뉴스 기사에서 명사만을 추출한 데이터를 단어 빈도 기반의 벡터 형태로 변환
from sklearn.feature_extraction.text import CountVectorizer # CountVectorizer 임포트
cv = CountVectorizer() # CountVectorizer 객체 생성 (텍스트를 단어 빈도수로 변환)
# "Nouns" 열에 있는 명사 텍스트 데이터를 CountVectorizer를 통해 벡터화하고 행렬 형태로 변환
cv_matrix = cv.fit_transform(df['Nouns'])
# 생성된 희소 행렬을 배열 형태로 변환하여 확인하기 쉽게 변경
cv_matrix = cv_matrix.toarray()
# 벡터화된 결과 출력
cv_matrix
- CountVectorizer 객체 생성: cv는 단어 빈도를 세어 벡터화하는 데 사용하는 객체. 기본 설정으로 모든 단어를 개별 요소로 만들고, 해당 단어의 빈도를 세어 각 문장을 벡터화.
- cv.fit_transform(df['Nouns']): df['Nouns']에 들어있는 명사만으로 구성된 텍스트 데이터를 fit_transform을 사용해 벡터화하고, 결과를 희소 행렬 형태로 반환.
- cv_matrix.toarray(): 생성된 희소 행렬을 배열로 변환하여 전체 빈도수 데이터를 확인하기 쉽게 .
- cv.get_feature_names_out(): CountVectorizer가 생성한 모든 단어의 목록을 반환. 각 단어는 cv_matrix의 각 열에 해당하므로, get_feature_names_out()을 통해 어떤 단어가 어떤 열에 위치하는지 알 수 있다.

→ 뉴스 기사 텍스트 기반 은행 분류기 구축 및 성능 평가
뉴스 기사 텍스트 데이터를 사용하여 IM뱅크와 신한은행을 분류하는 모델을 구축합니다. 주어진 텍스트를 벡터화하고 랜덤 포레스트 모델을 사용하여 학습 및 예측을 수행한 후, 모델의 성능을 평가합니다. 마지막으로 특정 텍스트에 대해 예측을 수행
# 타겟 변수를 생성: IM뱅크는 1, 신한은행은 0
df['Target'] = [1] * 100 + [0] * 100
# train_test_split과 RandomForestClassifier 모듈 임포트
from sklearn.model_selection import train_test_split # 데이터 분할을 위한 함수
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트 분류기
# 독립 변수(X)와 종속 변수(Y) 설정
X = cv_matrix # TF-IDF 벡터화된 데이터
Y = df['Target'].values # 타겟 변수를 numpy 배열로 변환
# 데이터셋을 학습 세트와 테스트 세트로 분할
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2, random_state=42)
# test_size=0.2: 전체 데이터의 20%를 테스트 세트로 사용하고, random_state=42: 결과 재현을 위한 시드 설정
# 랜덤 포레스트 모델 초기화 및 학습
model = RandomForestClassifier() # 랜덤 포레스트 분류기 객체 생성
model.fit(train_x, train_y) # 학습 데이터로 모델 학습# 성능 평가를 위한 classification_report 모듈 임포트
from sklearn.metrics import classification_report # 성능 평가를 위한 함수
# 테스트 데이터에 대해 예측 수행
pred = model.predict(test_x) # 테스트 세트에 대한 예측값 생성
# 예측 결과를 평가하고 출력
report = classification_report(test_y, pred) # 실제 값과 예측 값을 비교하여 성능 평가
print(report) # 성능 평가 결과 출력
# 중요 특성 시각화를 위한 라이브러리 임포트
import numpy as np # 수치 계산을 위한 라이브러리
import matplotlib.pyplot as plt # 데이터 시각화를 위한 라이브러리
import koreanize_matplotlib # 한글 폰트 지원
# 모델의 특성 중요도 기반으로 상위 20개 특성 인덱스 선택
idx = np.argsort(model.feature_importances_)[::-1][:20]
# 상위 20개 특성의 중요도를 막대그래프로 시각화
plt.bar(x = cv.get_feature_names_out()[idx], # 특성 이름
height = model.feature_importances_[idx]) # 특성 중요도
plt.xticks(rotation = 90) # x축 레이블을 90도 회전
plt.show() # 그래프 표시
# 예측할 텍스트
text = 'IM뱅크가 원래 대구은행이래' # 분류할 텍스트
# 텍스트에서 명사 추출 후 벡터화
a = ' '.join(okt.nouns(text)) # okt를 사용해 텍스트에서 명사만 추출
a = cv.transform([a]).toarray() # 추출한 명사를 TF-IDF 벡터로 변환
# 모델을 사용하여 예측 수행
model.predict(a) # 벡터화된 텍스트에 대한 예측 결과
오즈비, TF-IDF // 각각 상대적으로 많이 나오는 단어 찾기
# Counter 클래스를 임포트하여 명사 빈도를 계산하기 위한 준비
from collections import Counter
# IM뱅크 명사를 저장할 리스트
box1 = [] # IM뱅크의 명사를 저장할 리스트
# 신한은행 명사를 저장할 리스트
box2 = [] # 신한은행의 명사를 저장할 리스트
# IM뱅크 관련 명사를 box1에 저장
for i in df[df['은행'] == "IM뱅크"]['Nouns'].str.split(): # IM뱅크 관련 뉴스의 Nouns 열에서 명사를 분리
box1 += i # box1 리스트에 분리된 명사를 추가
# 신한은행 관련 명사를 box2에 저장
for i in df[df['은행'] == "신한은행"]['Nouns'].str.split(): # 신한은행 관련 뉴스의 Nouns 열에서 명사를 분리
box2 += i # box2 리스트에 분리된 명사를 추가
# IM뱅크의 명사 빈도를 계산
counter1 = Counter(box1) # IM뱅크의 명사 빈도를 계산하여 counter1에 저장
# 신한은행의 명사 빈도를 계산
counter2 = Counter(box2) # 신한은행의 명사 빈도를 계산하여 counter2에 저장
# IM뱅크의 빈도 데이터를 데이터프레임으로 변환
df1 = pd.DataFrame({"Word": counter1.keys(), "freq": counter1.values()}) # 단어와 빈도를 데이터프레임으로 생성
df1['Bank'] = 'IM' # 해당 데이터프레임에 'Bank' 열을 추가하고 값으로 'IM'을 설정
# 신한은행의 빈도 데이터를 데이터프레임으로 변환
df2 = pd.DataFrame({"Word": counter2.keys(), "freq": counter2.values()}) # 단어와 빈도를 데이터프레임으로 생성
df2['Bank'] = 'Shin' # 해당 데이터프레임에 'Bank' 열을 추가하고 값으로 'Shin'을 설정
df1
# 결과를 저장할 데이터프레임을 생성하여 피벗 테이블 형태로 변환
result = pd.concat([df1, df2]) # df1과 df2 데이터프레임을 합쳐서 result에 저장
result = result.pivot_table(index='Word', columns='Bank', values='freq').fillna(0) # 피벗 테이블 생성
# 각 은행의 비율을 계산 (Laplace smoothing을 위해 +1을 추가)
result['IM Ratio'] = (result['IM'] + 1) / sum(result['IM'] + 1) # IM뱅크의 비율 계산
result['Shin Ratio'] = (result['Shin'] + 1) / sum(result['Shin'] + 1) # 신한은행의 비율 계산
# 오즈 비율 계산: IM뱅크의 비율 / 신한은행의 비율
result['Odds Ratio'] = result['IM Ratio'] / result['Shin Ratio'] # 오즈 비율 계산
# 오즈 비율을 기준으로 정렬
result.sort_values("Odds Ratio") # 오즈 비율에 따라 결과를 정렬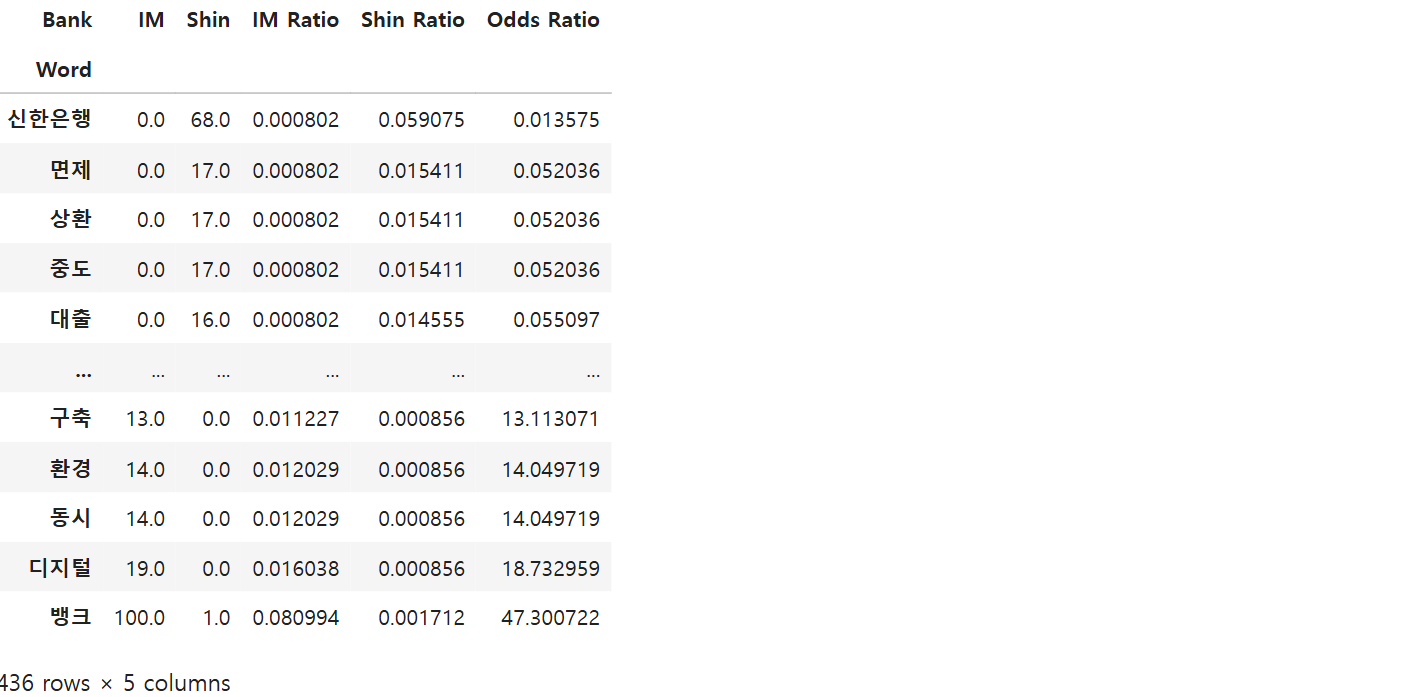
네이버 금융 페이지에서 리뷰 데이터 크롤링
# undetected_chromedriver를 사용하여 Chrome 웹 드라이버를 초기화
driver = uc.Chrome()
# 네이버 금융에서 특정 종목의 게시판을 첫 페이지로 가져옴
driver.get('https://finance.naver.com/item/board.naver?code=055550&page=1')# 경고 메시지를 무시하도록 설정
import warnings
warnings.filterwarnings('ignore')
# 현재 페이지의 HTML 소스를 BeautifulSoup 객체로 변환
html = BeautifulSoup(driver.page_source)
# HTML에서 테이블을 추출하는 함수 정의
def make_table(html):
# 'type2' 클래스의 테이블을 찾기.
table = html.find('table', class_='type2')
# 찾은 테이블을 pandas DataFrame으로 변환하고 '날짜'와 '제목' 열만 선택한 후, 결측값을 제거
table = pd.read_html(str(table))[0][['날짜', '제목']].dropna().iloc[1:] # 첫 번째 행은 불필요하므로 생략
return table# 데이터를 저장할 리스트 초기화
box = []
# 페이지 번호 1부터 100까지 반복하여 크롤링
for n in range(1, 101):
try:
# 페이지 URL을 생성하여 해당 페이지로 이동
driver.get(f'https://finance.naver.com/item/board.naver?code=055550&page={n}')
# 페이지가 완전히 로드될 때까지 최대 10초 기다림.
driver.implicitly_wait(10)
# 현재 페이지의 HTML을 다시 가져오기.
html = BeautifulSoup(driver.page_source)
# HTML에서 테이블을 생성하여 box 리스트에 추가
table = make_table(html)
box.append(table)
except:
# 오류가 발생하면 다음 페이지로 계속 진행
continue# 수집한 테이블을 하나의 DataFrame으로 결합
review = pd.concat(box)
# '날짜' 열을 datetime 형식으로 변환하고 날짜만 남김.
review['날짜'] = pd.to_datetime(review['날짜']).dt.date
# 최종 DataFrame을 출력
review
# FinanceDataReader 라이브러리 임포트
import FinanceDataReader as fdr
# NAVER의 주식 데이터를 가져와서 DataFrame으로 저장
# 'NAVER:055550'는 NAVER의 종목 코드
df = fdr.DataReader('NAVER:055550').reset_index()
# 'Date' 열을 datetime 형식으로 변환
df['Date'] = pd.to_datetime(df['Date'])
# 'Change' 열의 값이 0보다 큰 경우 1, 그렇지 않은 경우 0으로 변환하여 'Target' 열 생성
df['Target'] = np.where(df['Change'] > 0, 1, 0)
# 'Target' 열의 값을 한 칸 위로 이동시킴. (다음 날의 목표 값을 현재 행에 할당)
df['Target'] = df['Target'].shift(-1)
# 결측값이 있는 행을 삭제
df = df.dropna()
df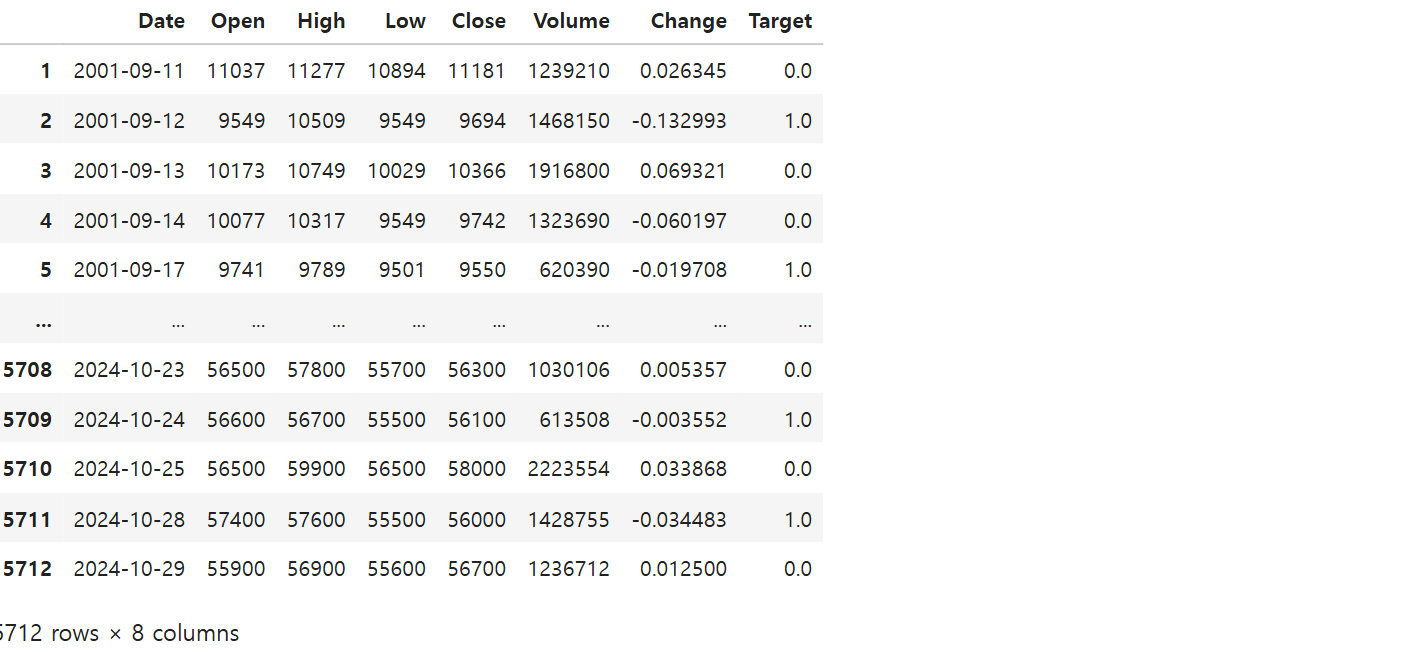
# '날짜' 열을 datetime 형식으로 변환하여 날짜 데이터를 적절히 처리
review['날짜'] = pd.to_datetime(review['날짜'])
# df DataFrame과 review DataFrame을 병합
# 'Date' 열과 '날짜' 열을 기준으로 병합
df2 = df.merge(review, left_on='Date', right_on='날짜')
# 병합 후 불필요한 '날짜' 열을 삭제
del df2['날짜']
# 최종 병합된 DataFrame을 출력
df2
# 'Target' 열의 값의 개수를 세어서 각 클래스의 분포를 확인함
df2['Target'].value_counts()
# Okt 형태소 분석기를 사용하기 위해 초기화함
from konlpy.tag import Okt
okt = Okt()
# '제목' 열에서 명사 추출하여 'Nouns' 열에 저장함
df2['Nouns'] = df2['제목'].apply(make_nouns)
df2
# CountVectorizer를 사용하여 텍스트 데이터 벡터화 준비함
cv = CountVectorizer()
cv_matrix = cv.fit_transform(df2['Nouns']) # Nouns 열에서 단어의 출현 빈도를 기반으로 행렬 생성
cv_matrix
# 희소 행렬을 넘파이 배열로 변환함
X = cv_matrix.toarray()
Y = df2['Target'].values # 타겟 변수인 'Target' 열을 배열로 변환함
# 데이터셋을 학습용과 테스트용으로 나누어 줌
train_x, test_x, train_y, test_y = train_test_split(X, Y)
# RandomForestClassifier 모델 생성하고 학습함
model = RandomForestClassifier()
model.fit(train_x, train_y)
# 테스트 데이터로 예측 수행함
pred = model.predict(test_x)
# 예측 결과에 대한 분류 리포트를 생성함
report = classification_report(test_y, pred)
print(report)
# 모델의 피처 중요도를 기준으로 상위 20개의 단어 인덱스를 가져옴
idx = np.argsort(model.feature_importances_)[::-1][:20]
# 중요도가 높은 단어들의 막대 그래프를 그리기 위한 설정함
plt.bar(x=cv.get_feature_names_out()[idx], height=model.feature_importances_[idx])
# x축 레이블을 90도 회전하여 가독성을 높임
plt.xticks(rotation=90)
# 그래프를 화면에 출력함
plt.show()
# CountVectorizer와 TF-IDF 벡터화 방법을 가져옴
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# TF-IDF 벡터라이저 객체 생성
cv = TfidfVectorizer()
# 'Nouns' 열의 텍스트 데이터를 TF-IDF 방식으로 벡터화하여 행렬을 생성함
cv_matrix = cv.fit_transform(df2['Nouns'])
# 생성된 희소 행렬을 넘파이 배열로 변환함
cv_matrix = cv_matrix.toarray()
# 벡터화된 결과 행렬을 출력함
cv_matrix
# 주석 처리된 부분: 모든 단어의 이름을 가져오는 메서드
# cv.get_feature_names_out()
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| CountVectorizer, Word2Vec, Autoencoder 모델 (0) | 2024.11.12 |
|---|---|
| RSI, 볼린저 밴드를 활용한 투자 전략 (EMA, finterstellar 라이브러리 사용) (3) | 2024.10.29 |
| 강화학습 - 밴디트 알고리즘(슬롯 확률 시뮬레이션, 상승장 종목 찾기) (2) | 2024.10.24 |
| 변동성 돌파 전략, 마켓 타이밍 전략 (4) | 2024.10.23 |
| 주식 포트폴리오 분석을 위한 시뮬레이션 - 몬테카를로 시뮬레이션, 샤프지수, KOSPI 통계분석, 종목간 상관관계, 최대 낙폭, 할로윈 투자 전략 (2) | 2024.10.21 |


