Series
- 1차원 배열
- 리스트, 튜플, ndarray, dict등으로부터 생성 가능
- homogenous data type을 가짐(1가지 데이터타입을 갖는다)
Series 생성
import pandas as pd 선언
tuple로 부터 Series를 만들 수 있다.

-> 별도의 index를 설정하지 않는 다면 0 1 2차례대로 자동으로 index설정
객체를 동종으로 하여 개별적으로 타입을 가질 수 있다.
-> 기존 numpy에서는 데이터 타입이 섞여있으면 전부 문자열로 실행하지만,
pandas에서는 객체타입(여러개 데이터타입이 가능한)으로 변경하여 여러개 데이터 타입이 가능하다
본래 자신의 데이터타입을 유지한다
dictionary 형태
-> dictionary의 key가 index가 된다 -> named index
슬라이싱
-> named indexing은 끝 인덱스도 포함
named index 없는 데이터를 가져와 만들어보기
인덱스를 주고 name으로 시리즈 자체의 이름 설정 가능
indexing하는 3가지 방법
boolean indexing -> list 형태로 boolean 값 주기
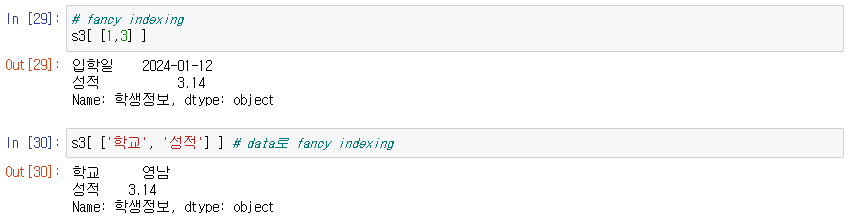
fancy indexing
DataFrame
- 2차원 배열
- 같은 크기의 리스트를 가진 dict 타입으로 생성하는 경우가 많다.
DataFrame 생성
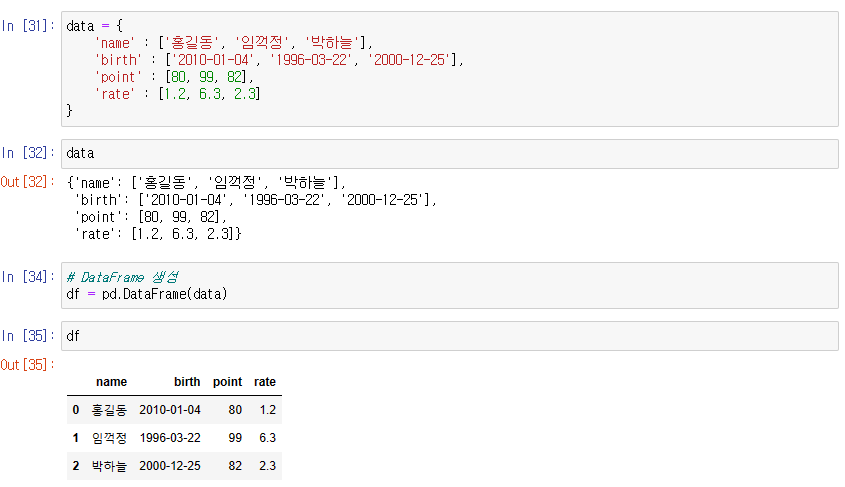
-> key가 column의 이름으로 생성됨
column 마다 index 존재
'name' , 'birth', ... 을 column's index라고 하며 0,1,2...을 row index 혹은 index라고 한다.
type 알아보기
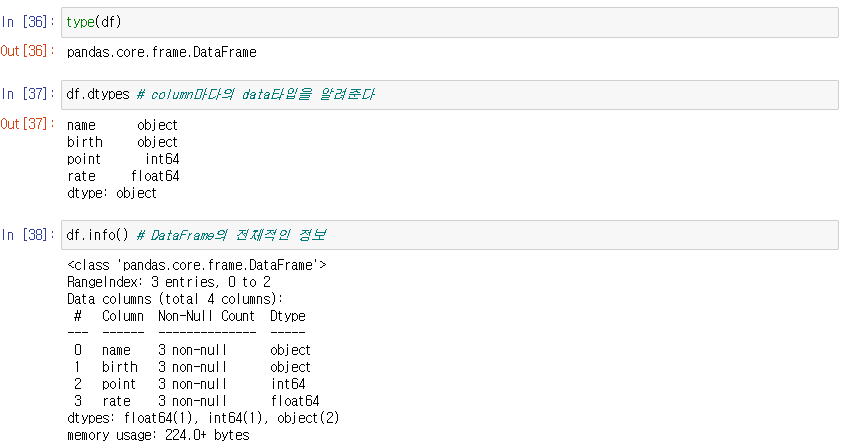
-> column의 각각이 어떤 타입을 가지고 있는지 알 수 있다.
df.info()의 null값을 missing data 혹은 결측치 라고한다.
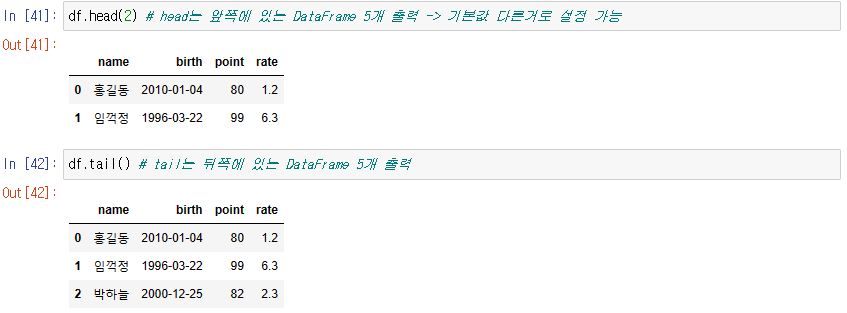
head(), tail()
head() : 기본이 5개여서 시작의 5개의 데이터를 출력해준다
tail() : 기본이 5개여서 끝의 5개의 데이터를 출력해준다
기초 통계자료 출력
df.describe()
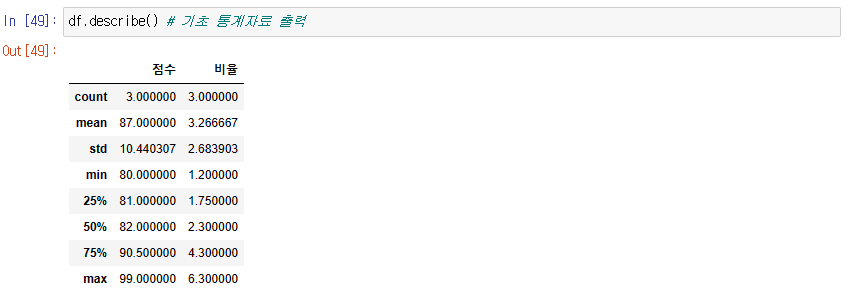
-> count 개수, mean 평균, std 표준 편차, 50% 중간값
전치행렬
df.T

데이터의 정렬
- index기준으로 정렬
- DataFrame이 가지고 있는 값을 기준으로 정렬
(1) 인덱스를 기준으로 정렬
sort_index()
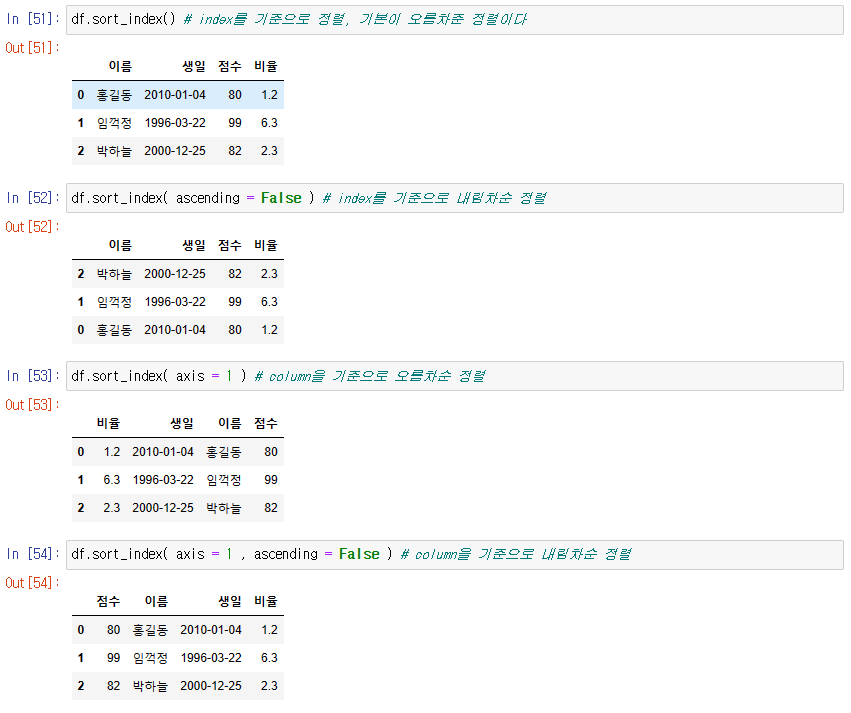
-> ascending = False로 내림차순으로 변경 가능
(2) 값을 기준으로 정렬
sort_values()
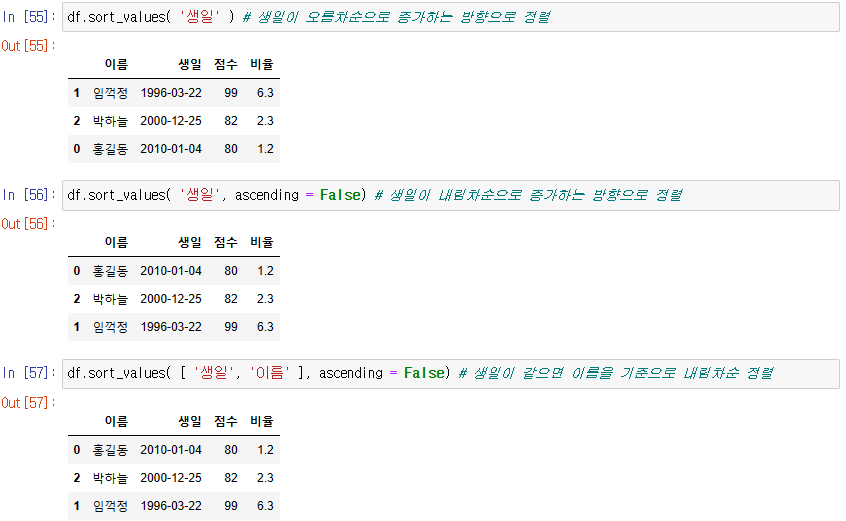
-> 리스트형태로 주게되면 리스트 순서대로 정렬한다 (생일이 같으면 이름순으로 정렬)
df() 에 행을 선택하면 오류 발생 -> column을 기준으로 선택
df[0] : 0번행 선택 =>오류발생 (keyError)
df['이름'] : column을 선택
df[ 0:2 ] : 슬라이싱 하는 경우 행을 선택
df['이름':'점수'] : 오류 발생
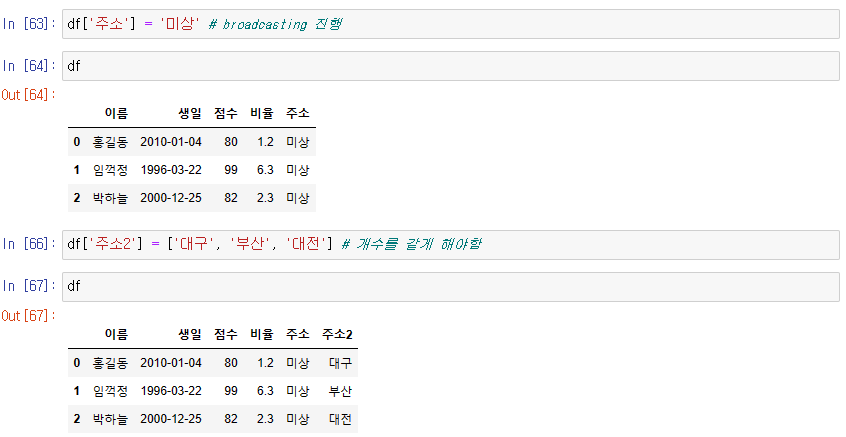
broadcasting 진행
행과 열의 인덱스 바꾸기
(1) 열의 인덱스를 바꿔보기
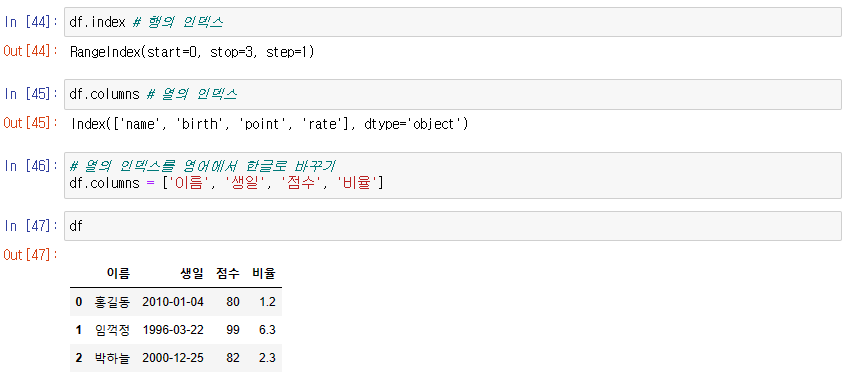
(2) 행의 인덱스 바꿔보기
df.set_index() : column 중 하나를 행의 index로 설정
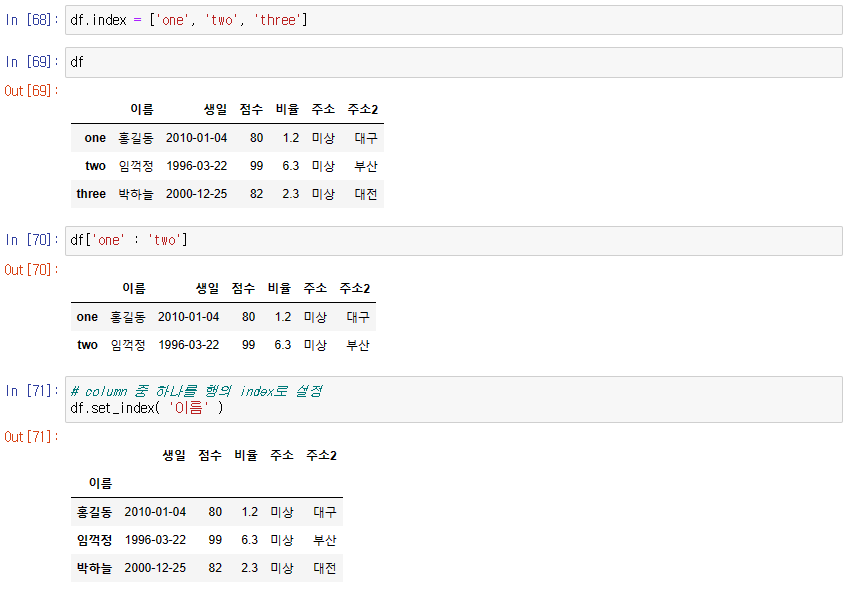
DataFrame에 결과 즉시 반영하고 싶은 경우 inplace = True
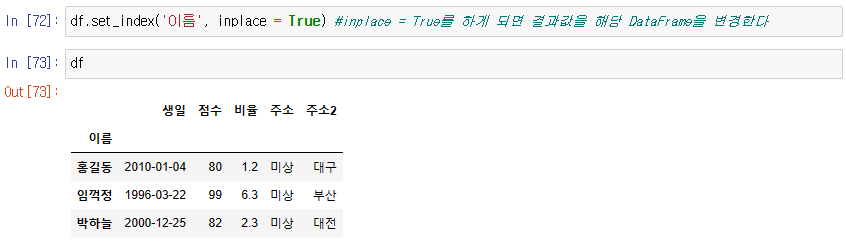
-> inplace = True : 리턴값 없이 DataFrame에 즉시 적용하여 변경
특정 행과 열의 정보를 출력
(1) 특정 index 정보만 출력하고 싶은 경우
홍길동의 정보만 출력하고 싶은 경우
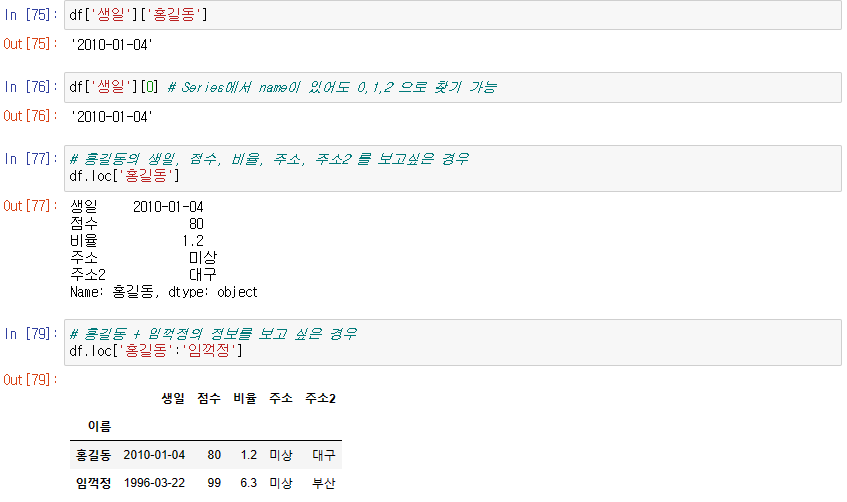
-> loc는 행을 선택하여 Series로 만든다.
(2) 특정 column 정보만 출력하고 싶은 경우
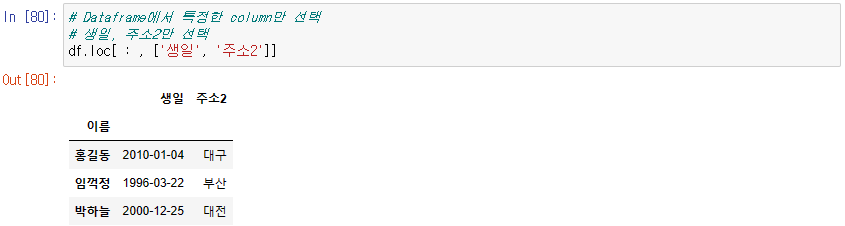
(3) 특정 행, 특정 열 정보를 모두 출력
iloc -> 정수형 인덱스만 사용가능하다

df.at -> 하나의 인덱스를 문자열로 갖고 오기
무조건 1개의 값만 나타날때 사용한다

DataFrame의 특정 행과 열을 삭제
[1] 특정 열을 삭제
del df[]
df.drop()
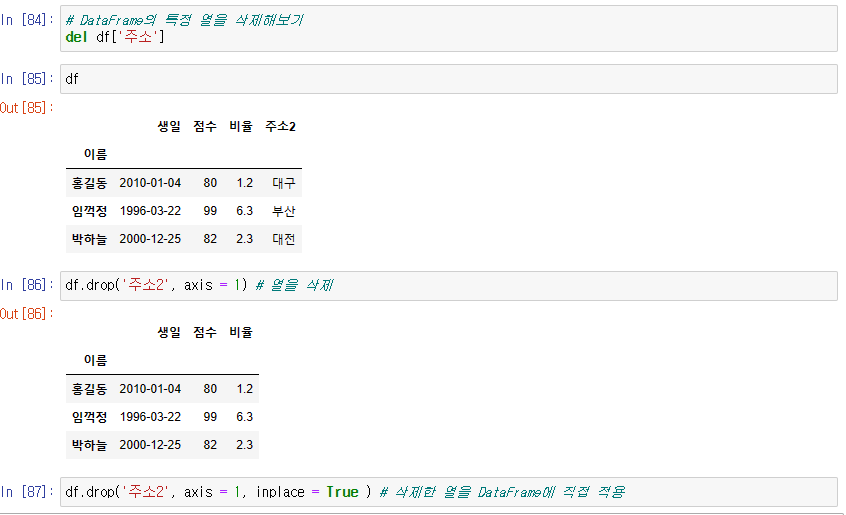
-> del은 column만 삭제 할 수 있지만 drop은 column과 row모두 삭제할 수 있다.
단, DataFrame이 바뀌는 것이 아님
drop을 사용할 때 inplace = True 을 사용하면 DataFrame에 직접 적용
[2] 특정 행을 삭제
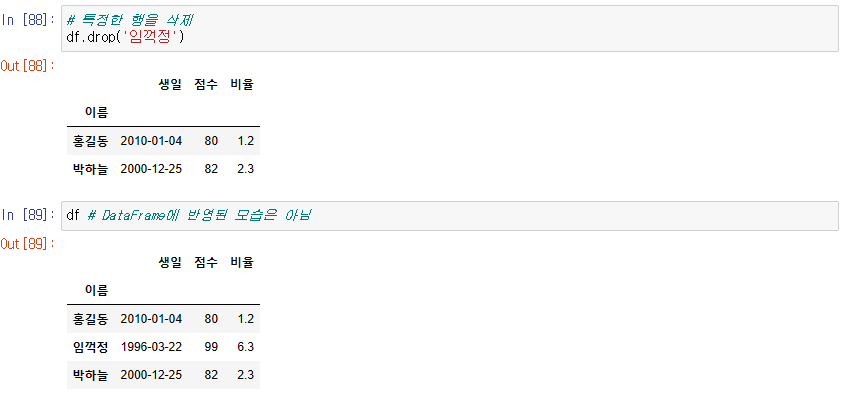
-> inplace = True을 사용하지 않으면 DataFrame에 반영되지는 x
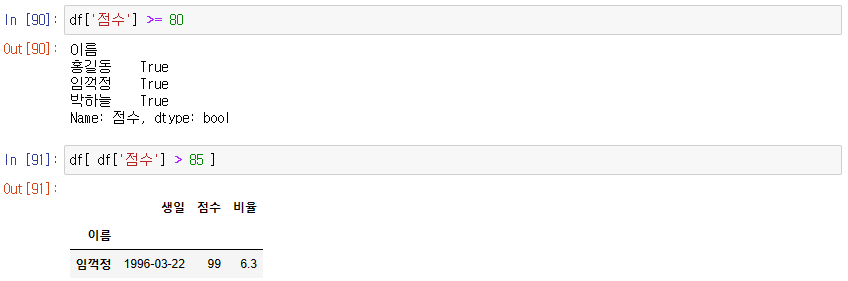
Boolean indexing
df[Boolean index]
새로운 데이터를 기존 DataFrame에 추가
df.append()
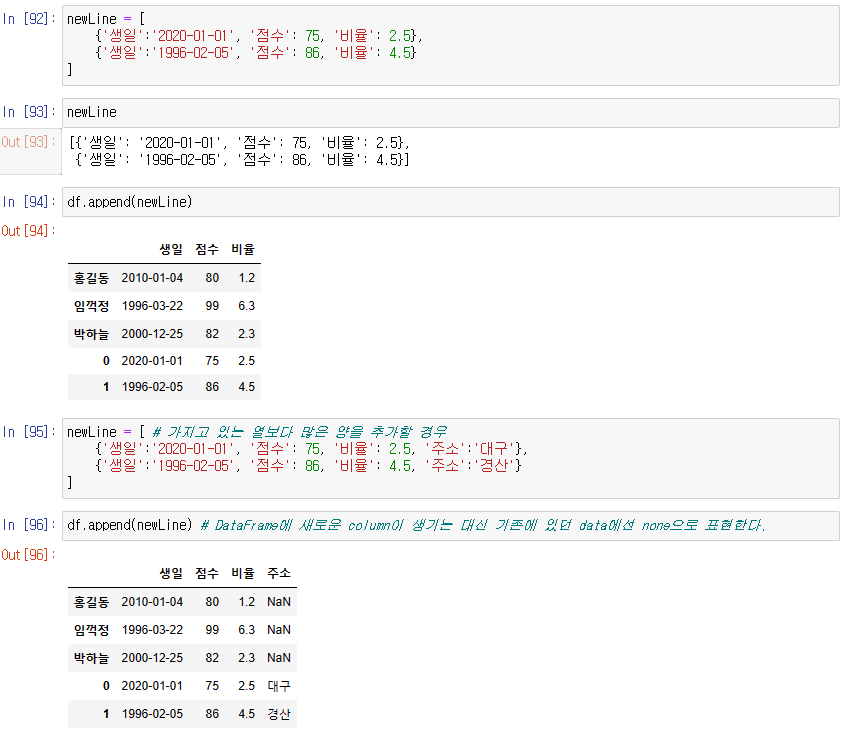
-> 가지고 있는 열보다 많은 양을 추가할 경우
DataFrame에 새로운 column이 생기는 대신 기존에 있던 data에선 none으로 표현됨
index 수정
rename()
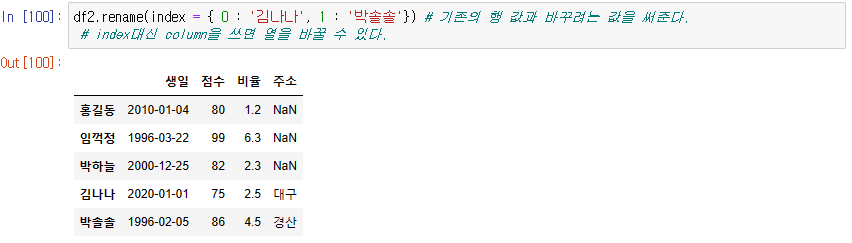
-> rename 함수에 기존의 행 값과 바꾸려는 값을 써준다.
index를 써주면 행이 바뀌고 column을 쓰면 열을 바꿀 수 있다.
새로운 DataFrame을 만들어 기존 DataFrame과 합치기
set_index()
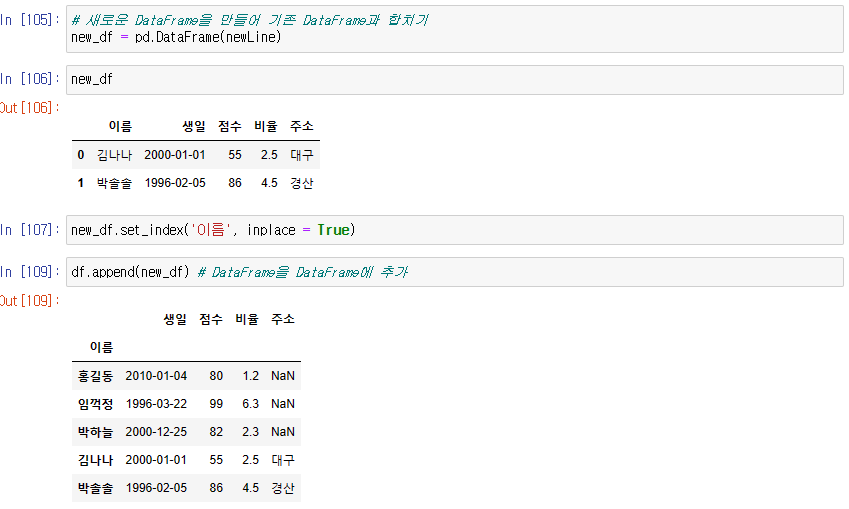
Pandas의 함수
mean() : column별로 평균 구하기 -> 단, 데이터가 산수값
sum() : 합을 구하기 -> 문자열도 더해짐

영화 캐스팅 정보를 활용한 실습
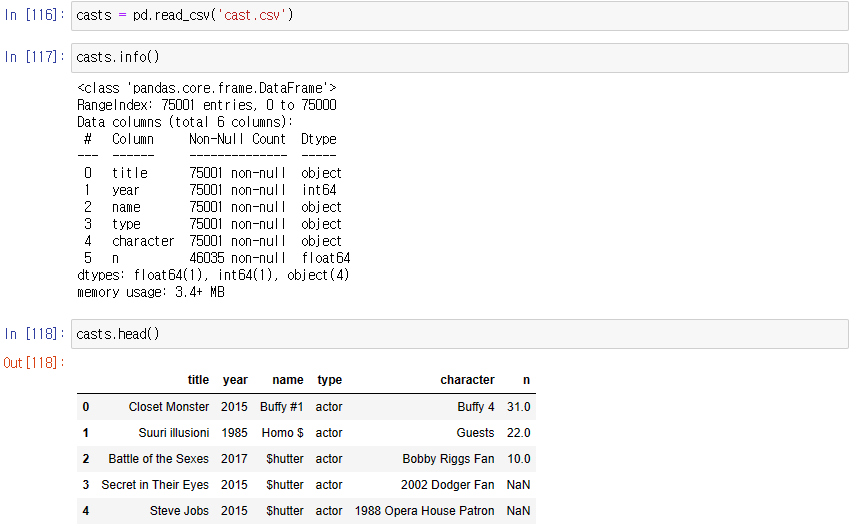
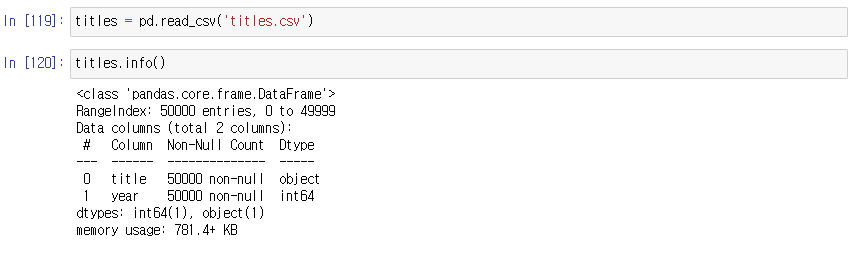
1. titles에서 2000년 이후에 개봉한 영화만 선택하시오
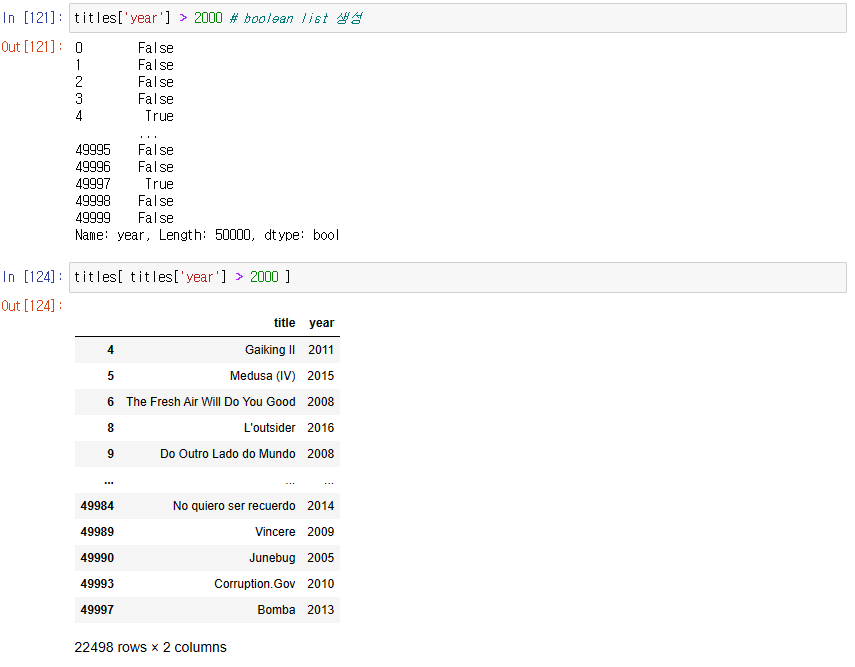
2. 2000년대 개봉한 영화는? (2000~ 2009년 사이에 개봉한 영화)
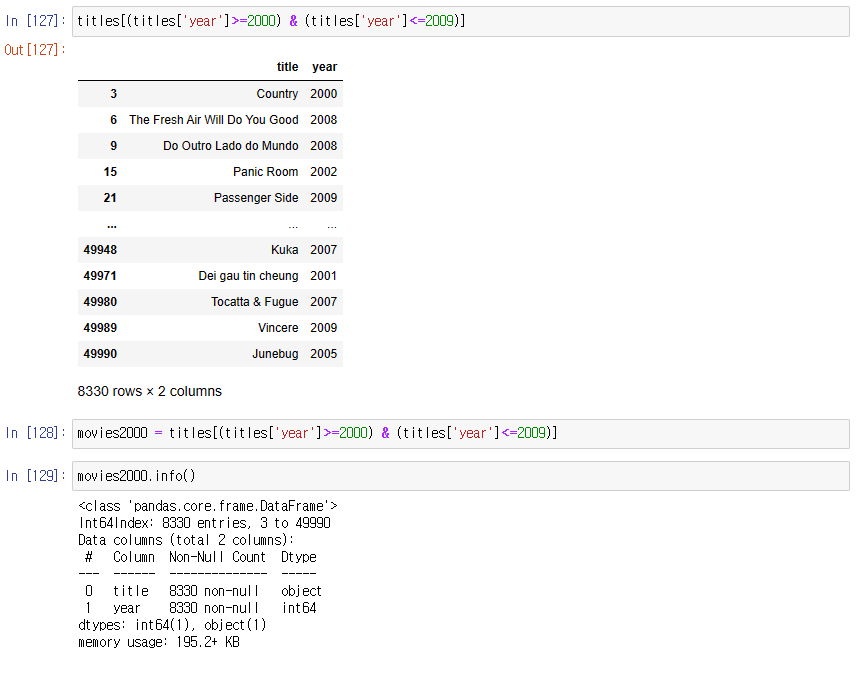
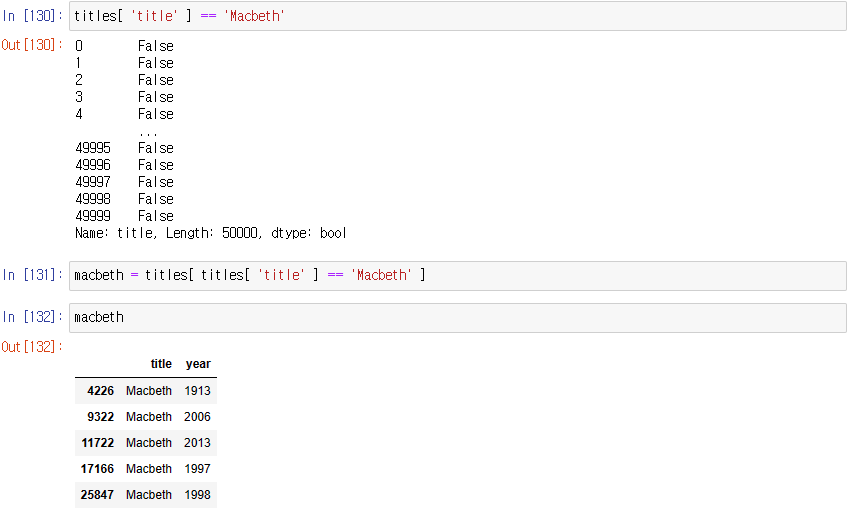
3. 영화 제목이 Macbeth 인 것을 선택하고, macbeth 변수에 저장
4. macbeth를 연도별로 오름차순 정렬
5. macbeth_ordered를 index의 내림차순으로 정렬
6. movies2000을 연도별로 먼저 정렬하고, 같은 연도일 경우 제목으로 정렬
-> values에 column을 리스트로 작성할 수도 있고
오름차순 내림차순 또한 리스트로 작성함으로써 column별로 따로 정할 수있다.
반복문으로 DataFrame의 전체 내용 다뤄보기
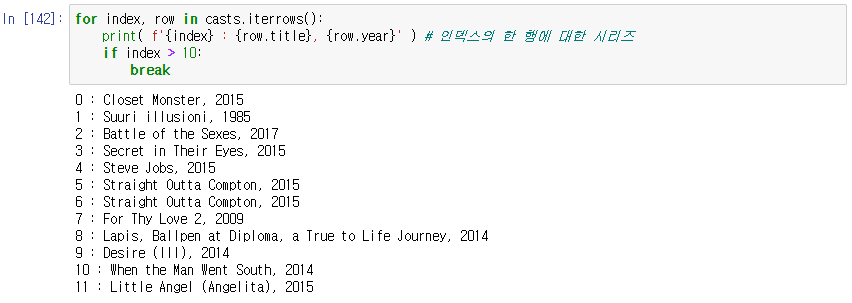
-> casts에서 iterrows를 줘서 한 행씩 가져온다. + index와 행의 값을 튜플로 가져온다.
Missing Data 처리 (결측값, 결측치)
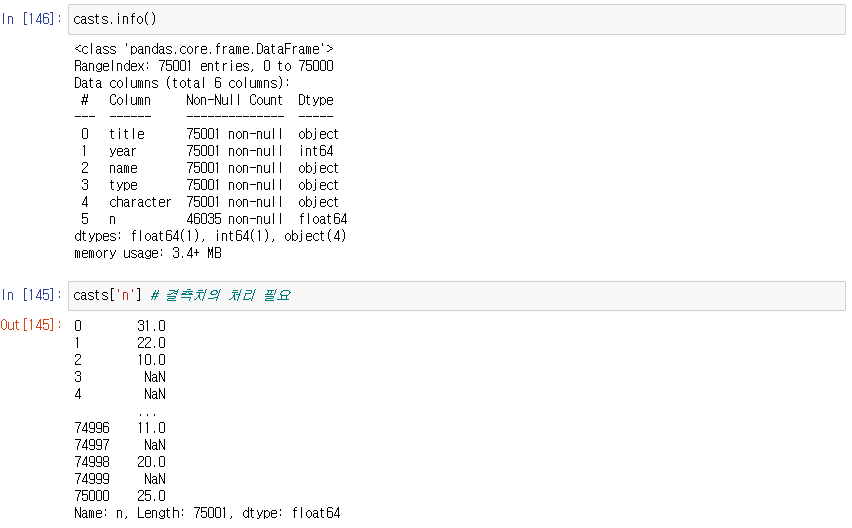
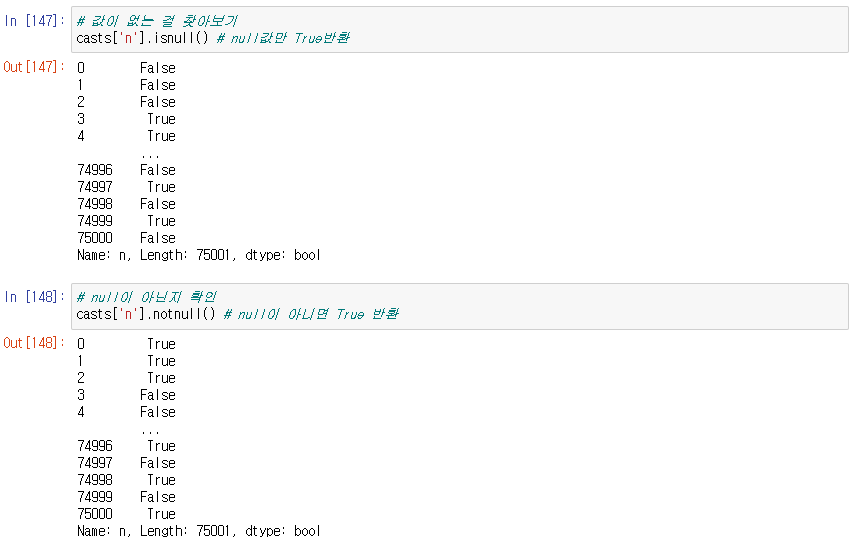
값이 없는 걸 찾아보기
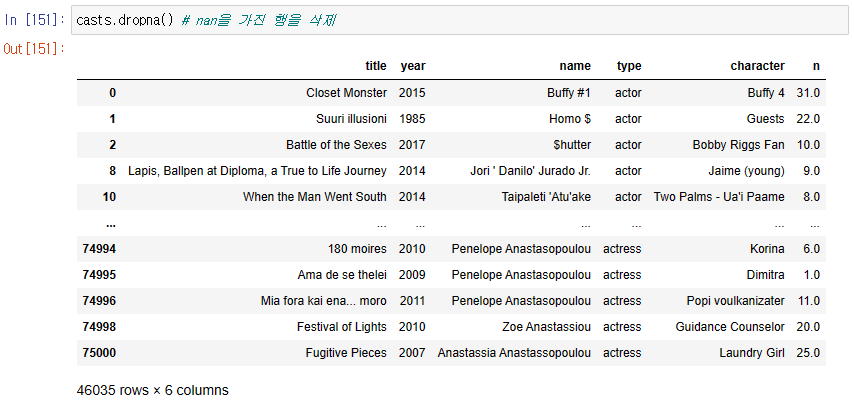
none 을 가진 행을 삭제
1. dropna()로 결측치를 가진 행을 삭제
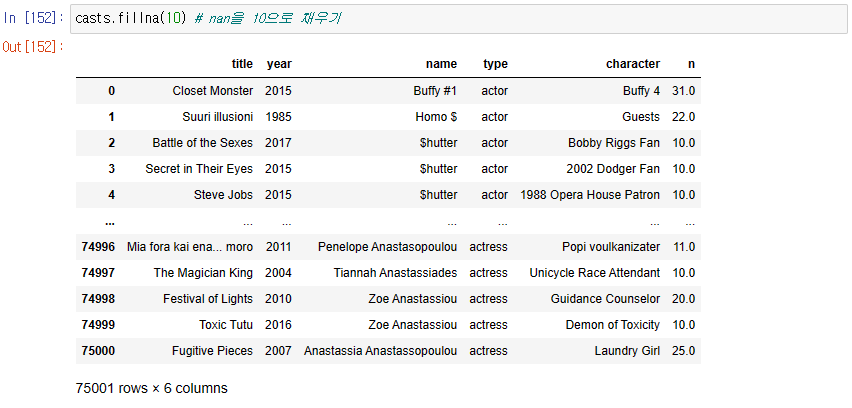
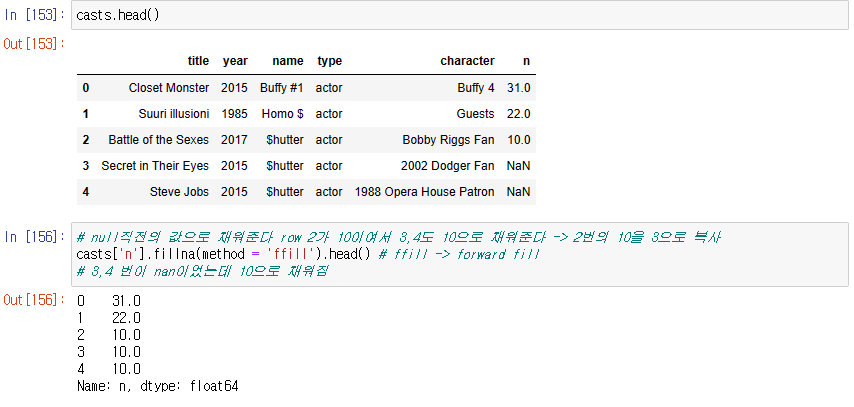
2. casts.fillna()로 특정 값으로 nan을 채우기
casts.fillna()
casts['n'].fillna(method = 'ffill')
casts['n'].fillna(method = 'bfill')

fillna( casts['n'].mean()

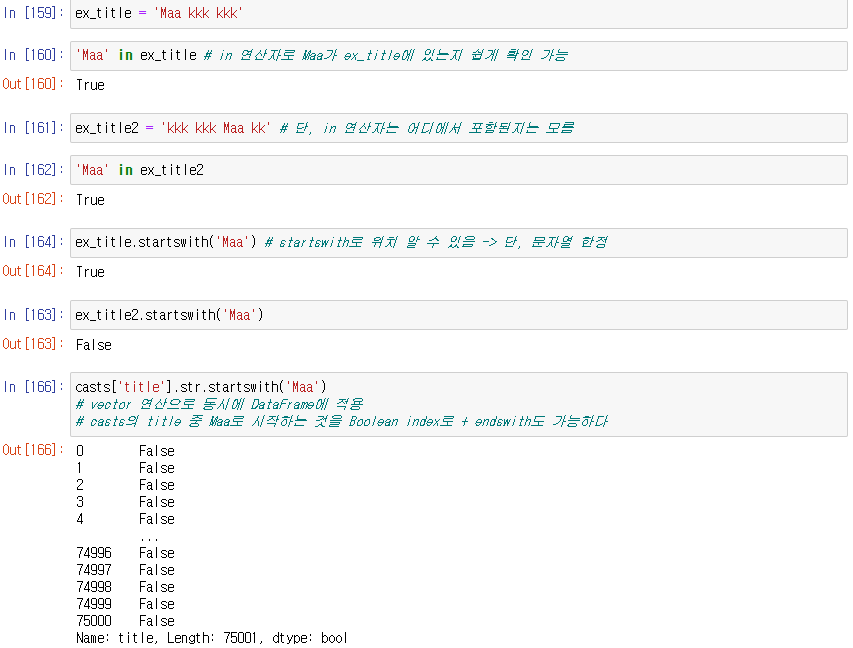
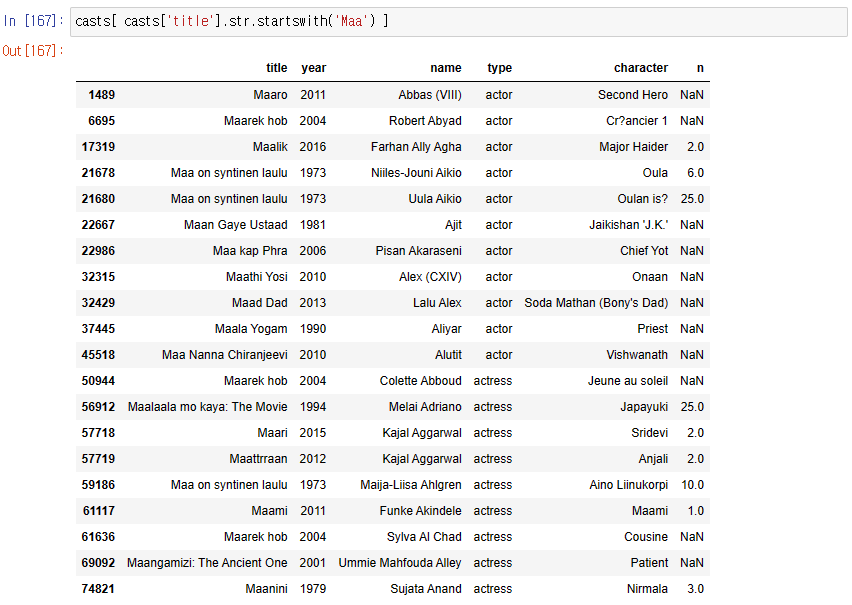
7. casts에서 제목이 Maa로 시작하는 영화를 모두 선택
startswith() 로 위치 알 수 있음 -> 단, 문자열 한정
그래서 casts['title'].str.startswith('Maa') 같이 문자열로 변형 후 startswith 함수 사용
-> casts의 title 중 Maa로 시작하는 것을 Boolean index로 + endswith도 가능
같은 연도와 영화 제목이 몇 번 나온지
value_counts() : 같은 값이 몇 번 나온지 알려줌
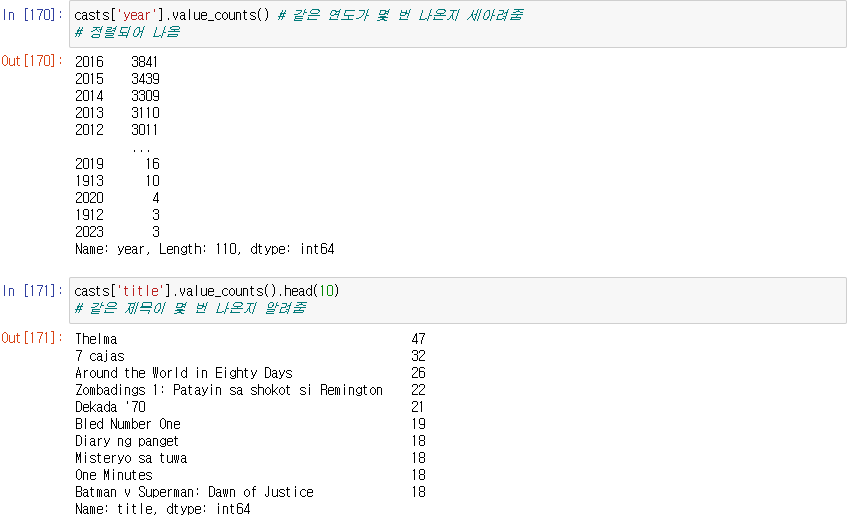
value_counts를 사용하여 각 연도별로 개봉한 영화의 개수 정보 그래프로 알아보기
import matplotlib.pyplot as plt 를 선언해 시각화
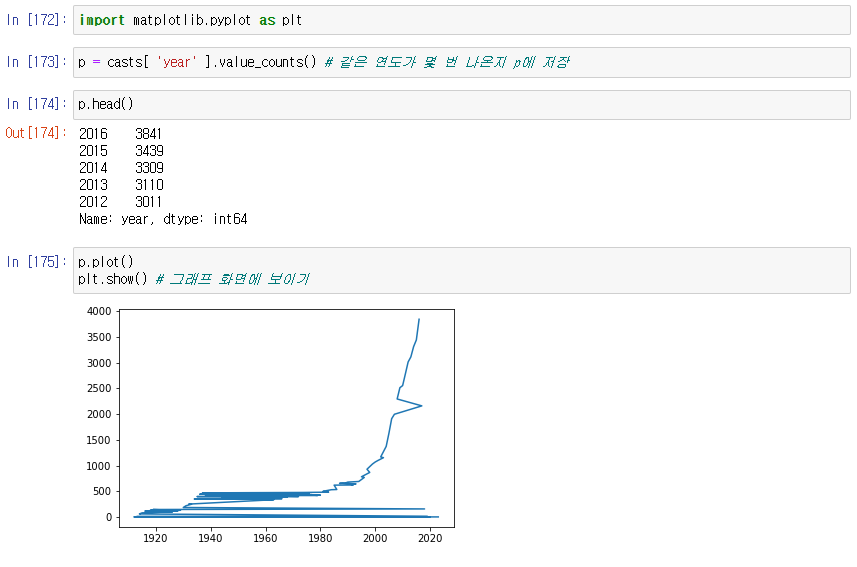
-> 정렬을 하지 않으니 그래프 모양이 이상함
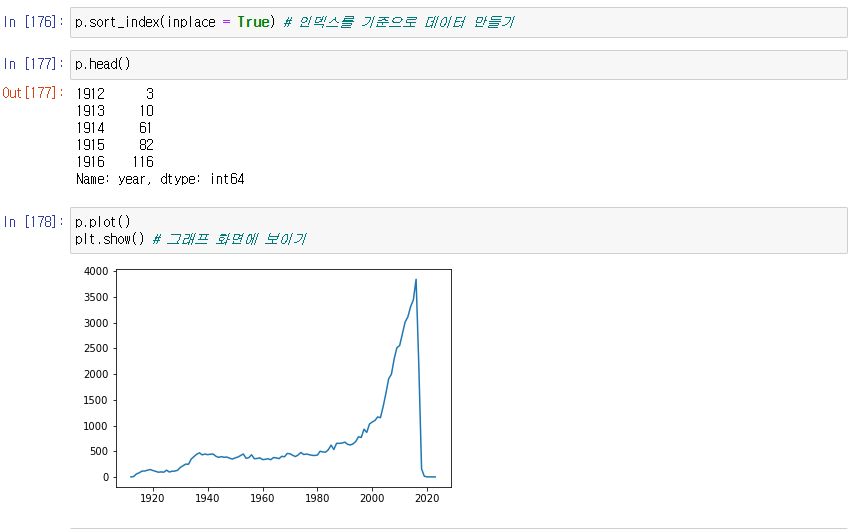
-> 연도별로 정렬한 영화의 개수 출력됨
막대그래프로 출력해보기
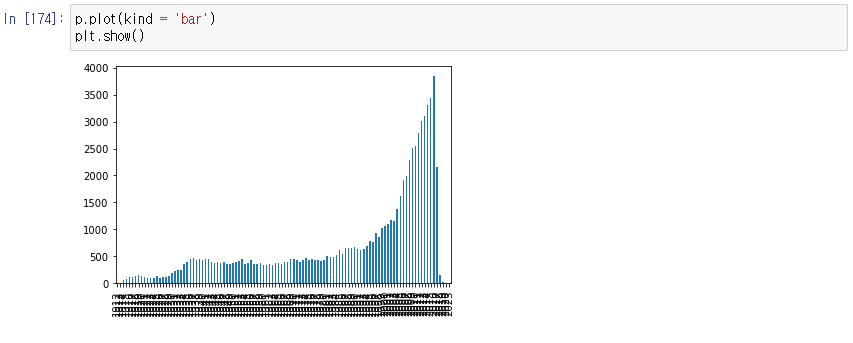
그룹화 (Grouping)
casts.groupby()
value_count도 그룹화의 일종
value_count 보다 다양하게 묶는게 그룹화

만들어진 그룹에 여러 기능 요청 가능
size() : 묶여진 그룹의 사이즈

.n.max(), n.min() : 만들어진 그룹에서 최댓값, 최솟값 계산
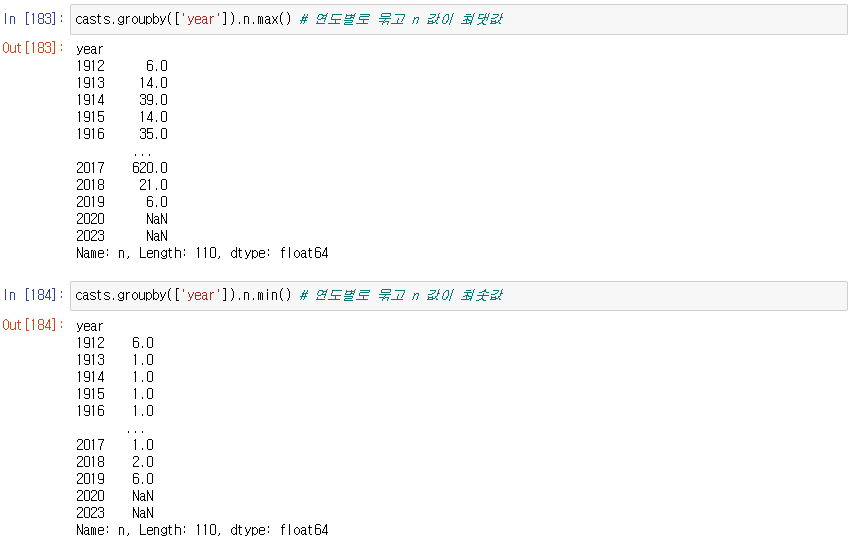
8. casts 중에서 Aaron Abrams가 출연한 영화를 모두 찾아서 cf 변수에 저장
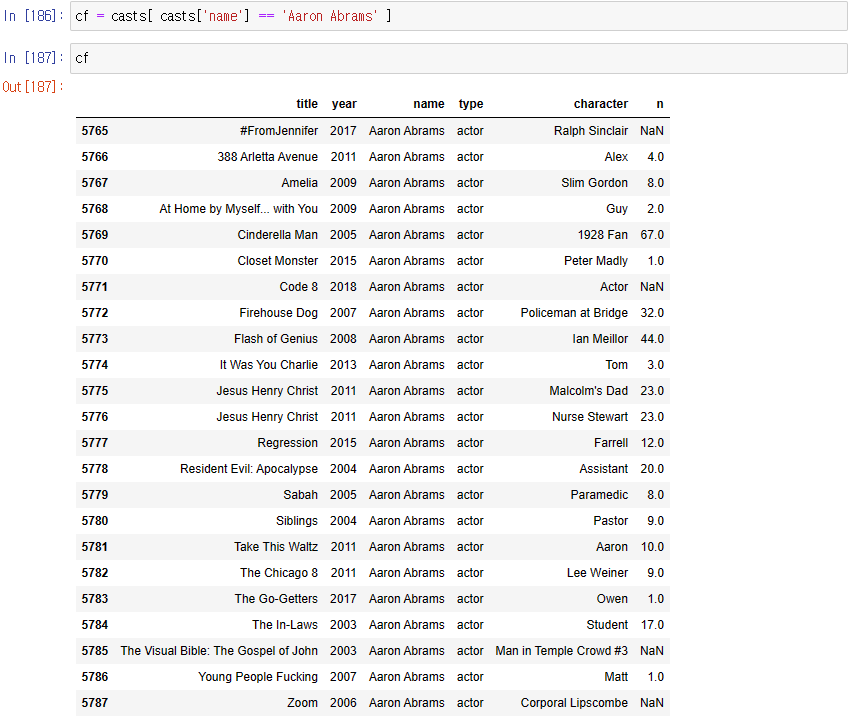
9. Aaron Abrams가 각 연도별 출연한 영화의 수를 구하고 막대그래프로 그리기
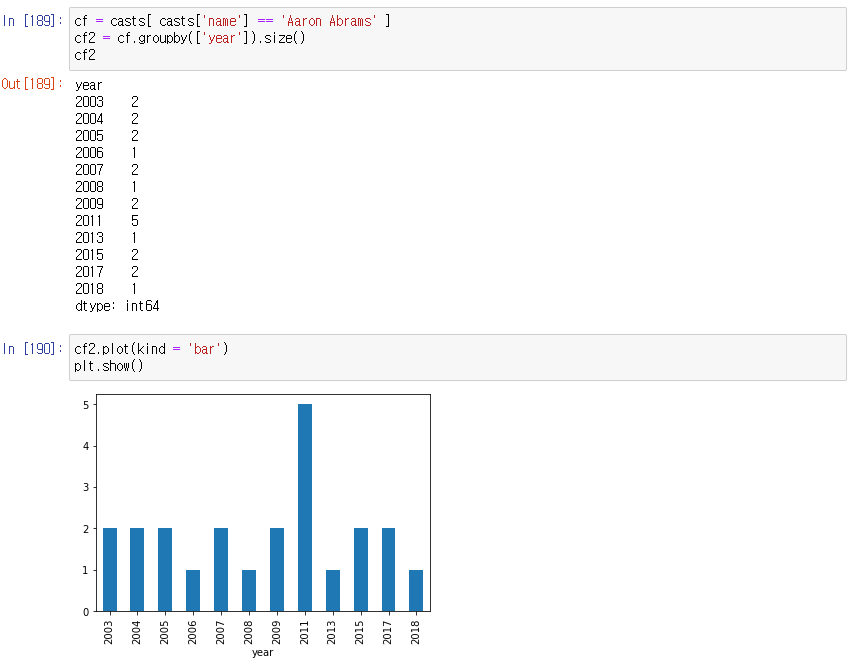
수직그래프로 그리기 (kind = 'barh')
10. casts에 각 decade(각 10년) 마다 몇 편의 영화가 나왔는지 구하기

-> decade의 순서가 casts의 순서와 동일 하기 때문에 casts가 가지고 있지 않은 열로도 가능
decade 기준으로 나누고 내부적으로 type(성별)을 기준으로 나눠 막대그래프로
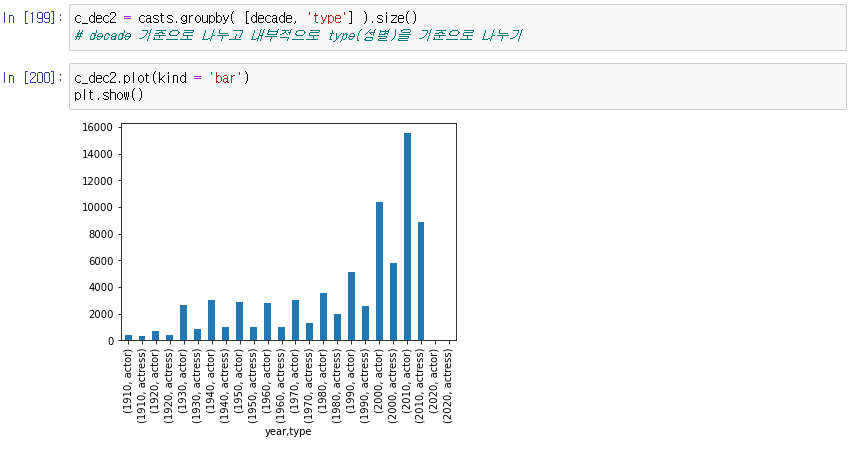
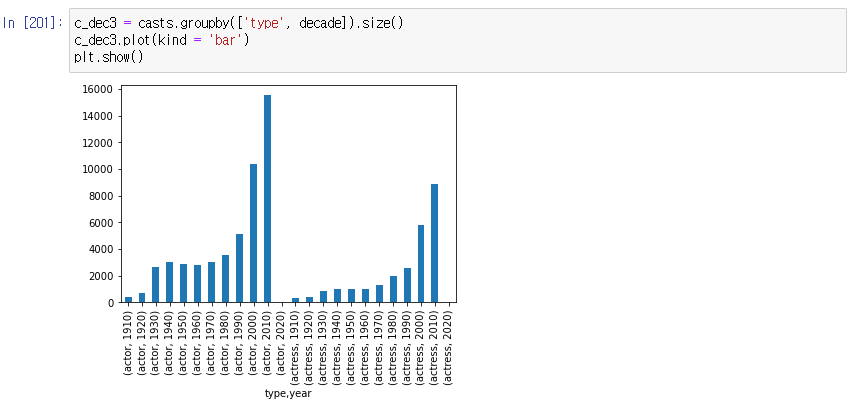
-> multi index라 데이터 표현에 어려움 o
인덱스로 풀어보기
unstack() : multi index를 column으로 바꿔주기
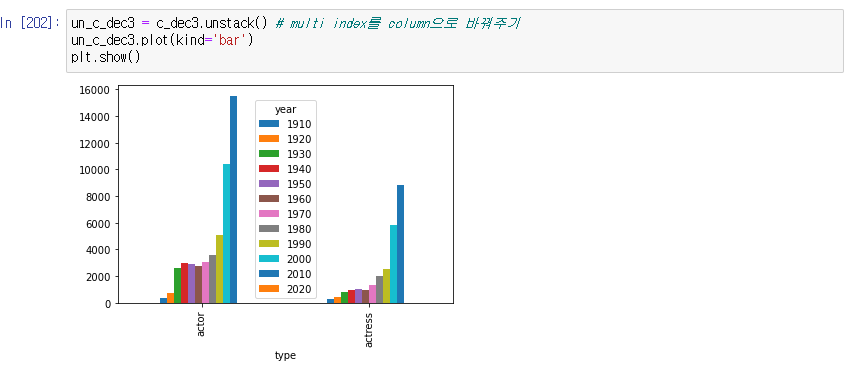
-> x축에 연도가 들어가길 원하는 경우?
전치행렬 : 행과 열을 바꿔보기

-> 한 눈에 보기 좋은 모습
DataFrame 조합하기
-> release와 casting 정보 섞어보기
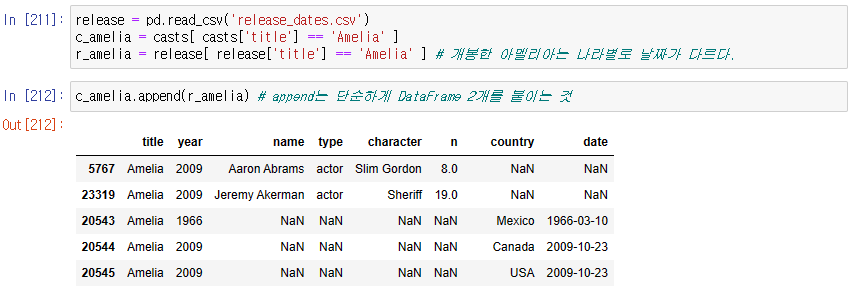
-> append() 는 단순히 붙인 것
merge() : 공통된 column을 기준으로 합치기
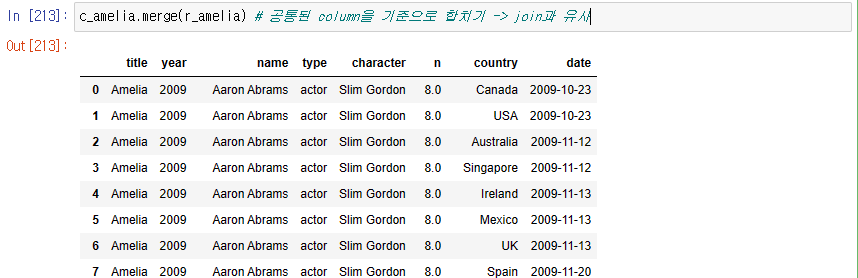
11. Aaron Abrams와 함께 출연한 배우들의 리스트
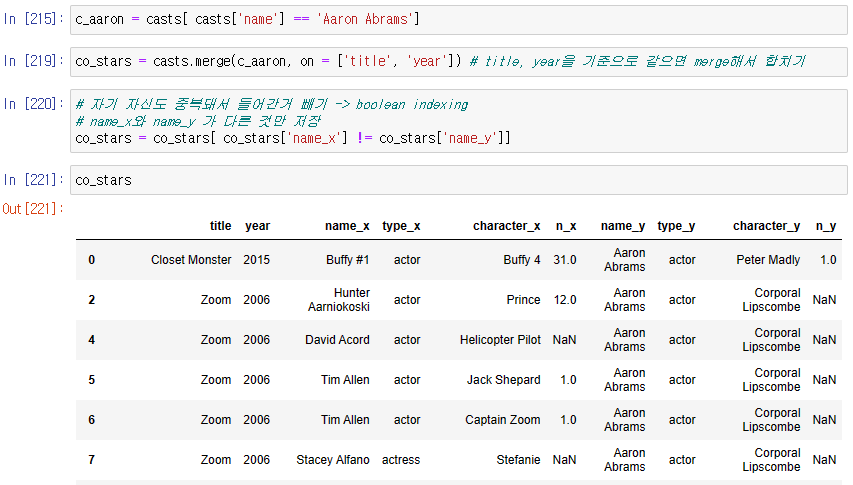
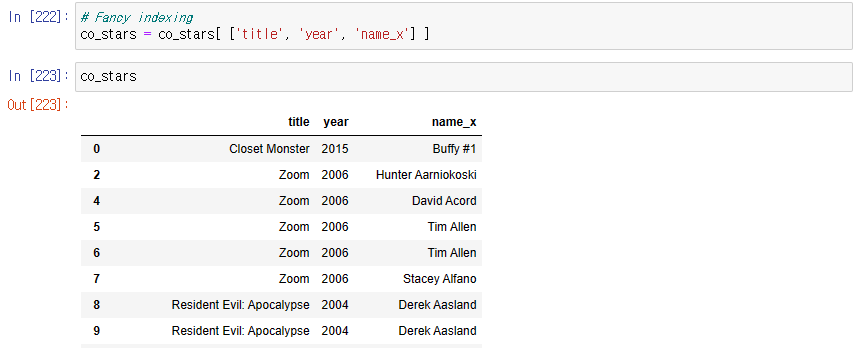
위 정보 중 어떤 영화에 누구와 출연한지만 고르기 -> title, name_x, year만 출력
: Fancy Indexing
-> 어떤 배우는 한 영화에 두 개 이상의 캐릭터로 나오는 경우 존재
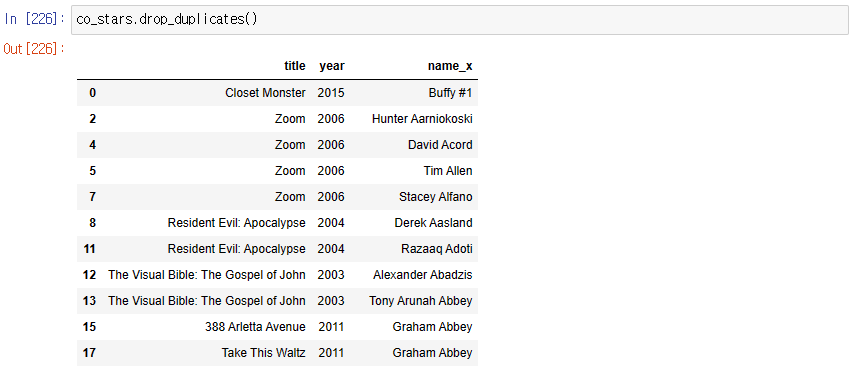
중복되는 name_x 없애기
duplicated() : 중복된지 확인
drop_duplicates() : 중복된거 제거
이름만 출력
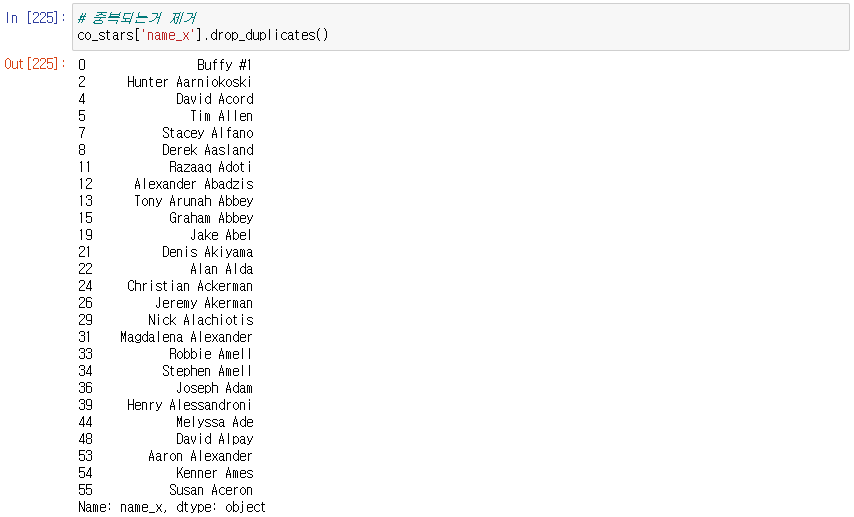
-> 중복된 이름 제거된 모습
영화 제목, 연도, 이름 출력
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 9일차 - 서울시 CCTV 현황, 인구현황, 범죄현황을 기반으로 데이터 분석 실습 (0) | 2024.01.16 |
|---|---|
| 8일차 - 시계열 데이터를 위한 Pandas 응용 및 각종 데이터 시각화 기법 학습 및 실습 (1) | 2024.01.15 |
| 6일차 - 다양한 Numpy 관련 기초 내용 및 Numpy를 활용한 기상데이터 분석 학습 (1) | 2024.01.11 |
| 5일차 - MySQL, pymysql, tkinter와 pymysql 연동, 기상청 데이터 분석, 인구 현황 분석 (1) | 2024.01.10 |
| 4일차 - 파일과 예외처리, 내장함수, 람다식, 모듈, Top-K 텍스트 분석, CF기반 추천 시스템 (1) | 2024.01.09 |



