합성곱 신경망 (Convolutional Neural Network, CNN)
고양이의 눈에서 답을 얻다
전체 뉴런을 활용하지 않고 이미지에 따라 고앵이의 뉴런이 활성화된다. -> CNN 만들어짐
• CNN은 이미지를 위해 사용되는 인공신경망의 한 종류
• 입력 이미지로부터 특징을 추출하여 입력 이미지가 어떤 이미지인지 클래스를 분류함
-> 기존의 일반 신경망은 한픽셀 한픽셀 정보가 동등하게 중요했지만
CNN은 이미지의 모든 특성을 고려하지 않고(전체 뉴런을 활용하지 않고)
특징점을 찾아 부분부분의 특징을 찾아내는 신경망
• 일반 신경망의 경우, 이미지 전체를 하나의 데이터로 입력하기 때문에 (뉴런을 100% 써서)
이미지의 특성을 찾지 못하고, 이미지의 위치가 약간 변경되거나 왜곡된
경우 올바른 성능을 기대할 수 없음 -> 데이터의 형상이 무시됨
• CNN은 이미지를 하나의 데이터가 아닌 여러 개로 분할하여 처리함
-> 이미지가 왜곡되더라도 이미지의 부분적 특성을 추출할 수 있어 올바른 성능을 낼 수 있음
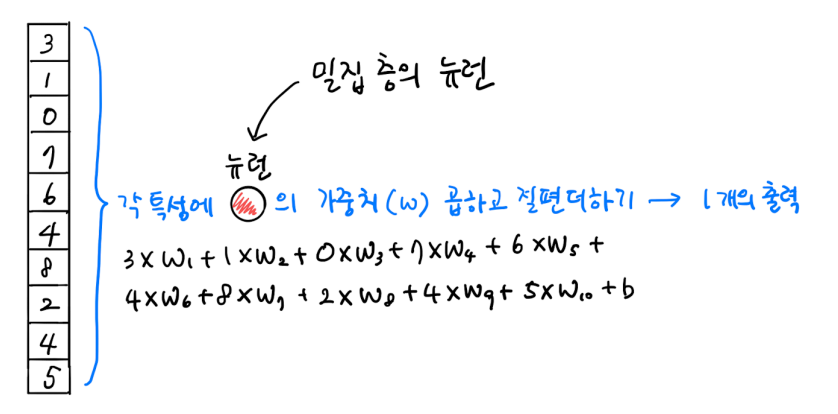
밀집층은 784개의 일차원 이미지라고 생각하면 모든 각 특성에 뉴런의 가중치(w)를 곱하고 절편 더하기

합성곱 층은 2차원 그대로 들어올 수 있지만 일차원이라 생각하면
뉴런 전체를 안넣고 3개 정도만 넣은 다음 각 특성에 뉴런의 가중치 곱하고 절편 더하기
그 후 shift 하여 밑으로 가서 또 출력
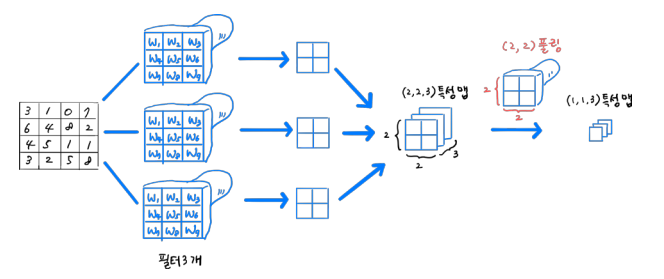
2차원 합성곱

합성곱 신경망(CNN)은 2차원도 그대로 들어와서 진행
-> 곱하고 더한다.
특성맵
합성곱 신경망의 결과가 특성맵
곱하고 더한(Convolution 한) 결과를 특성맵에 써준다.
-> (2,2) 출력된 결과가 특성맵

소벨 필터 (Sobel operator)
: 이미지의 edge를 검출해내는 필터
x filter : edge에 걸쳤을 때 큰 값이 나옴
-> 이미지 안과 밖은 0이 나오고 경계에서만 큰 출력 값이 나옴

-> 필터에 weight들을 학습시키는 게 목표
소벨 필터처럼 edge 잘 찾아낼 수 있는 값들을 만들어보라고 인공지능에게 시키는 것
여러 개의 필터
- 필터 == 뉴런
- 여러 개의 뉴런 == 여러 개의 필터
- 뉴런 안 weight == 커널

특성맵이 필터의 개수만큼 여러개 나옴
패딩 (Padding)
패딩을 하지 않으면?

곱하고 더하는 과정이 픽셀의 값이 weight에 영향을 주는 것임
3이 중요한 정보인데 weight에 한 번밖에 영향을 주지못함.
-> 최대한 모든 픽셀을 공평하게 반영되게 하려고 패딩 사용 -> 0으로 채워넣는다.
패딩을 할 경우
이러한 방식을 Same padding이라 함 (입력의 크기와 특성맵의 크기가 동일)

0으로 채워넣으면 출력도 (4,4) 특성맵으로 나와 사이즈가 유지된다.
스트라이드
몇칸씩 움직일지 결정 (몇칸씩 시프트 할 지 지정)
일반적으로 스트라이드는 1을 사용 (즉, 한 칸씩 움직이는 것이 일반적)
케라스 합성곱층 생성
Keras.layers 패키지 아래에 클래스로 구현되어 있음
• Conv2D 클래스
keras.layers.Conv2D(필터의 개수, 커널의 크기, 활성화 함수, same padding(생략시 valid padding), strides = 1))
필터 : 형태가 2차원으로 바뀐 뉴런이라 생각
stride: 1 : 몇 칸씩 움직일지 지정, 생략하면 1 (일반적으로 생략함)
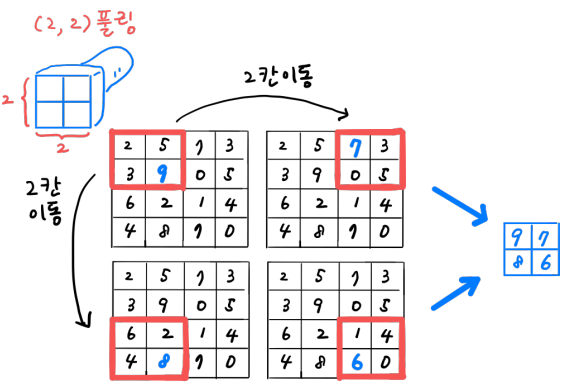
풀링 (Pooling)
- 합성곱층에서 만든 특성맵의 가로/세로 크기를 줄이는 역할
- 특성맵의 개수는 줄어들지 않음
- 풀링에는 가중치가 없음
- 최대 풀링 vs 평균 풀링
-> 각 특성맵을 기준으로 필터를 찍어내듯이 가장 큰 값만을 뽑아냄
특징점을 찾아내게 계속 학습하면서 큰 값을 남기게 학습함
최대풀링 (일반적으로 풀링의 크기는 2를 사용 (2,2))
• 스트라이드는 풀링의 크기에 따라 자동으로 설정
- (2,2) 풀링: 스트라이드 2 -> 한 번씩만 찍겠다는 의미
- (3,3) 풀링: 스트라이드 3
케라스 풀링층 생성
Keras.layers 패키지 아래에 클래스로 구현되어 있음
• MaxPooling2D
• AveragePooling2D
keras.layers.MaxPooling2D(2)
keras.layers.AveragePooling2D(2)
-> 폴링크기 (2x2)
가로, 세로 크기를 다르게 할 수도 있음 (튜플 사용)
합성곱 신명망 구조 정리

-> (4,4) 이미지 들어오고 same padding 했다 가정 (필터 거쳤을 때 사이즈 유지)
(3,3) 특성 맵 3개가 나온걸 최대 풀링시 (2,2)로 줄어든 특성맵 3장 나옴
최대값을 뽑아내는 기능
최종적으로 예측하려면 소프트맥스가 필요함
3차원 합성곱
입력의 깊이와 필터의 깊이는 항상 같아야 함 !

이미지가 3차원으로 들어오는 경우가 있음 (컬러 이미지일 때)
3차원의 input을 깊게 찌르는 느낌
-> 필터가 3차원이라도 출력은 일차원
(흑백일 경우는 reshape를 통해 의미 없는 차원 하나를 넣음)
여러 개의 필터가 있는 3차원 합성곱

-> 깊이가 5, 10개의 필터가 있으면 깊이 5인애가 10개 있는 것
CNN을 이용하여 패션 아이템을 분류해 보자
28x28 이미지
첫번째 conv2d에서 필터 32개 사용
그 후 2x2 max padding
깊이 유지, 가로 세로는 1/2로 줄어듦
두번째 conv2d는 64개의 필터, 깊이 32
특성맵은 각 한장의 필터가 만들어내 64개
깊이 64, 7x7로 줄어듦

데이터 준비

-> reshape를 해서 28*28*1 로 바꿔주기
(케라스 합성곱 층은 기본적으로 3차원 입력을 기대해 차원 늘리기)
레이어 만들기
첫 번째 합성곱 층

-> 3x3x1 필터 생성 (깊이는 자동으로) - 한장의 샘플 기준으로 3차원이니까
-> 스트라이드는 합성곱은 1, 맥스 풀링은 2
kernel_size = (3,3) 가능
두번째 합성곱 층 + 완전 연결층 (출력 층)

-> 64개의 필터 사용, kernel_size = (3,3)은 3x3x32 필터 생성 (깊이는 자동으로)
-> 분류를 위한 dense 층 + dropout 층
-> 1차원으로 나오는 특성맵 펼쳐주기
-> 10개의 확률 각각 계산
model.summary()

-> conv2d
(28, 28) -> same padding, (32) -> 32개의 필터
-> conv2d 320개 ( 1 * 3X3 * 32개 커널 + 32개 바이어스 = 320)
-> conv2d_1 18496개 ( 32 * 3*3 * 64개 커널 + 64개 바이어스 = 18496 )
-> dense layer 313700개 학습 (316*100+100)

plot_model()




결과 확인

validation loss 나옴 -> 과대적합
검증 세트 점수 확인
(현재 best model이 자동 저장되어 있음)

-> loss률과 accurancy 나옴
테스트 세트 평가

검증세트 첫번째 샘플에 대한 클래스별 확률 출력

실습 1: MNIST data set
• 60000개의 샘플 (클래스당 6000 이미지)
• 28*28 해상도 (흑백 이미지)
실습 2: CIFAR-10 data set
• 60000개의 샘플 (클래스당 6000 이미지)
• 32*32 해상도 (컬러 이미지)
• https://www.cs.toronto.edu/~kriz/cifar.html
사진 출처 : 혼자 공부하는 머신러닝 + 딥러닝 강의자료
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 20일차 - 순환신경망의 개념, RNN 드롭아웃, LSTM, 영화리뷰 분류, 로이터 기사 분류 (3) | 2024.02.07 |
|---|---|
| 19일차 - 함수형 API, 전이학습, 데이터 증대, 이미지 분류 (1) | 2024.02.06 |
| 17일차 - 크로스엔트로피, 다층 신경망 그래디언트 소멸, 하이퍼파라미터 최적화, 손실 곡선, 검증 손실, 드롭아웃, 모델 저장과 복원 (0) | 2024.02.02 |
| 16일차 - 딥러닝의 역사, 퍼셉트론, 다층 퍼셉트론, 역전파 알고리즘 상세, 활성화 함수 및 원리 (0) | 2024.02.01 |
| 15일차 - 비지도 학습, 군집 알고리즘, k-평균, 차원축소, 주성분 분석 (2) | 2024.01.31 |



