손실 함수 (Loss Function)
: 지금 weight로 만들어낸 결과값이 실제값과 얼마나 차이가 있고
차이를 줄이기 위해서는 weight를 얼마나 해야하나
선형회귀 (Linear Regression)
• 평균 제곱 오차 (Mean Squared Error, MSE)

오차가 많으면 손실함수가 내놓는 값이 크고 오차가 작으면 값이 작다.
• 로지스틱 회귀 (Logistic Regression)

이진 크로스 엔트로피 (Binary Cross Entropy)
: 이진 분류를 위한 손실함수 (로지스틱회귀를 위한 손실함수)
손실함수를 loss가 크게 나면 손실함수의 값이 크게 나오고
loss가 작게 나면 손실함수의 값이 작게 나온다.
타겟이 0일 때 로그 함수의 특성과 잘 맞다
-> 로그 함수 특성을 사용

크로스 엔트로피
다중분류를 위한 손실함수
• 크로스 엔트로피는 2개의 확률 분포 p, q에 대해서 다음과 같이 정의
- p: 타깃값
- q: 실제 출력
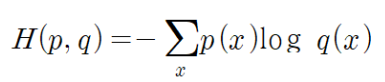
• 크로스 엔트로피가 크면, 2개의 확률 분포가 많이 다른 것
• 크로스 엔트로피가 작으면 2개의 확률 분포가 거의 일치한다고 볼 수 있 음


-> 다중분류에서의 정답은 3개 중 하나
-> 실제 타겟은 확률 분포가 하나의 클래스만 1이고 나머지는 0
-> 소프트맥수 함수 예상 출력과 실제값을 크로스 엔트로피 함수에 적용해보면 손실 함수 결과 값은 0.134901
-> 타겟값이 1에 대한 마이너스 로그만 남음

-> 하나의 원소만 1이고 나머지는 모두 0인 배열이 필요
-> one-hot 인코딩 방식으로 바꿔줘야한다.
One Hot Encoding
-> sparse를 빼고 그냥 엔트로피만 써주기
이진분류 -> loss: “binary_crossentropy”
다중분류 -> loss: “(sparse_)categorical_crossentropy”
- 타깃값이 원-핫 인코딩인 경우 : categorical_cross_entropy
- 타깃값이 정수일 경우 : sparse_categorical_crossentropy
(정리)
categorical_crossentropy
다중 분류 손실 함수
타겟을 one-hot encoding으로 표현해서 사용해야 함
sparse_categorical_crossentropy
다중 분류 손실 함수
타겟을 one-hot encoding이 아닌 integer로 표현해서 사용
binary_crossentropy
이진 분류를 위한 손실 함수
심층 신경망
: 2개의 층 (은닉층 + 출력층)
첫번째 이미지를 펼친 배열
-> 입력층 784개 뉴런
-> 은닉층 100개 뉴런
-> 출력층 10개의 뉴런(10개가 아니더라도 동작에 문제는 없다.)
데이터 준비

레이어 만들기
은닉층과 출력층 2개 만들기

-> 은닉층 : Dense(뉴런 개수100, activation='sigmoid', input_shape = (784, ))
- hidden 레이어가 0~1 사이 값 나오게 sigmoid로
- 은닉층이라 input_shape 입력의 크기 적음

-> 100개의 출력이 출력층으로 전달됨
-> 모델 파라미터 개수 = 학습하는 weight의 개수
-> 78500 : (784개 입력층 뉴런 * 100개 은닉층 뉴런(1:n으로 들어와서)) + 바어이스
--> 뉴런 개수 : 784개의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축됨을 의미
층을 추가하는 또다른 방법 #1 (Sequential 클래스 생성자 사용)

-> 원하는대로 이름 지정 가능
층을 추가하는 또다른 방법 #2 (add() 메서드 사용)

모델 설정 및 학습

-> 클래스가 10개인 다중분류
그래디언트 소멸 문제

-> 범인은 시그모이드 활성화 함수

ReLU: 새로운 활성화 함수

미분을 하더라도 기울기 항상 1
-> 정보손실이 없다.
Flatten 층
배치 차원을 제외한 나머지 입력 차원을 모두 일렬로 펼침 -> keras에서 제공하는 기능(성능에 영향 x)
• 28 * 28 -> Flatten layer -> 784 (1차원으로 reshape하는 대신 Flatten layer 넣기)
입력층과 은닉층 사이에 추가

-> 784개의 값 출력, 모델 파라미터의 개수 0 (학습하는 레이어가 아니여서)
-> 784 * 100 + 100 = 78500
ReLU 함수로 다시 학습

실제 이미지로 테스트해보자
인터넷에서 패션 아이템 이미지를 다운로드 (예: 스니커즈)
OpenCV를 이용한 전처리 필요
- 이미지를 흑백으로 변환
- 이미지 크기를 28x28로 변경
- 이미지를 반전 (255에서 각 픽셀 값을 뺌)
- 각 픽셀값을 255로 나누어서 0~1사이의 값으로 변환

분류 결과 확인


-> reshape 또 해준 이유 : 기본적으로 실제 이미지는 3차원
-> 흑백이라 1 * 28 * 28로 표시
-> batch_size = 1 : 1개의 이미지
-> argmax : 값이 가장 큰 확률의 인덱스를 리턴 -> 클래스 레이블이 된다.
실습: 타이타닉 생존자 예측하기
데이터 다운로드
https://www.kaggle.com/c/titanic/data 에서 데이터 다운로드
데이터 읽기



-> 각각을 특성으로 선별해서 사용 가능
-> 타겟을 Survived로
결측 데이터를 확인해보자

간단한 시각화


-> 성별, 티켓 클라스 로 생존률 탐색
-> 학습 전에 데이터의 특성, 형태, 구조를 찾아낼 수 있다.
데이터 전처리
-> 학습에 필요한 데이터 (성별과 티켓 클래스)를 제외한 나머지 컬럼을 삭제

-> 결측값 처리 (삭제)

-> 처리 결과 확인

-> 학습 데이터 (성별)를 정수 값으로 바꾸기

타겟 데이터 준비
• 생존 정보는 train.Survived에 저장되어있음
• 단, train.Survived는 2차원 배열임 -> 1차원 배열로 변환 (np.ravel() 함수 사용)

학습데이터에서 Survived 정보 삭제

모델 만들기

-> hidden layer 2개, 출력층 1개 추가
-> hidden layer : 16, 8개 뉴런 사용
-> 출력층 : 뉴런 1개 사용 (이진분류)
-> input_shape : 특성 2개 들어온다.
모델 설정

-> adam 사용
학습

-> verbose = 1 : 로그 찍힌다.
하이퍼 파라미터
신경망의 대표적인 하이퍼 파라미터
• Epochs : 학습 반복 횟수
- compile()의 epochs로 조절 가능
• 미니 배치 사이즈
- 케라스는 기본적으로 32
- fit()의 batch_size로 조절 가능
• 경사하강법 알고리즘
- 옵티마이저라 부름
- Default: RMSprop

SGD 옵티마이저 지정

적응적 학습률 옵티마이저

Adam

손실 (Loss) 곡선
-> epoch가 진행되면서 발생하는 손실률을 시각화
loss가 어떤 양상으로 줄어드는지 보기
데이터 준비

레이어 만들기 (함수 정의)

모델 설정 및 학습



- 손실률 (loss)는 기본적으로 계산됨
- accuracy는 compile()에서 지정되었음
- loss와 accuracy 속성은 에포크마다 계산된 값이 순서대로 저장된 단순 리스트
검증 손실
-> 에포크에 따른 과대/과소 적합
검증손실 계산


옵티마이저 변경
: RMSProp (default) -> Adam

-> 과대적합은 이뤄지고 있지만 좀 덜 벌어진다.
-> 규제로 과대적합을 막을 수 있다.
드롭아웃 (Drop Out)
학습과정에서 일정비율로 (랜덤하게) 뉴런를 선택하여 제외
-> 과대적합은 줄어들고 앙상블의 효과도 얻을 수 있다.
• 예: 첫번째 샘플을 처리할 때는 은닉층의 두번째 뉴런이 드롭아웃 되고,
두번 째 샘플을 처리할 때는 첫번째 뉴런이 드롭아웃
-> 얼마나 많은 뉴런을 드롭할지는 또 다른 하이퍼파라미터
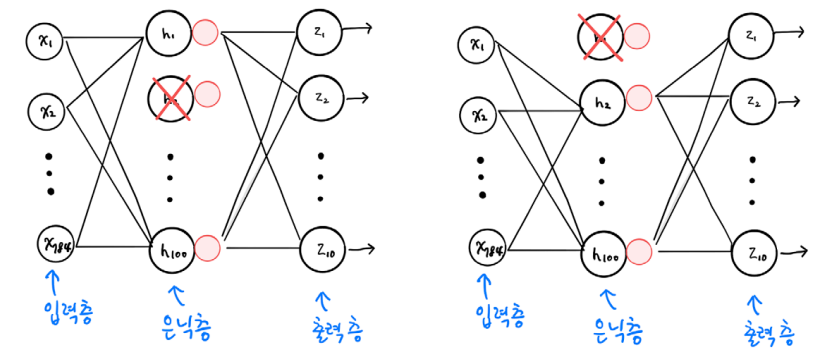
드롭아웃 실습

-> Dropout(0.3) : 30% 뉴런을 제외

-> 전체적으로 과대적합이 많이 잡힌 모습
-> 학습 완료 후에는 드롭아웃을 적용하지 말아야 함
Q: 그럼 모델 학습 후 Drop out 층을 다시 제외해야 하나요?
A: 아니오 (드롭아웃 레이어가 제외된 상태에서 평가, 예측)
모델 저장과 복원
에포크 횟수를 10으로 지정 후 다시 학습 후 파라미터/모델 저장

-> model.save_weights : 파일명을 지정해서 가중치 저장 가능
-> model.save : 모델 구성 자체를 저장 (그대로 복원 가능)
-> ! 를 앞에 붙이면 클라우드가 돌고있는 리눅스 쉘에 접속
파라미터 복원

-> load_weights() : save_weights()메소드로 저장했던 모델과 동일한 구조를 가져야함
+ compile 한 번 해줘야함

모델 전체를 복원

-> compile 해줄 필요 없다.
콜백 (Callback)
: 학습 과정 중간에 다른 작업을 수행할 수 있게 하는 객체
ModelCheckpoint 콜백
• 최상의 검증 점수를 만드는 모델을 자동으로 저장
(가장 좋은 점수를 낸 weight를 지정한 파일명에 저장해줌)
-> keras.callbacks.ModelCheckpoint('파일명', save_best_only = True)


-> load_model 로 복원 가능
-> 복원된 weight로 평가 가능
조기 종료 (Early Stopping)
검증 점수가 상승하기 시작하면
그 이후에는 과대적합이 더 커지기 때문 에 훈련을 계속할 필요가 없음
-> 과대적합이 시작되기 전에 학습을 중지 : Early stopping
EarlyStopping 콜백
• patience: n번 연속 검증점수가 향상되지 않으면 학습을 중지 (몇 번 동안 지켜볼지)
- E.g., patience = 2 : 2번 연속 검증 loss가 낮아지지 않으면 2칸 전으로 돌아가서 학습 중지
• restore_best_weights = True
: True 설정 시 가장 낮은 검증 손실 (가장 성능 좋은) 모델 파라미터로 되돌림
• 보통 ModelCheckpoint 콜백과 함께 사용

-> epoch 5부터 val_loss 다시 증가하니
epoch 더이상 진행하지 않고 2개 전 0.3420 정보 저장



사진 출처 : 혼자 공부하는 머신러닝 + 딥러닝 강의자료
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 19일차 - 함수형 API, 전이학습, 데이터 증대, 이미지 분류 (1) | 2024.02.06 |
|---|---|
| 18일차 - 합성곱 신경망의 개념, 2차원 합성곱, 3차원 합성곱, 합성곱 신경망 시각화 (0) | 2024.02.05 |
| 16일차 - 딥러닝의 역사, 퍼셉트론, 다층 퍼셉트론, 역전파 알고리즘 상세, 활성화 함수 및 원리 (0) | 2024.02.01 |
| 15일차 - 비지도 학습, 군집 알고리즘, k-평균, 차원축소, 주성분 분석 (2) | 2024.01.31 |
| 14일차 - 경사하강, 결정트리, 앙상블 학습, 랜덤 포레스트, 교차검증과 그리드 서치 (1) | 2024.01.30 |



