순차 데이터 (Sequential Data)
: 텍스트, 시계열
순서가 의미를 가져 순서에 따라 말이 달라질 수 있음
순환 신경망 (RNN) vs 피드-포워드 신경망

순환 신경망 : 나가는 출력에 weight가 있어서 그 weight를 기억
순환 신경망 (Recurrent Neural Network, RNN)
지나간 정보가 기억 되어야할 필요가 있다.
기억 -> 순환으로 표현

셀 == 순환 층
순환층의 활성화 출력 == 은닉상태
(각각의 셀이 순환이 된다. -> 활성화 함수 (tanh) 사용)
타임스텝으로 펼친 신경망
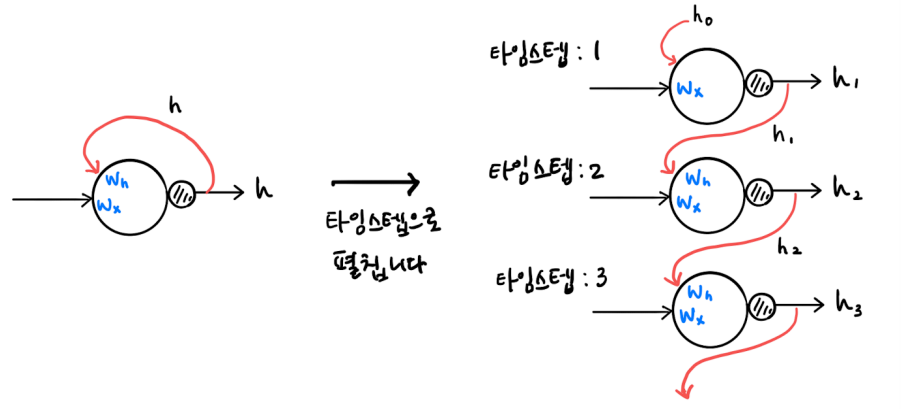
순환 신경망의 가중치

은닉 상태의 순환 : 셀 안에 그물처럼 엉키기
순환 신경망의 입력과 출력

단어 == 토큰
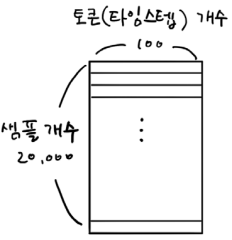
시퀀스 길이(타임스텝) == 단어 길이
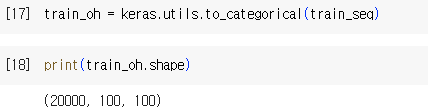
하나하나가 특성 -> 현재 4개의 특성
각각의 단어가 들어갈 때 곱하고 더해짐
누적만 하다가 샘플이 끝난 순간
셀 안에 뉴런의 개수에 맞는 출력 하나가 나옴
은닉상태의 출력

모든 특성이 곱해지고 더해져서 영향을 누적하여 다 주고나서
마지막에 하나 출력
순환 신경망 구조
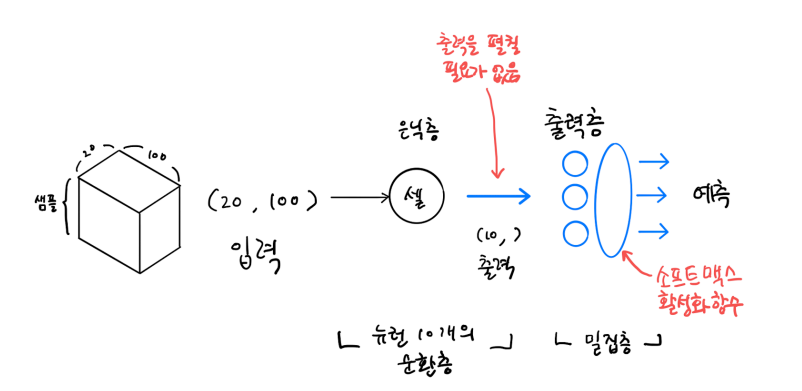
각각의 샘플은 20단어로 이루어져있고
각각의 단어가 다 정수값으로 표현되어 있다고 가정 했을 때
100길이의 벡터로 표현되었다.
셀끼리 순환이 되다가 다중분류를 원하면 소프트맥스 활성화 함수 출력층 통과,
이진분류가 필요하면 시그모이드 함수로 출력층 통과
영화 리뷰 분류해보기 (긍정리뷰/부정리뷰)
※ 주요 용어정리
NLP (자연어처리) : 음석인식, 기계번역, 감성 분석 등
말뭉치 (corpus) : NLP에서의 학습데이터를 의미
토큰 : 공백으로 분리된 단어 (본 예제에서는 타임스텝에 해당됨)
어휘사전 : 훈련세트에서 분석에 사용할 고유한 단어를 뽑아만든 목록을 의미
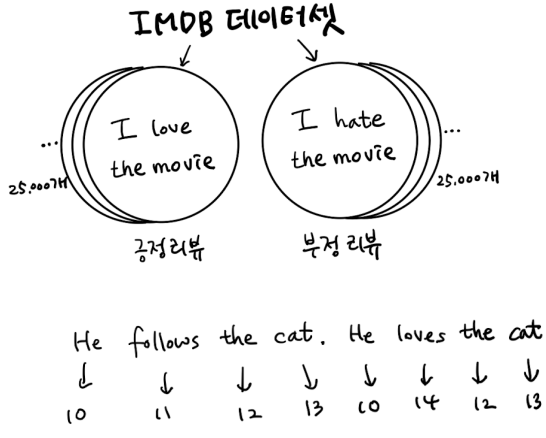
-> 0~3는 특수 목적으로 예약되어 있음
0: 패딩
1: 문장의 시작
2: 어휘 사전에 없는 토큰 (어휘사전에 없으면 다 2)
3: 사용되지 않음
데이터 준비

-> num_words = 100 : 전체 데이터 셋에서 자주 등장하는 상위 100개 단어
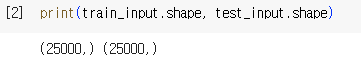
-> 25000개씩 train, test로 나눠져있음 (총 50000개)


-> len(train_input[0]) : 첫번째 리뷰의 단어 개수
-> 128개의 토큰으로 구성 (128개의 단어로 구성된 리뷰)
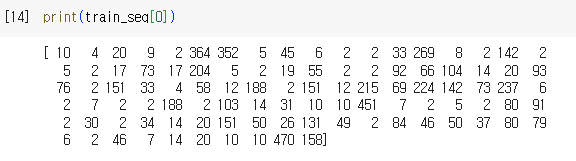
첫번째 리뷰 데이터

타겟 확인
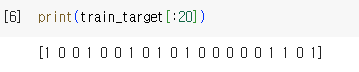
-> 긍정(1) or 부정(0): 이진 분류
잠깐! 리뷰 원본 데이터를 복원하는 방법

-> 실습을 이어서 진행하기 위해서는 imdb.load_data(num_words=500 을 사용)
학습, 검증 데이터 분리 및 시각화

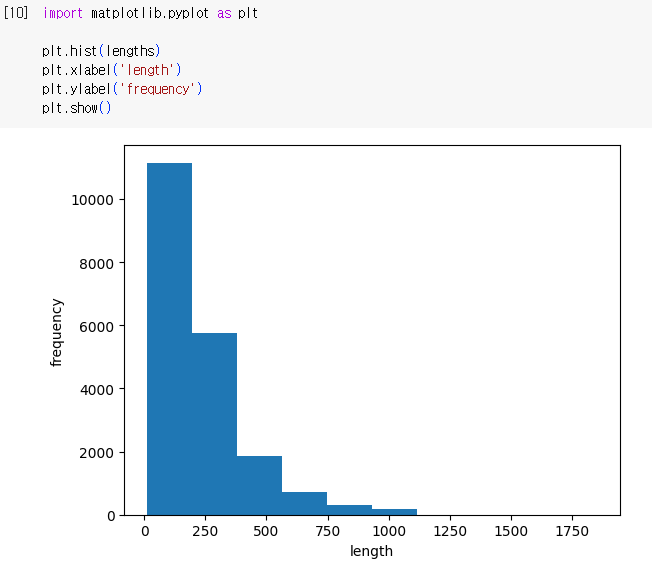
-> 리뷰(lengths) 길이가 제각각
-> 2대 8로 나눠서 샘플 개수 20000개
-> 리뷰 길이를 동일한 사이즈로 단어 100개로 맞추자
시퀀스 패딩


-> maxlen = 100 : 100개의 토큰만 사용 (모든 샘플 길이가 100)
(100개 보다 큰 리뷰 : 나머지 토큰 삭제, 100개보다 작은 리뷰 : Zero 패딩)
-> 검증 데이터에 대해서도 처리해야 함
100 토큰 (단어)보다 긴 리뷰: 토큰 삭제
100 토큰 (단어)보다 짧은 리뷰 : Zero 패딩

-> 앞에 0으로 날린다.

-> pad_sequences() 함수는 기본적으로 maxlen보가 긴 시퀀스의 앞부분을 잘라냄
(뒷부분을 잘라내고 싶다면?
pad_sequence() 함수의 truncating 매개변수 값을 'post’로!! (기본값: ‘pre’))
RNN 모델 만들기

-> SimpleRNN 클래스의 activation 매개변수 기본값은 ‘tanh’
원-핫 인코딩 수행 (왜 해야할까?)
: 하나의 원소만 1 나머지는 0으로



-> 전체 비트 중 1은 하나 (11번째 1)

-> 검증 데이터세트도 원-핫 인코딩 처리해야 함!!
학습하기 및 평가
옵티마이저 및 콜백 설정 후 학습


-> 곱하고 더하고 순환하고 해서 샘플을 하나씩 처리하고 모아서 한 번에 보냄
추가내용: 워드 임베딩 (Word Embedding)

추가내용: 2개의 층을 연결하기
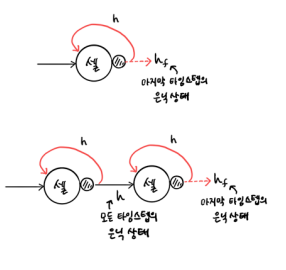

Long Short Term Memory (LSTM)
기본 RNN은 시퀀스 길이가 길 경우 성능이 저하되는 문제가 있음
- 타임스텝이 길어질수록 이전에 입력되었던 정보가 사라짐
- 이러한 문제를 해결하기 위해 개발된 순환신경망 구조가 LSTM
- 최근 가장 많이 사용되고 있는 RNN 모델이라 할 수 있음

-> 녹색이 컨베이어 벨트처럼 스텝이 올 때마다 도는 것
그 값 그대로가 유지되면서 매번 곱해져 누적되는 것
LSTM 모델을 만드는 방법은 아주 간단함!
기존 SimpleRNN 클래스 대신 LSTM 클래스를 사용하면 끝!
• 이후 학습과정은 기본 RNN과 완전히 동일함

추가내용: RNN에 Dropout 적용하기

참고: SimpleRNN의 경우에도 dropout을 적용하는 방법은 동일
실습 : 로이터 기사 분류하기
11228개의 뉴스 기사 텍스트 데이터 셋
(42개의 카테고리)
모델 구성 조건
- 어휘사전 크기 1000
- 20% 검증 세트
- 시퀀스 데이터 길이 80
- LSTM 또는 Simple RNN 사용
- activation 함수 tanh
- 워드임데딩 사용
- 워드임베딩 벡터 크기는 32로 설정 (다른 값으로 해도 됨)
- 신경망 구성 및 하이퍼파라미터는 자유롭게 사용
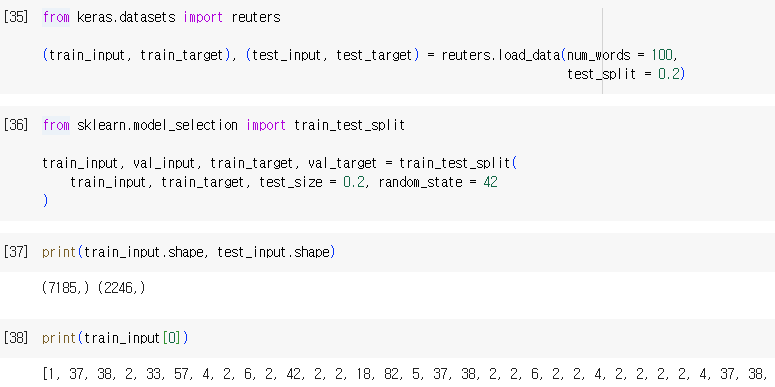

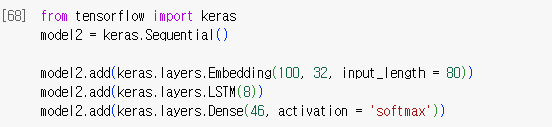

사진 출처 : 혼자 공부하는 머신러닝 + 딥러닝 강의자료
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| beautifulsoup 기본 및 응용, 토큰화, 정규화, konlpy, wordcloud (0) | 2024.06.28 |
|---|---|
| 파이썬 문법 보충, 데이터 분석 라이브러리 (1) | 2024.06.28 |
| 19일차 - 함수형 API, 전이학습, 데이터 증대, 이미지 분류 (1) | 2024.02.06 |
| 18일차 - 합성곱 신경망의 개념, 2차원 합성곱, 3차원 합성곱, 합성곱 신경망 시각화 (0) | 2024.02.05 |
| 17일차 - 크로스엔트로피, 다층 신경망 그래디언트 소멸, 하이퍼파라미터 최적화, 손실 곡선, 검증 손실, 드롭아웃, 모델 저장과 복원 (0) | 2024.02.02 |



