문장 토큰화
import nltk
from nltk.tokenize import WordPunctTokenizer, sent_tokenize, word_tokenize
#nltk.download("punkt")
# 문장 토큰화
sentence = "The cat (Felis catus), commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae. "
kor_sent = "일반적으로 집고양이 또는 집고양이라고 하는 고양이(Felis catus)는 작은 길들여진 육식성 포유류입니다. 그것은 Felidae 계통의 유일한 길들여진 종입니다. "
# 마침표, 느낌표, 물음표를 기준으로 구분
token_sent = sent_tokenize(sentence)
print(sent_tokenize(sentence))
# 단어 토큰화
word_tok = word_tokenize(sentence)
kor_word_tok = word_tokenize(kor_sent)
print(word_tok)
print(WordPunctTokenizer().tokenize(sentence)) # 기호분리
import nltk
from nltk.tokenize import WordPunctTokenizer, sent_tokenize, word_tokenize 선언
WordPunctTokenizer()
단어 및 구두점을 분리하는 데 사용
이 토크나이저는 단어와 구두점의 경계를 기준으로 텍스트를 분할
주로 문장 내부의 단어와 구두점을 개별 토큰으로 분리하는 데 유용
sent_tokenize
텍스트를 문장 단위로 분리하는 데 사용
이 토크나이저는 텍스트를 문장의 경계를 기준으로 분할
주로 긴 텍스트를 개별 문장으로 분리할 때 유용
word_tokenize
텍스트를 단어 단위로 분리하는 데 사용
기본적으로 공백과 구두점을 기준으로 단어를 분리
WordPunctTokenizer와 비슷하지만, 조금 더 정교한 규칙을 사용하여 토큰화를 수행
패턴 찾기 방법
re.findall 함수
정규 표현식을 사용하여 주어진 문자열에서
패턴과 일치하는 모든 부분 문자열을 찾아 리스트로 반환
대괄호 안의 값만 남겨두고 나머지는 지움
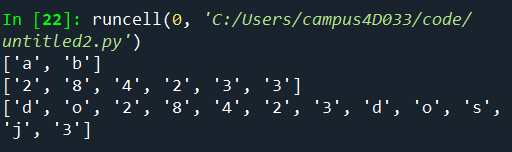
import re
print(re.findall("[abc]", "How are you, boy?"))
print(re.findall("[0123456789]", "do28423dosj3"))
print(re.findall("[0-9a-z]", "do28423dosj3"))
# [0~9]를 제외한 값을 삭제하여 출력
re.findall("[_]+", "a_b, c__d, e___F")
# 대괄호 안에 들어가는 것이 기준
# [_]+는 하나 이상의 밑줄이 연속된 부분을 찾음
자연어 처리의 기본적인 전처리의 전처리
대문자, 소문자 처리 (문자열 통)
-> 정규화 수행 (다 대문자 or 다 소문자로 변경)
문단의 첫 문장은 보통 대표 문장
print(re.findall("[o]{2,4}", "oh, hoow are yoooou, booooooy"))

-> o가 최소 2개부터 4개까지 반복되는 것을 출력
정규표현식
NLTK(Natural Language Toolkit) 라이브러리에서 제공하는 정규 표현식 기반의 토크나이저
사용자가 지정한 정규 표현식을 기준으로 텍스트를 토큰(token)으로 분리하는 기능을 제공
정규 표현식 패턴 설명
- [\w']+ 패턴 구성
- [\w]: \w는 단어 문자를 의미하며, [ ] 안에 있는 것은 문자 클래스를 형성 -> 알파벳 문자나 숫자를 의미합니다.
- ': 작은따옴표(')는 그 자체로 매칭
- +: +는 앞의 패턴이 하나 이상 연속해서 나오는 경우를 의미 (하나 이상의 단어 문자 또는 작은따옴표가 연속된 부분을 찾음)
from nltk.tokenize import RegexpTokenizer
rg_token = RegexpTokenizer("[\w']+")
# 문자, 숫자, _를 포함하고 나머지 내용들은 다 삭제
print(rg_token.tokenize("It's very good."))
소문자로 변경
sent1 = "It's very good. Oh! yes~ haha. ki-ki"
print(rg_token.tokenize(sent1.lower()))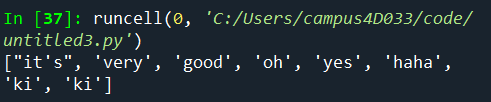
특수문자 제거 + 각각의 의미 있는 단어로 분류
[\w']){3,} # 괄호안에 있는 숫자를 기준으로 이상인 것만 추려서 보여줌
from nltk.tokenize import RegexpTokenizer
rg_token1 = RegexpTokenizer("[\w']+")
rg_token2 = RegexpTokenizer("[\w']{3,}")
rg_token3 = RegexpTokenizer("[\w]+") # '제외
# 문자, 숫자, _를 포함하고 나머지 내용들은 다 삭제
# [\w']){3,} # 괄호안에 있는 숫자를 기준으로 이상인 것만 추려서 보여줌
sent1 = "It's very good. Oh! yes~ haha. ki-ki"
print(rg_token1.tokenize(sent1))
print(rg_token2.tokenize(sent1))
print(rg_token3.tokenize(sent1))
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
# corpus : 말뭉치
en_stop = set(stopwords.words('english'))
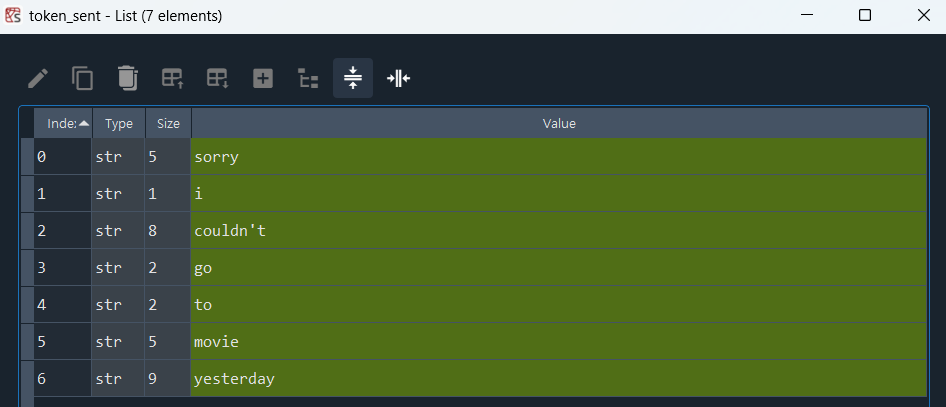
text1 = "Sorry, I couldn't go to movie yesterday"
# 불용어(무시되거나 제거되는 단어 )로 사용할 단어 리스트에 넣어서 사용
my_stop = ["i", "go"]
# 전처리
re_tok = RegexpTokenizer("[\w']+")
token_sent = re_tok.tokenize(text1.lower()) # 소문자로 바꿔서 전처리
# 결과물
result_tok = [word for word in token_sent if word not in en_stop]
# NLTK 불용어 처리
my_stop_result = [word for word in token_sent if word not in my_stop]
# my_stop을 사용하여 사용자 정의 불용어 처리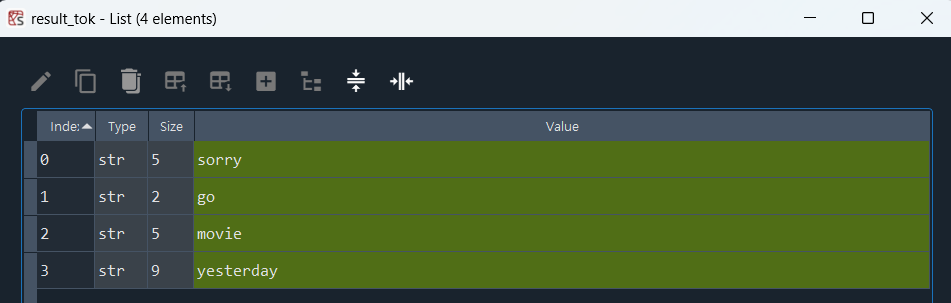
기본 정규화 (Stem & Lemma)
-> 자연어 처리에서 텍스트를 일관되게 만들어주는 과정
1) 어간 추출 Stem
단어의 접미사(suffix)를 제거하여 기본적인 형태를 만드는 과정
ex) cook, cooking, cooker -> cook 원래의 형태로 축소
from nltk.stem import PorterStemmer, LancasterStemmer
p_stem = PorterStemmer()
print(p_stem.stem('cooking'))
print(p_stem.stem('cook'))
print(p_stem.stem('cookery'))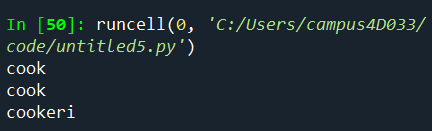
from nltk.stem import PorterStemmer, LancasterStemmer
from nltk.tokenize import word_tokenize
l_stem = LancasterStemmer()
text1 = "The cat (Felis catus), commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae. Recent advances in archaeology and genetics have shown that the domestication of the cat occurred in the Near East around 7500 BC. It is commonly kept as a house pet and farm cat, but also ranges freely as a feral cat avoiding human contact."
w_token = word_tokenize(text1.lower())
result = [ l_stem.stem(word) for word in w_token ]
2) 표제어 추출 Lemma
Lemma는 단어의 사전적인 기본 형태(원형) 찾는 과정
ex) running, runs, runner -> run 기본형으로
ex) 작다, 작은, 작거나 -> 작다 기본형으로
from nltk.stem import WordNetLemmatizer
w_lemma = WordNetLemmatizer()
print(w_lemma.lemmatize('cooking'))
print(w_lemma.lemmatize('cooking', pos = 'v')) # 동사형태
print(w_lemma.lemmatize('cook'))
print(w_lemma.lemmatize('cookery'))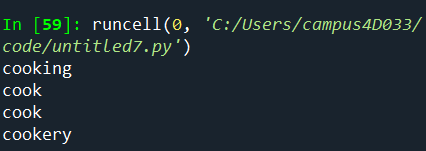
ctrl + 1 : 전체 주석
품사
: 각 단어가 문장에서 어떤 역할을 하는지를 나타내는 언어학적인 범주
품사 태깅(Pos tagging)
- 의미: 각 단어에 해당하는 품사(명사, 동사, 형용사 등)를 자동으로 부착하는 작업
- 사용: 품사 태깅을 통해 문장의 구조를 분석하거나 문맥을 이해하는 데 도움을 줌
- 예를 들어, "The cat sits on the mat"에서 "cat"은 명사(NN), "sits"는 동사(VB), "on"은 전치사(IN) 등으로 태깅됨
- 함수: 대표적으로 NLTK의 pos_tag 함수를 사용하여 품사 태깅을 수행 가능
태그 정보
https://happygrammer.github.io/nlp/postag-set/
import nltk
from nltk.tokenize import word_tokenize
text1 = "The cat (Felis catus), commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae."
w_token = word_tokenize(text1.lower())
print(nltk.pos_tag(w_token)) # 태그 정보 출력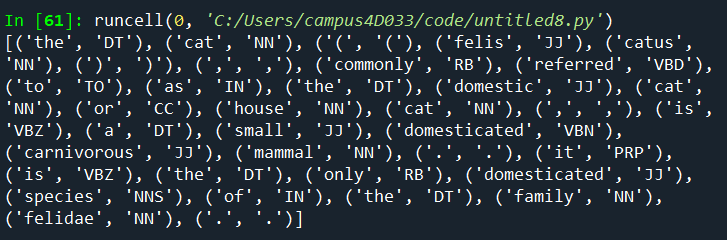
++)
해당 인덱스 값을 가져와서 밸류와 비교하여 리스트에는 키를 넣기
-> for문 + if문 사용
import nltk
from nltk.tokenize import word_tokenize
text1 = "The cat (Felis catus), commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae."
w_token = word_tokenize(text1.lower())
print(nltk.pos_tag(w_token)) # 태그 정보 출력
my_tag = ['NN', 'NNS', 'NNP']
my_word = [word for word, tag in nltk.pos_tag(w_token) if tag in my_tag]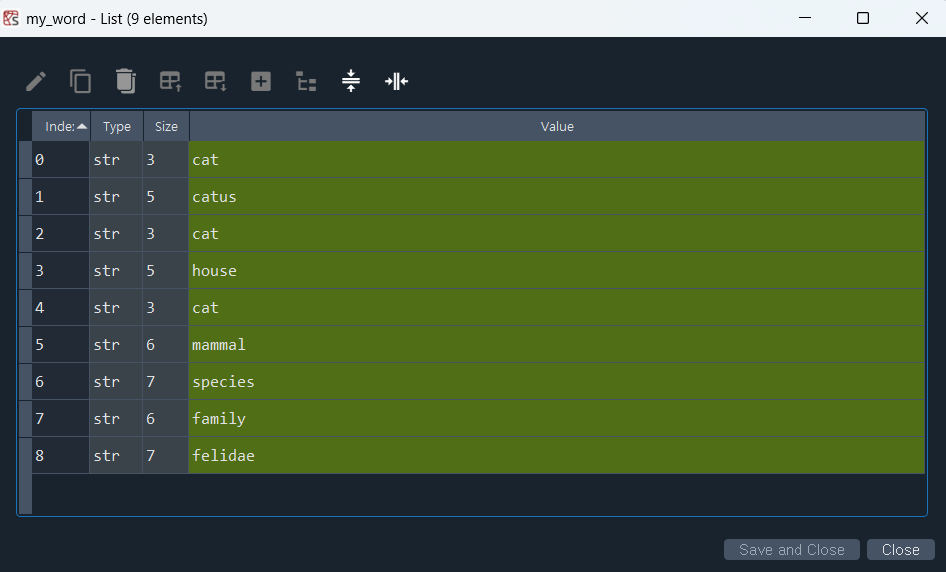
++)
서로 다른 두 데이터를 연결시킨다는 조인
import nltk
from nltk.tokenize import word_tokenize
text1 = "The cat (Felis catus), commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal. It is the only domesticated species of the family Felidae."
w_token = word_tokenize(text1.lower())
print(nltk.pos_tag(w_token)) # 태그 정보 출력
my_tag = ['NN', 'NNS', 'NNP']
#my_word = [word for word, tag in nltk.pos_tag(w_token) if tag in my_tag]
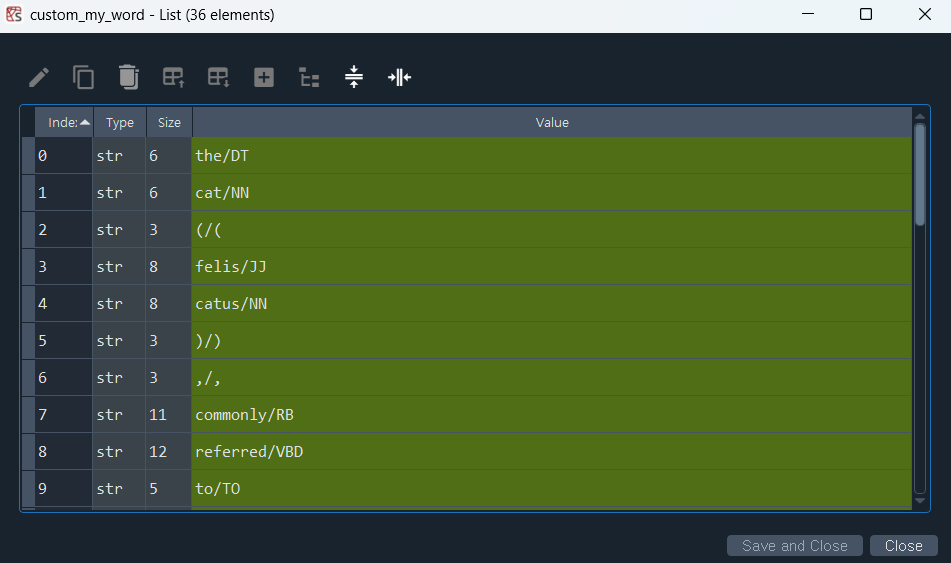
custom_my_word = ['/'.join(item) for item in nltk.pos_tag(w_token)]
konlpy
konlpy 사용해보기
import nltk
from nltk.tokenize import word_tokenize
import konlpy
from konlpy.tag import Okt
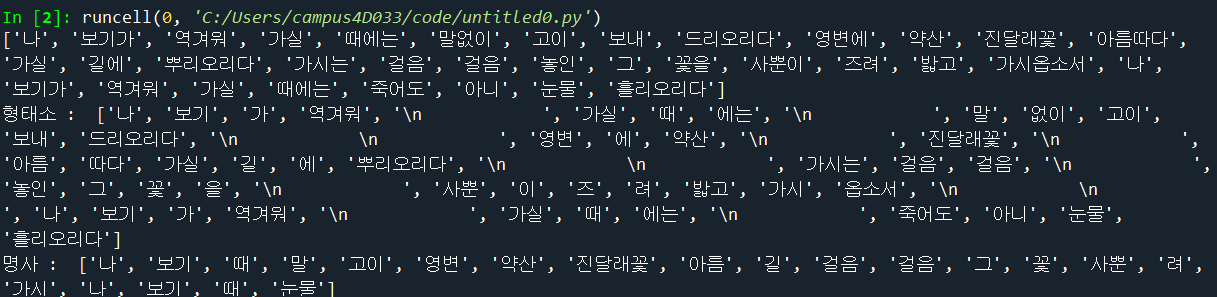
text1 = ''' 나 보기가 역겨워
가실 때에는
말없이 고이 보내 드리오리다
영변에 약산
진달래꽃
아름따다 가실 길에 뿌리오리다
가시는 걸음 걸음
놓인 그 꽃을
사뿐이 즈려 밟고 가시옵소서
나 보기가 역겨워
가실 때에는
죽어도 아니 눈물 흘리오리다'''
print(word_tokenize(text1))
t = Okt()
print("형태소 : ", t.morphs(text1))
print("명사 : ", t.nouns(text1))
데이터 전처리 및 시각화 실습
nltk 라이브러리의 gutenberg에서
햄릿 3글자 이상만 추출하여 내림차순 카운트 + 시각화
import nltk
from nltk.corpus import gutenberg
from nltk.tokenize import word_tokenize, RegexpTokenizer
from nltk.stem import PorterStemmer
p_stem = PorterStemmer()
file_name = gutenberg.fileids()
# print(file_name) # gutenberg 파일 이름 확인
# 햄릿 데이터 불러오기
doc_hamlet = gutenberg.open('shakespeare-hamlet.txt').read()
print("#Number of Characters used:", len(doc_hamlet))
# print(doc_hamlet[:100]) # 슬라이싱 가능
# 토큰화
token_hamlet = word_tokenize(doc_hamlet)
stem_token_ham = [p_stem.stem(token) for token in token_hamlet]
# 정규화를 사용해서 데이터 전처리
rege_token = RegexpTokenizer("[\w']{3,}") # 3글자 이상 단어들만 추출
reg_token_ham = rege_token.tokenize(doc_hamlet.lower())
from nltk.corpus import stopwords
en_stop = set(stopwords.words('english')) # 영어만 선택
# stopword 제외한 단어들 추출
result_ham = [word for word in reg_token_ham if word not in en_stop]
# count 세기
ham_word_cnt = dict() # 딕셔너리 형태로 만들기
for word in result_ham:
ham_word_cnt[word] = ham_word_cnt.get(word, 0) + 1
print(len(ham_word_cnt))
# count 한 것 키값을 기준으로 내림차순 정렬
sorted_ham = sorted(ham_word_cnt, key = ham_word_cnt.get, reverse=True)
# 정리된 데이터 key값으로 확인
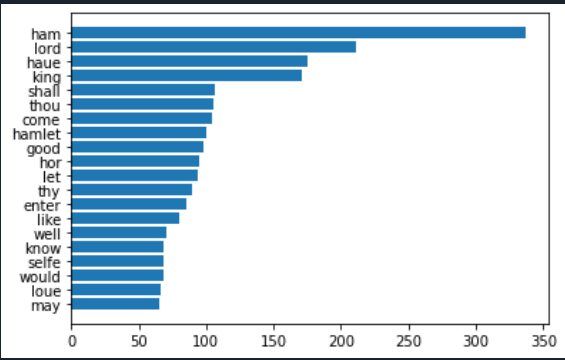
for key in sorted_ham[:20]:
print(f'{repr(key)} : {ham_word_cnt[key]}', end=', ')
# 시각화
import matplotlib.pyplot as plt
w = [ham_word_cnt[key] for key in sorted_ham]
plt.plot(w)
plt.show()
# 상위 n개의 데이터 보여주기 코드
n = sorted_ham[:20][::-1]
w = [ham_word_cnt[key] for key in n]
plt.barh(range(len(n)), w, tick_label = n)
plt.show()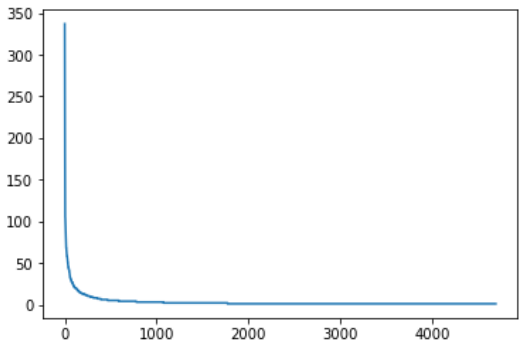
++)
wordcloud 추가
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 28 16:01:25 2024
@author: campus4D033
"""
import nltk
from nltk.corpus import gutenberg
from nltk.tokenize import word_tokenize, RegexpTokenizer
from nltk.stem import PorterStemmer
p_stem = PorterStemmer()
file_name = gutenberg.fileids()
# print(file_name) # gutenberg 파일 이름 확인
# 햄릿 데이터 불러오기
doc_hamlet = gutenberg.open('shakespeare-hamlet.txt').read()
print("#Number of Characters used:", len(doc_hamlet))
# print(doc_hamlet[:100]) # 슬라이싱 가능
# 토큰화
token_hamlet = word_tokenize(doc_hamlet)
stem_token_ham = [p_stem.stem(token) for token in token_hamlet]
# 정규화를 사용해서 데이터 전처리
rege_token = RegexpTokenizer("[\w']{3,}") # 3글자 이상 단어들만 추출
reg_token_ham = rege_token.tokenize(doc_hamlet.lower())
from nltk.corpus import stopwords
en_stop = set(stopwords.words('english')) # 영어만 선택
# stopword 제외한 단어들 추출
result_ham = [word for word in reg_token_ham if word not in en_stop]
# count 세기
ham_word_cnt = dict() # 딕셔너리 형태로 만들기
for word in result_ham:
ham_word_cnt[word] = ham_word_cnt.get(word, 0) + 1
print(len(ham_word_cnt))
# count 한 것 키값을 기준으로 내림차순 정렬
sorted_ham = sorted(ham_word_cnt, key = ham_word_cnt.get, reverse=True)
# 정리된 데이터 key값으로 확인
for key in sorted_ham[:20]:
print(f'{repr(key)} : {ham_word_cnt[key]}', end=', ')
# 시각화
import matplotlib.pyplot as plt
w = [ham_word_cnt[key] for key in sorted_ham]
plt.plot(w)
plt.show()
# 상위 n개의 데이터 보여주기 코드
n = sorted_ham[:20][::-1]
w = [ham_word_cnt[key] for key in n]
plt.barh(range(len(n)), w, tick_label = n)
plt.show()
# wordcloud 시각화 추가
from wordcloud import WordCloud
wc = WordCloud().generate(doc_hamlet)
plt.axis("off")
plt.imshow(wc, interpolation='biLinear')
plt.show()

한국어 wordcloud
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 28 17:08:03 2024
@author: campus4D041
"""
#한글 워드 클라우드
from konlpy.corpus import kolaw
const_doc = kolaw.open('constitution.txt').read()
print(type(const_doc)) #가져온 데이터의 type을 확인
print(len(const_doc))
print(const_doc[:600])
from konlpy.tag import Okt
t = Okt()
tokens_const = t.morphs(const_doc) #형태소 단위로 tokenize
print('#토큰의 수:', len(tokens_const))
print('#앞 100개의 토큰')
print(tokens_const[:100])
tokens_const = t.nouns(const_doc) #형태소 단위로 tokenize 후 명사만 추출
print('#토큰의 수:', len(tokens_const))
print('#앞 100개의 토큰')
print(tokens_const[:100])
tokens_const = [token for token in tokens_const if len(token) > 1]
print('#토큰의 수:', len(tokens_const))
print('#앞 100개의 토큰')
print(tokens_const[:100])
from matplotlib import font_manager, rc
import matplotlib.pyplot as plt
import platform
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
# 맥인 경우에는 아래와 같이 font_name을 지정
# font_name = 'AppleGothic'
rc('font', family=font_name)
const_cnt = {}
for word in tokens_const:
const_cnt[word] = const_cnt.get(word, 0) + 1
def word_graph(cnt, max_words=10):
sorted_w = sorted(cnt.items(), key=lambda kv: kv[1])
print(sorted_w[-max_words:])
n, w = zip(*sorted_w[-max_words:])
plt.barh(range(len(n)),w,tick_label=n)
#plt.savefig('bar.png') # 필요한 경우, 그래프를 이미지 파일로 저장한다.
plt.show()
word_graph(const_cnt, max_words=20)
from wordcloud import WordCloud
font_path = 'c:/Windows/Fonts/HMKMRHD.ttf'
# 맥인 경우에는 아래와 같이 font_path를 지정
# font_path = 'AppleGothic'
wordcloud = WordCloud(font_path = font_path).generate(const_doc)
plt.axis("off")
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
wordcloud = WordCloud(
font_path = font_path,
max_font_size = 100,
width = 800, #이미지 너비 지정
height = 400, #이미지 높이 지정
background_color='white', #이미지 배경색 지정
max_words=50)
wordcloud.generate_from_frequencies(const_cnt) #원문이 아닌 형태소 분석 결과로부터 워드클라우드를 생성
wordcloud.to_file("const.png") #생성한 이미지를 파일로 저장
plt.axis("off")
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()

'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 통계의 종류, 히트맵, 람다함수, 이항분포, 베르누이분포, 기하분포 (1) | 2024.07.02 |
|---|---|
| 상관관계 확인, OpenAPI 사용, beautifulsoup, Selenium, 통계 분석 개념 및 정리 (0) | 2024.07.01 |
| 파이썬 문법 보충, 데이터 분석 라이브러리 (1) | 2024.06.28 |
| 20일차 - 순환신경망의 개념, RNN 드롭아웃, LSTM, 영화리뷰 분류, 로이터 기사 분류 (2) | 2024.02.07 |
| 19일차 - 함수형 API, 전이학습, 데이터 증대, 이미지 분류 (1) | 2024.02.06 |



