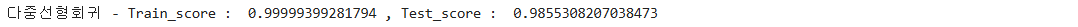주성분 분석(PCA)은 고차원 데이터의 차원을 축소하고 데이터의 주요 특성을 추출하기 위해 사용되는 기법
PCA의 주요 목적과 과정을 이해하는 것은 데이터 분석과 머신러닝에서 매우 중요
PCA의 목적
차원 축소: 데이터의 차원을 줄이면서도 정보 손실을 최소화하고 데이터의 주요 패턴을 유지
데이터 시각화: 고차원 데이터를 2D 또는 3D 공간에 시각화하여 데이터를 이해하기 쉽게 만든다.
잡음 제거: 데이터의 변동성에서 잡음이나 불필요한 정보를 제거하여 더 간결한 모델을 만든다.
특성 선택: 데이터의 주요 특성을 파악하고, 데이터 분석이나 머신러닝 모델의 성능을 개선한다.
PCA의 주요 개념
주성분 (Principal Components):
데이터의 분산을 최대화하는 새로운 축을 의미
첫 번째 주성분은 데이터의 분산을 최대화하는 방향이며, 두 번째 주성분은 첫 번째 주성분과 직교하는 방향
주성분은 데이터의 방향을 변경하고, 데이터를 새로운 좌표계에서 표현
분산과 공분산:
PCA는 데이터의 분산과 공분산을 이용하여 주성분을 찾는다.
공분산 행렬을 분석하여 데이터의 주요 축을 결정.
고유값과 고유벡터:
공분산 행렬의 고유값과 고유벡터를 계산하여 주성분을 찾는다.
고유값은 주성분의 중요도를 나타내며, 고유벡터는 주성분의 방향을 나타낸다.
기본 산점도와 PCA 산점의 차이 비교
1. 산점도 시각화
목적: Sepal Length와 Sepal Width 간의 관계를 시각화하여 각 품종의 데이터 분포를 시각적으로 비교.
제한점: 두 개의 특성(변수)만 시각화하기 때문에, 데이터의 전체적인 구조나 다른 특성들 간의 관계는 반영하지 않는다. 데이터의 차원이 늘어나면, 산점도로 시각화하기 어려운 경우가 많다.
특성 간 관계: sepal length (cm)와 sepal width (cm)의 관계를 보여준다. 각 클래스(Iris 품종)에 따라 데이터 포인트가 어떻게 분포되어 있는지 시각적으로 확인할 수 있다.
클러스터링: 데이터 포인트가 클래스별로 얼마나 잘 분리되는지를 시각적으로 평가할 수 있다. 예를 들어, setosa는 versicolor와 virginica와 비교했을 때 잘 분리되는지 확인할 수 있다.
특성 중요도: sepal length와 sepal width가 데이터의 군집 분리에 어떤 영향을 미치는지 볼 수 있다.
import sklearn
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 데이터 로드
iris = load_iris() # Iris 데이터셋을 로드합니다.
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names) # 데이터를 DataFrame으로 변환합니다.
iris_df['target'] = iris.target # 데이터프레임에 타겟(클래스) 컬럼을 추가합니다.
# 마커 설정
markers = ["*", "s", "o"] # 각 클래스에 대해 사용할 마커 스타일을 정의합니다.
# 산점도 그리기
for i, marker in enumerate(markers):
# 각 클래스에 대해 Sepal Length와 Sepal Width 값을 추출합니다.
x_val = iris_df[iris_df["target"] == i]["sepal length (cm)"]
y_val = iris_df[iris_df["target"] == i]["sepal width (cm)"]
# 각 클래스에 대해 다른 마커 스타일로 산점도를 그립니다.
plt.scatter(x_val, y_val, marker=marker, label=iris.target_names[i])
# 레전드 및 라벨 설정
plt.legend() # 그래프에 범례를 추가하여 각 마커가 어떤 클래스를 의미하는지 표시합니다.
plt.xlabel("sepal length (cm)") # x축 레이블을 설정합니다.
plt.ylabel("sepal width (cm)") # y축 레이블을 설정합니다.
plt.title("Iris Dataset: Sepal Length vs Sepal Width") # 그래프 제목을 설정합니다.
plt.show() # 그래프를 화면에 출력합니다.
2. PCA (주성분 분석)
목적: 고차원 데이터(여기서는 4차원: Sepal Length, Sepal Width, Petal Length, Petal Width)의 차원을 축소하여 데이터의 주요 패턴을 시각화한다. PCA는 데이터의 주요 변동성을 잡아내는 새로운 축(주성분)을 찾아내어 시각화할 수 있다.
장점: 데이터의 차원을 줄이면서도 가장 많은 정보를 유지할 수 있다. PCA를 통해 데이터의 주요 방향성을 파악하고, 데이터의 복잡한 패턴을 2D 또는 3D 시각화로 분석할 수 있다. 예를 들어, 4차원 데이터를 2차원으로 축소하여 각 샘플을 2D 산점도로 표현할 수 있다.
차원 축소: PCA를 통해 4차원 데이터를 2차원으로 축소하여 데이터의 주요 패턴을 시각화한다. PCA는 데이터의 주요 변동성을 설명하는 두 개의 주성분(PC1, PC2)을 사용하여 데이터를 시각화한다.
주성분 분석: PC1과 PC2는 데이터의 변동성을 가장 잘 설명하는 두 축. 이 산점도를 통해 데이터의 주요 분포와 클러스터링을 이해할 수 있다.
클러스터링: PCA 결과를 통해 데이터의 군집이 어떻게 분포하는지, 품종 간의 구분이 얼마나 잘 되는지 평가할 수 있다. PCA를 통해 시각화된 데이터의 분포는 원본 데이터에서 시각화된 패턴과 비교해볼 수 있다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 데이터 로드
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
# PCA 객체 생성 (2차원으로 축소)
pca = PCA(n_components=2)
# PCA 변환
pca_result = pca.fit_transform(iris_df.iloc[:, :-1])
# PCA 결과를 데이터프레임으로 변환
pca_df = pd.DataFrame(data=pca_result, columns=['PC1', 'PC2'])
pca_df['target'] = iris_df['target']
# 마커 설정
markers = ["*", "s", "o"]
# PCA 산점도 그리기
for i, marker in enumerate(markers):
x_val = pca_df[pca_df["target"] == i]["PC1"]
y_val = pca_df[pca_df["target"] == i]["PC2"]
plt.scatter(x_val, y_val, marker=marker, label=iris.target_names[i])
# 레전드 및 라벨 설정
plt.legend()
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.title("PCA of Iris Dataset")
plt.show()
-> 기본 산점도는 특정 특성 간의 관계를 시각적으로 보여주며,
PCA는 데이터의 전반적인 구조와 주요 패턴을 요약하여 시각화한다.
비교 및 인사이트
패턴의 변화: 기본 산점도와 PCA 산점도를 비교함으로써 데이터의 주요 패턴이 어떻게 달라지는지 볼 수 있다. PCA는 원본 데이터의 주요 패턴을 강조하며, 모든 차원의 정보를 요약하여 시각화.
클러스터링의 명확성: PCA를 통해 데이터가 어떻게 변동성이 큰 방향으로 축소되는지 볼 수 있다. 이로 인해 데이터 포인트 간의 구분이 더 명확하게 나타날 수 있다. PCA를 통해 군집이 명확하게 분리되는지, 데이터가 어떤 방식으로 클러스터링되는지를 평가할 수 있다.
정보 압축: PCA는 데이터의 차원을 축소하지만, 원본 데이터의 주요 정보를 유지한다. 이를 통해 데이터의 핵심 구조와 패턴을 쉽게 이해할 수 있다.
특성 중요도: PCA 결과를 통해 어떤 특성이 데이터의 변동성을 가장 잘 설명하는지 알 수 있다. PCA의 주성분이 데이터의 주요 패턴을 어떻게 요약하는지 분석할 수 있다.
PCA 적용 및 시각화를 통한 데이터 분석
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# CSV 파일 읽기
file_path = 'Value_Sample.csv'
data = pd.read_csv(file_path)
# 데이터프레임 생성
df = pd.DataFrame(data)
df.dropna(how='any', inplace=True)
# 특성과 타겟 분리
X = df[['X1', 'X2', 'X3', 'X4', 'X5']]
y = df['Y1']
# 데이터 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA 적용
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# PCA 데이터프레임 생성
df_pca = pd.DataFrame(data=X_pca, columns=["PC1", "PC2"])
df_pca["target"] = y.values
# 타겟 값을 범주형으로 변환 (필요시)
df_pca['target'] = pd.cut(df_pca['target'], bins=3, labels=["Low", "Medium", "High"])
# 마커 설정
markers = ["*", "s", "o"]
categories = df_pca['target'].unique()
# 산점도 그리기
for category, marker in zip(categories, markers):
x_val = df_pca[df_pca["target"] == category]["PC1"]
y_val = df_pca[df_pca["target"] == category]["PC2"]
plt.scatter(x_val, y_val, marker=marker, label=category)
# 레전드 및 라벨 설정
plt.legend()
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.title("PCA of Sample Dataset")
plt.show()
# 설명된 분산 비율 출력
print(pca.explained_variance_ratio_)
1. 데이터 분포 분석
클러스터 분석: Medium, High, Low 범주가 PCA 주성분 공간에서 어떻게 분포되는지를 시각적으로 확인함으로써, 데이터가 어떤 특정 클러스터를 형성하는지 파악할 수 있습니다.
군집 형성: 각 범주가 서로 다른 영역에 위치하는지, 혹은 데이터 포인트가 서로 섞여 있는지를 확인할 수 있습니다. 이로 인해 데이터의 군집이나 패턴을 파악할 수 있습니다.
2. 주성분 분석 결과 해석
분산 비율 확인: 각 주성분이 데이터의 분산을 얼마나 설명하는지 이해할 수 있습니다. 이는 데이터의 주요 변동성이 어떤 방향으로 나타나는지를 파악하는 데 도움이 됩니다.
변수의 중요성: 주성분 분석을 통해 원래의 변수들이 주성분에 미치는 영향을 확인하고, 주요 변수와 이들의 관계를 이해할 수 있습니다.
3. 범주 간 차이 분석
범주별 패턴: Medium, High, Low 범주 간의 패턴 차이를 분석함으로써, 특정 범주가 PCA 주성분 공간에서 어떻게 다르게 분포되는지를 확인할 수 있습니다.
특성의 영향: 데이터의 주요 특성들이 주성분에 어떻게 영향을 미치는지 분석하고, 각 범주가 특정 특성의 영향을 받는지를 이해할 수 있습니다.
시계열 분석 (Time Series Analysis)
시간에 따라 순서대로 기록된 데이터를 분석하여 데이터의 패턴과 트렌드, 주기성을 이해하고 미래의 값을 예측하는 기법
시계열 분석에서 이동평균의 역할
시계열 분석은 데이터가 시간에 따라 어떻게 변하는지를 분석하고, 이를 기반으로 미래의 값을 예측하거나 패턴을 이해하는 데 사용.
잡음 감소:
시계열 데이터는 일반적으로 노이즈(잡음)를 포함. 이동평균은 이러한 잡음을 부드럽게 하여 데이터의 일반적인 추세를 더 명확하게 파악할 수 있도록 도와줌.
추세 식별:
이동평균을 통해 시계열 데이터의 추세를 시각적으로 쉽게 파악할 수 있다. 이는 데이터의 상승 또는 하강 추세를 인식하는 데 유용.
계절성 분석:
이동평균을 사용하여 데이터의 계절적 변동성을 시각화하거나 제거하고, 장기적인 추세를 분석할 수 있다.
모델링:
시계열 예측 모델에서 이동평균은 종종 예측 모델의 일부로 사용. 예를 들어, ARIMA(Autoregressive Integrated Moving Average) 모델의 이동평균 부분에서 이동평균이 포함될 수 있다.
단순 이동평균(SMA)과 가중 이동평균(WMA)의 역할
단순 이동평균 (SMA):
이동평균 = 구간 내 총합 / 구간
SMA는 가장 기본적인 형태의 이동평균으로, 동일한 가중치를 모든 데이터 포인트에 부여하여 평균을 계산. 데이터의 단기적인 변동을 부드럽게 하고, 전체적인 추세를 파악하는 데 유용하다. 그러나 최신 데이터와 과거 데이터에 동일한 중요도를 부여하기 때문에 최신 추세를 잘 반영하지 못할 수 있다.
가중 이동평균 (WMA):
가중 이동 평균 (WFt) = (D1 X Wt1) + (D2 X Wt2) + .... + (Dn X Wtn)
WMA는 각 데이터 포인트에 서로 다른 가중치를 부여하여 평균을 계산. 보통 최신 데이터에 더 높은 가중치를 부여하여, 최근의 데이터가 평균에 더 큰 영향을 미치도록 한다. 이를 통해 최근의 변동성을 더 잘 반영하고, 최신 추세를 더 정확하게 파악할 수 있다.
시계열 분석에서의 적용
SMA와 WMA를 비교: SMA는 데이터의 전반적인 추세를 파악하는 데 유용하지만, WMA는 최신 데이터의 변동성을 더 잘 반영한다. 따라서, WMA는 빠르게 변화하는 환경에서 더 적절할 수 있다.
모델 선택: 시계열 모델을 구축할 때, SMA와 WMA를 사용하여 데이터의 특성에 맞는 최적의 모델을 선택할 수 있다. 예를 들어, 급격한 변동성이 있는 데이터는 WMA가 더 적합할 수 있다.
import pandas as pd
import numpy as np
# Display 옵션 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# CSV 파일 읽기
file_path = 'Value_Sample.csv' # 적절한 경로로 변경
pd_DataSet = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(pd_DataSet)
New_DF = DF.dropna(how='any')
# 'Y1' 열 추출
Re_Y = New_DF['Y1']
# 하위 3개의 데이터 추출
A_interval = 3
Bottom_Data = Re_Y.tail(A_interval)
# 하위 3개 데이터의 평균 계산
B_M_Avg = np.average(Bottom_Data)
print("Bottom 3 Data Average:", B_M_Avg)
# 데이터 선택
D1 = Bottom_Data.iloc[0] # 선택된 데이터의 첫 번째 값
D2 = Bottom_Data.iloc[1] # 선택된 데이터의 두 번째 값
D3 = Bottom_Data.iloc[2] # 선택된 데이터의 세 번째 값
# 가중 이동평균 계산
B_wM_Avg = (D1 * 0.2) + (D2 * 0.3) + (D3 * 0.5)
print("Bottom 3 Data Weighted Average:", B_wM_Avg)
→ 단순 이동평균(Simple Moving Average, SMA)
: 'Y1' 컬럼의 데이터 중에서 마지막 3개의 데이터 포인트의 평균을 계산하여 이동평균을 구한다.
이이동평균 값은 시계열 데이터의 최근 3개 데이터 포인트의 평균을 나타내며,데이터의 최근 추세를 부드럽게 보여줌.
→ 가중 이동평균(Weighted Moving Average, WMA)
: 가중 이동평균은 이동평균의 각 데이터 포인트에 서로 다른 가중치를 부여하여 평균을 계산하는 방법
'Y1' 컬럼의 데이터 중에서 최근 3개의 데이터 포인트에 가중치를 부여하여 가중 이동평균을 계산
가중 이동평균은 단순 이동평균보다 최근 데이터에 더 높은 중요도를 부여할 때 사용.
결과적으로, 최근 데이터가 평균 계산에 더 큰 영향을 미치도록 하여, 데이터의 최신 추세를 반영하는 데 유용함.
회귀분석 (Regression Analysis)
회귀분석은 데이터 간의 관계를 분석하고 모델링하는 통계적 기법
주로 독립 변수(설명 변수)와 종속 변수(반응 변수) 간의 관계를 이해하고 예측하기 위해 사용
회귀분석의 주요 목표는 독립 변수들이 종속 변수에 미치는 영향을 추정하고, 이를 통해 종속 변수의 값을 예측하는 것
주요 개념
독립 변수 (Independent Variable)
예측하려는 값에 영향을 미치는 변수
종속 변수 (Dependent Variable)
예측하거나 설명하려는 변수로, 독립 변수에 의해 영향을 받는다.
회귀선 (Regression Line)
데이터 포인트와 가장 잘 맞는 직선 또는 곡선
회귀계수 (Regression Coefficients)
독립 변수들이 종속 변수에 미치는 영향을 수치적으로 표현한 값
잔차 (Residuals)
실제 데이터와 모델이 예측한 값 간의 차이
회귀분석의 종류
선형 회귀 (Linear Regression)
독립 변수와 종속 변수 간의 관계를 직선으로 모델링
단순 선형 회귀 (Simple Linear Regression): 독립 변수가 하나인 경우.
다중 선형 회귀 (Multiple Linear Regression): 독립 변수가 여러 개인 경우.
비선형 회귀 (Non-linear Regression)
독립 변수와 종속 변수 간의 관계를 비선형 함수로 모델링
로지스틱 회귀 (Logistic Regression)
종속 변수가 이진 변수인 경우 사용됩. 종속 변수의 확률을 예측.
릿지 회귀 (Ridge Regression) 및 라쏘 회귀 (Lasso Regression)
정규화 기법을 사용하여 모델의 복잡도를 조절하고 과적합을 방지
회귀분석의 과정
데이터 준비
데이터셋을 준비하고, 필요 시 데이터 정제 및 전처리를 수행
모델 선택 및 적합
회귀 분석에 사용할 모델을 선택하고, 데이터에 적합시킴
모델 평가
회귀 모델의 성능을 평가
주요 평가 지표로는 결정계수(R-squared), 평균제곱오차(MSE), 평균절대오차(MAE) 등이 있다.
예측 및 해석
모델을 사용하여 새로운 데이터에 대한 예측을 수행하고, 회귀계수를 해석하여 변수 간의 관계를 이해
선형 회귀 분석
Value_Sample.csv 파일의 데이터를 사용하여 X1과 Y1 간의 선형 관계를 분석하고, 선형 회귀선을 시각화
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Display 옵션 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# CSV 파일 읽기
file_path = 'Value_Sample.csv' # 적절한 경로로 변경
pd_DataSet = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(pd_DataSet)
New_DF = DF.dropna(how='any')
# 독립 변수와 종속 변수 선택
X = New_DF['X1']
Y = New_DF['Y1']
# 선형 회귀 분석 수행
R = np.polyfit(X, Y, 1) # 1차 다항식 (선형 회귀)
R_Ex = np.poly1d(R) # 회귀식 생성
# 결과 출력
print("회귀 계수 (기울기와 절편):")
print(R)
print('---------------')
print("회귀식:")
print(R_Ex)
# 회귀선 시각화
plt.figure(figsize=(10, 6))
plt.scatter(X, Y, color='blue', label='Data Points') # 데이터 포인트 시각화
plt.plot(X, R_Ex(X), color='red', label='Regression Line') # 회귀선 시각화
plt.xlabel('X1')
plt.ylabel('Y1')
plt.title('Linear Regression')
plt.legend()
plt.grid(True)
plt.show()
boston.csv 데이터로 선형 회귀 분석
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Display 옵션 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# CSV 파일 읽기
file_path = 'boston.csv' # 파일 경로를 적절히 변경하세요
pd_DataSet = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(pd_DataSet)
New_DF = DF.dropna(how='any')
# 독립 변수와 종속 변수 선택
X = New_DF['RM'] # 방 개수
Y = New_DF['MEDV'] # 주택 가격
# 선형 회귀 분석 수행
R = np.polyfit(X, Y, 1) # 1차 다항식 (선형 회귀)
R_Ex = np.poly1d(R) # 회귀식 생성
# 결과 출력
print("회귀 계수 (기울기와 절편):")
print(R)
print('---------------')
print("회귀식:")
print(R_Ex)
# 회귀선 시각화
plt.figure(figsize=(10, 6))
plt.scatter(X, Y, color='blue', label='Data Points') # 데이터 포인트 시각화
plt.plot(X, R_Ex(X), color='red', label='Regression Line') # 회귀선 시각화
plt.xlabel('Number of Rooms (RM)')
plt.ylabel('Median Value of Homes (MEDV)')
plt.title('Linear Regression: Number of Rooms vs Median Home Value')
plt.legend()
plt.grid(True)
plt.show()
회귀 계수 (기울기와 절편): [9.10210898, -34.67062078]
회귀식: MEDV=9.102×RM−34.67
1. 기울기 (Slope): 9.1029.1029.102
의미: RM (방 개수)이 1 증가할 때, MEDV (주택 가격)는 평균적으로 9.102 단위만큼 증가
해석: 방 개수가 많을수록 주택 가격이 높아진다는 것을 나타냅니다. 이 값은 방 개수가 가격에 미치는 영향을 수량적으로 나타낸다.
2. 절편 (Intercept): −34.67
의미: 방 개수가 0일 때, 주택 가격의 예측값이 -34.67
해석: 현실적으로 방 개수가 0인 집은 존재하지 않지만, 이 값은 모델이 모든 변수의 영향을 고려하지 않을 때의 예측값을 의미. 절편이 음수인 것은 모델의 수학적 추정치로, 실제로는 방 개수가 0일 때 가격이 존재하지 않기 때문에 해석에 주의가 필요.
다중 선형 회귀 모델 학습 및 예측
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import sklearn.linear_model as slm
# Display 옵션 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# CSV 파일 읽기
file_path = 'Prediction_Sample.csv' # 파일 경로를 적절히 변경하세요
pd_DataSet = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(pd_DataSet)
New_DF = DF.dropna(how='any')
# 독립 변수와 종속 변수 선택
# X1, X2를 포함하는 DataFrame으로 X를 생성
X = New_DF[['X1', 'X2']] # 독립 변수 (X1, X2)
Y = New_DF['Y1'] # 종속 변수 (Y1)
# 학습 데이터와 테스트 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.8, test_size=0.2, random_state=42)
# 결과 확인
print("훈련 데이터 셋 크기:", x_train.shape)
print("테스트 데이터 셋 크기:", x_test.shape)
# 선형 회귀 모델 생성 및 학습
lr_Model = slm.LinearRegression()
lr_Model.fit(x_train, y_train)
# 모델 성능 평가
Train_score = lr_Model.score(x_train, y_train)
Test_score = lr_Model.score(x_test, y_test)
print('---------------------')
print('다중선형회귀 - Train_score : ', Train_score, ', Test_score : ', Test_score)
# 새로운 데이터 예측
Pre_Parm = [[250, 260]] # 새로운 입력 데이터
predict_R = lr_Model.predict(Pre_Parm)
print('----------------------')
print("새로운 데이터 예측 결과:", predict_R)
# 추가 데이터 예측
Pre_DataSet = pd.read_csv('Prediction_Scenario.csv')
Pre_DF = pd.DataFrame(Pre_DataSet)
Pre_S_Parm = Pre_DF[['X1', 'X2']]
predict_sR = lr_Model.predict(Pre_S_Parm)
print('-----------------------')
print("추가 데이터 예측 결과:", predict_sR)
훈련 데이터 셋 크기: (338, 2): 훈련 데이터는 338개의 샘플과 2개의 특성(변수)을 가진 데이터
테스트 데이터 셋 크기: (85, 2): 테스트 데이터는 85개의 샘플과 2개의 특성을 가진 데이터
Train_score: 훈련 데이터에 대한 모델의 R^2 점수. 1에 가까운 값은 모델이 훈련 데이터에 대해 매우 잘 적합했다는 것을 의미
Test_score: 테스트 데이터에 대한 모델의 R^2 점수. 1에 가까운 값은 모델이 테스트 데이터에 대해서도 잘 일반화되었음을 의미
새로운 데이터 예측 결과: [6242.65265511]는 Pre_Parm = [[250, 260]]이라는 새로운 입력 데이에 대한 예측 결과
이 예측 결과는 모델이 250과 260이라는 X1과 X2 값으로부터 예측한 Y1 값이다.
Prediction_Scenario.csv에서 X1과 X2를 추출하여 Pre_S_Parm라는 새로운 데이터프레임을 만들었고 이 데이터프레임은 예측할 입력 데이터만 포함함
학습된 다중 선형 회귀 모델 (lr_Model)을 사용하여 Pre_S_Parm 데이터프레임의 각 샘플에 대해 예측을 수행. 이 예측은 각 샘플의 X1과 X2 값을 입력으로 받아 Y 값을 예측함
Prediction_Scenario.csv에 포함된 각각의 샘플에 대해, X1과 X2 값을 사용하여 선형 회귀 모델이 예측한 Y 값을 출력
배열의 각 요소는 해당하는 X1과 X2 조합에 대해 모델이 예측한 Y 값을 나타낸다.
타율 예측을 위한 선형 회귀 분석 및 시각화
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# CSV 파일 로드
df_new = pd.read_csv('21년 타자기록.csv')
# 필요한 열만 추출 (안타, 2루타, 3루타, 홈런, 타율)
df_filtered = df_new[['안타', '2루타', '3루타', '홈런', '타율']]
# 결측치(NaN) 제거
df_filtered = df_filtered.dropna()
# 독립 변수(X)와 종속 변수(y) 정의
X = df_filtered[['안타', '2루타', '3루타', '홈런']]
y = df_filtered['타율']
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=42)
# 선형 회귀 모델 생성 및 학습
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 예측 수행
y_pred = lr_model.predict(X_test)
# 회귀식 출력 (기울기와 절편)
coefficients = lr_model.coef_
intercept = lr_model.intercept_
print(f"회귀식: y = {coefficients[0]:.4f} * 안타 + {coefficients[1]:.4f} * 2루타 + {coefficients[2]:.4f} * 3루타 + {coefficients[3]:.4f} * 홈런 + {intercept:.4f}")
# 모델 성능 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse:.4f}")
print(f"R-squared: {r2:.4f}")
# 예측 결과 시각화
plt.figure(figsize=(12, 6))
plt.scatter(y_test, y_pred, color='blue', label='실제 vs 예측')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--', label='정확한 예측선')
plt.xlabel('실제 타율')
plt.ylabel('예측 타율')
plt.title('실제 타율 vs 예측 타율')
plt.legend()
plt.grid(True)
plt.show()
회귀식: 안타의 개수는 타율에 긍정적인 영향을 미치며, 2루타, 3루타, 홈런은 타율에 부정적인 영향을 미친다는 결과. 그러나 이러한 기울기 값들이 실제로는 매우 작은 변화를 나타낸다.
MSE: 예측 오차가 상대적으로 적어 모델이 실제 값과 꽤 일치하고 있음을 시사한다.
R-squared: 모델이 타율의 변동성을 잘 설명하지 못하는 상황이다. 더 나은 설명력을 가진 모델을 찾기 위해 추가적인 변수나 다른 모델을 고려할 필요가 있다.
실제 타율과 예측된 타율 간의 관계를 시각적으로 파악
PCA와 선형 회귀를 활용한 데이터 분석 및 예측
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Display 옵션 설정: 모든 행과 열을 출력
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# CSV 파일 읽기
file_path = 'Prediction_Sample.csv' # 파일 경로를 적절히 변경하세요
df = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(df) # 데이터프레임 생성
New_DF = DF.dropna(how='any') # 결측값이 있는 행 제거
# 독립 변수와 종속 변수 선택
X = New_DF[['X1', 'X2']] # 독립 변수 (X1, X2)
Y = New_DF['Y1'] # 종속 변수 (Y1)
# 데이터 표준화: 변수의 스케일을 조정하여 PCA의 성능 향상
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 데이터 표준화 수행
# PCA 수행: 차원 축소를 통해 데이터의 주요 성분 추출
pca = PCA(n_components=2) # 주성분의 개수를 2로 설정 (2D 데이터)
X_pca = pca.fit_transform(X_scaled) # PCA를 통해 차원 축소
# PCA 주성분과 설명된 분산 비율 출력
print('PCA 주성분:')
print(pca.components_) # 주성분의 방향 (각 주성분의 방향 벡터)
print('PCA 설명된 분산 비율:')
print(pca.explained_variance_ratio_) # 각 주성분이 설명하는 분산 비율
# 다양한 비율로 데이터 나누기: 훈련 데이터와 테스트 데이터를 나누는 비율 변경
train_sizes = [0.7, 0.8, 0.9] # 훈련 데이터 비율
for train_size in train_sizes:
print(f'\n훈련 데이터 비율: {train_size}')
# 학습 데이터와 테스트 데이터 분리
x_train, x_test, y_train, y_test = train_test_split(X_pca, Y, train_size=train_size, test_size=1-train_size, random_state=42)
# 선형 회귀 모델 생성 및 학습
lr_Model = LinearRegression()
lr_Model.fit(x_train, y_train) # 모델 학습
# 모델 성능 평가
Train_score = lr_Model.score(x_train, y_train) # 훈련 데이터에 대한 성능
Test_score = lr_Model.score(x_test, y_test) # 테스트 데이터에 대한 성능
print('---------------------')
print('다중선형회귀 - Train_score : ', Train_score, ', Test_score : ', Test_score)
# 새로운 데이터 예측
Pre_Parm = [[250, 260]] # 새로운 입력 데이터
Pre_Parm_scaled = scaler.transform(Pre_Parm) # 데이터 표준화
Pre_Parm_pca = pca.transform(Pre_Parm_scaled) # PCA 변환
predict_R = lr_Model.predict(Pre_Parm_pca) # 예측 수행
print('----------------------')
print("새로운 데이터 예측 결과:", predict_R)
# PCA를 통해 변환된 데이터와 원본 데이터의 차원 감소를 시각화
plt.figure(figsize=(10, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=Y, cmap='viridis') # PCA 변환된 데이터 시각화
plt.xlabel('Principal Component 1') # x축 레이블
plt.ylabel('Principal Component 2') # y축 레이블
plt.title('PCA of Prediction Data') # 그래프 제목
plt.colorbar(label='Y1') # 색상 바 레이블
plt.show() # 그래프 출력
두 개의 주성분 벡터를 출력 -> 데이터가 변동하는 주된 방향을 나타냄
주성분 1: [0.70710678, 0.70710678]
이 벡터는 데이터의 첫 번째 주성분을 나타낸다. 이 방향으로의 데이터의 분산이 가장 크다. 벡터의 값이 0.70710678로 같은 크기를 가지므로, 이 주성분은 원본 데이터의 두 변수(X1, X2)에 대해 같은 비율로 영향을 미침.
주성분 2: [0.70710678, -0.70710678]
이 벡터는 데이터의 두 번째 주성분을 나타낸다. 이 주성분 방향으로 데이터의 분산이 두 번째로 크다. 첫 번째 주성분과는 다른 방향을 가지며, X1과 X2의 값의 차이에 대해 반대 방향으로 영향을 미침.
첫 번째 주성분이 데이터의 약 99.02%의 분산을 설명하고, 두 번째 주성분이 나머지 0.98%를 설명함.
이는 데이터의 대부분이 첫 번째 주성분에 의해 설명된다는 것을 의미.
훈련 데이터 비율이 높아질수록 모델의 훈련 데이터에서의 성능(Train_score)은 안정적으로 유지되지만, 테스트 데이터에서의 성능(Test_score)은 다소 변동이 있을 수 있다. 이는 모델이 훈련 데이터에 과적합될 가능성이 있음을 나타냄
새로운 데이터에 대한 예측 결과는 훈련 데이터 비율에 따라 약간의 차이를 보인다. 훈련 데이터 비율이 높을수록 모델이 새로운 데이터에 대해 더 정확한 예측을 하는 경우가 많다.
주성분 축(Principal Components Axes):
x축: 첫 번째 주성분 (Principal Component 1)
y축: 두 번째 주성분 (Principal Component 2)
PCA는 원본 데이터의 차원을 줄이면서, 가장 많은 분산을 설명하는 두 개의 축을 찾는다. 이 축들은 데이터의 주요 패턴을 포착함.
색상은 각 데이터 포인트의 종속 변수 Y1 값을 나타냄. cmap='viridis'는 색상의 범위를 정의하며, 색상 막대(colorbar)는 Y1 값에 대한 색상 범위를 나타냄.
색상에 따라 Y1 값이 낮은 데이터는 다른 색상, 높은 데이터는 다른 색상으로 표시된다.
회귀 모델 성능 평가 : MAE, MSE, RMSE, R² 스코어 계산
MAE, MSE, RMSE, R² 스코어 개념
MAE (Mean Absolute Error):
정의: 예측값과 실제값 간의 절대적인 차이의 평균
수식:
장점: 단순하고 직관적인 지표로, 오차의 절대값을 평균하여 계산
단점: 큰 오차에 대해 민감하지 않으며, 오차의 제곱을 사용하지 않아 큰 오차가 중요할 경우 부족할 수 있다.
MSE (Mean Squared Error):
정의: 예측값과 실제값 간의 차이의 제곱의 평균
수식:
장점: 큰 오차에 대해 민감하여, 모델의 오차가 클 경우 더 많은 페널티를 부여.
단점: 오차의 제곱을 사용하기 때문에, 큰 오차가 모델 성능 평가에 과도한 영향을 미칠 수 있다.
RMSE (Root Mean Squared Error):
정의: MSE의 제곱근으로, MSE의 단위를 원래 데이터 단위로 되돌린 것.
수식:
장점: 데이터와 같은 단위로 표시되며, 모델의 예측 오차의 크기를 쉽게 이해할 수 있다.
단점: MSE와 마찬가지로 큰 오차에 민감.
R² 스코어 (Coefficient of Determination):
정의: 모델이 종속 변수의 변동성을 얼마나 잘 설명하는지를 나타낸다.
R² 스코어는 0과 1 사이의 값을 가지며, 1에 가까울수록 모델이 데이터를 잘 설명함을 의미
수식:
여기서 RSS는 잔차 제곱합 (Residual Sum of Squares), TSS는 총 제곱합 (Total Sum of Squares).
장점: 모델의 적합도를 상대적으로 평가할 수 있으며, 1에 가까울수록 모델이 데이터를 잘 설명함을 의미.
단점: 단일 변수 회귀 모델의 경우, 모든 데이터 포인트에 대해 선형적인 관계가 가정되어야 하며, 다중 회귀 모델에서는 조정된 R²를 사용하는 것이 더 적절할 수 있다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn.model_selection as sms
import sklearn.metrics as slt
import sklearn.linear_model as slm
# CSV 파일 읽기
file_path = 'Prediction_Sample.csv'
df = pd.read_csv(file_path)
# 데이터프레임 생성 및 결측값 제거
DF = pd.DataFrame(df) # 데이터프레임 생성
New_DF = DF.dropna(how='any') # 결측값이 있는 행을 제거
# 독립 변수와 종속 변수 선택
x = New_DF[['X1', 'X2']] # 독립 변수: 'X1'과 'X2'
y = New_DF['Y1'] # 종속 변수: 'Y1'
# 학습 데이터와 테스트 데이터 분리
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, train_size=0.8, test_size=0.2)
# 선형 회귀 모델 생성 및 학습
lr_Model = slm.LinearRegression() # 선형 회귀 모델 생성
lr_Model.fit(x_train, y_train) # 모델을 훈련 데이터로 학습
# 전체 데이터에 대한 예측
predict_X = lr_Model.predict(x) # 전체 독립 변수 'x'에 대해 예측 수행
# 성능 평가 지표 계산
MEA_score = slt.mean_absolute_error(y, predict_X) # MAE 계산
MSE_score = slt.mean_squared_error(y, predict_X) # MSE 계산
RMSE_score = MSE_score ** 0.5 # RMSE 계산 (MSE의 제곱근)
# MAE, MSE, RMSE 개념:
# MAE (Mean Absolute Error): 예측값과 실제값 간의 절대적인 차이의 평균을 나타냅니다.
# MSE (Mean Squared Error): 예측값과 실제값 간의 차이의 제곱의 평균을 나타냅니다.
# RMSE (Root Mean Squared Error): MSE의 제곱근으로, 오차의 평균 크기를 원래 데이터 단위로 표시합니다.
print('--------------평균 기반 검증--------------')
print('MAE : ', MEA_score) # 평균 절대 오차 출력
print('MSE : ', MSE_score) # 평균 제곱 오차 출력
print('RMSE : ', RMSE_score) # 루트 평균 제곱 오차 출력
# R² 스코어 계산
R2_score = slt.r2_score(y, predict_X) # R² 스코어 계산
# R² 스코어 개념:
# R² 스코어 (Coefficient of Determination): 모델이 종속 변수의 변동성을 얼마나 잘 설명하는지를 나타내며, 1에 가까울수록 모델이 데이터를 잘 설명함을 의미합니다.
print('--------------상대적 분산 기반 검증--------------')
print('R2_score : ', R2_score) # R² 스코어 출력
MAE, MSE, RMSE는 모두 예측 오차의 크기를 나타내며, 여기서 MAE는 가장 직관적이고, MSE는 오차의 제곱 평균, RMSE는 MSE의 제곱근임
R² 스코어가 0.997로 매우 높은 값이므로, 모델이 종속 변수의 변동성을 거의 완벽하게 설명하고 있음을 나타내고 이는 예측값이 실제값에 거의 정확하게 일치한다고 할 수 있다.