import pandas as pd
date = ["6/1", "6/2", "6/3", "6/4", "6/5"]
high = pd.Series([42800, 42700, 42050, 42950, 43000], index = date)
low = pd.Series([42150, 42150, 41300, 42150, 42350], index = date)
# 변동폭
diff = high - low
diff
날짜 찾기
diff.max() # 최대값
diff.idxmax() # 가장 큰 값이 있는 날짜
diff.idxmin() # 가장 작은 값이 있는 날짜
수익률 계산
# 수익률
profit = high / low
profit
누적 수익률 계산
# 누적수익률
profit.cumprod().iloc[-1]
안에 있는 ' , ' 처리
def myfunc(x):
x = x.replace(',', '')
return int(x)
s = pd.Series(['1,234','5,678','9,876']) # 안에 있는 , 값 없애기
s.apply(myfunc)
쉼표 제거, 정수형 변환, 데이터프레임 처리
import numpy as np
def myfunc(x):
x = x.replace(',', '')
return int(x)
data = [
["1,000", "1,100", '1,510'],
["1,410", "1,420", '1,790'],
["850", "900", '1,185'],
]
columns = ["03/02", "03/03", "03/04"]
df = pd.DataFrame(data=data, columns=columns)
df['03/02'] = df['03/02'].apply(myfunc).astype(np.int32) # int32 : +-20억
df['03/03'] = df['03/03'].apply(myfunc).astype(np.int32) # int64 : 경단위
df['03/04'] = df['03/04'].apply(myfunc).astype(np.int32)
df
순위 처리
# 순위처리
df = pd.read_excel('성적 처리.xlsx', sheet_name = 'Sheet1')
df['총합'] = df.iloc[:, 2:].sum(axis = 1)
df.sort_values(['반', '총합'], ascending = [True, False]) # 오름차순, 내림차순
→ ascending = False : 내림차순
# 순위 (average) : 3등이 2명이면 둘 다 3.5등으로 처리하고 다음 등수를 5등
df['순위'] = df['총합'].rank(ascending = False, method = 'average')
# max : 3등이 두명이면 둘 다 4등으로 처리하고 다음 등수를 5등
df['순위'] = df['총합'].rank(ascending = False, method = 'max')
# min : 3등이 2명이면 둘 다 3등처리하고 다음 등수를 5등
df['순위'] = df['총합'].rank(ascending = False, method = 'min')
# first : 3등이 2명이면, 처음 발견한 3등은 3등, 다음에 발견한 3등은 4등 (선착순)
df['순위'] = df['총합'].rank(ascending = False, method = 'first')
# dense : min이랑 같음. 3등이 2명이면 둘 다 3등 처리하고 다음 등수를 4등
df['순위'] = df['총합'].rank(ascending = False, method = 'dense')
주식 코드 및 가격 처리 후 데이터프레임 변환
data = [
{"cd":"A060310", "nm":"3S", "close":"2,920"},
{"cd":"A095570", "nm":"AJ네트웍스", "close":"6,250"},
{"cd":"A006840", "nm":"AK홀딩스", "close":"29,700"},
{"cd":"A054620", "nm":"APS홀딩스", "close":"19,400"}
]
df = pd.DataFrame(data=data)
df["cd"] = df["cd"].str[1:] # .str : 안에 있는 값에 접근한다. 1번부터 꺼내온다.
df['close'] = df['close'].str.replace(',', '').astype(np.int32)
df
데이터프레임을 조건에 맞춰 필터링
data = [
{"cd":"A060310", "nm":"3S", "open":2920, "close":2800},
{"cd":"A095570", "nm":"AJ네트웍스", "open":1920, "close":1900},
{"cd":"A006840", "nm":"AK홀딩스", "open":2020, "close":2010},
{"cd":"A054620", "nm":"APS홀딩스", "open":3120, "close":3200}
]
df = pd.DataFrame(data=data)
# df.query("""nm == '3S'""")
# df.query("""open > close""")
df.query("""nm in ['3S', 'AK홀딩스']""")
@name : name 변수
name = 'AJ네트웍스'
df.query("""nm == @name""") # @name : name 변수
filter 메소드를 사용하여 데이터프레임에서 특정 열만 선택
# filter
data = [
[1416, 1416, 2994, 1755],
[6.42, 17.63, 21.09, 13.93],
[1.10, 1.49, 2.06, 1.88]
]
columns = ["2018/12", "2019/12", "2020/12", "2021/12(E)"]
index = ["DPS", "PER", "PBR"]
df = pd.DataFrame(data=data, index=index, columns=columns)
df.filter(items = ['2018/12'])
필터링할 행을 지정하며, axis=0은 행을 기준으로 필터링
df.filter(items = ['PER'], axis = 0)
정규표현식 : 문자열에서 패턴 찾는 기술
# 정규표현식 : 문자열에서 패턴 찾는 기술
df.filter(regex = r'2020') # r'2020' : 2020 이 들어간 패턴을 찾고 싶다.
df.filter(regex = r'^201') # 201로 시작하는 패턴 찾기
df.filter(regex = r'^R$') # R로 끝나는 패턴을 찾고싶어
df.filter(regex = r'\d{4}') # \d : 숫자 -> 4자리로 된 숫자 패턴 찾기
df.filter(regex = r'\d{4}\/d{2}$') # \d : 숫자 -> 4자리로 된 숫자 패턴 찾기
정규표현식 쓰기
import re
# 정규 표현식 쓰기
text = '''기초단체장 4명 apple'''
re.findall('[가-힣a-zA-Z]+', text)
특정 단어에 해당하는 행들만 추출
data = [
["영업이익", "컨센서스", 1000, 1200],
["영업이익", "잠정치", 900, 1400],
["당기순이익", "컨센서스", 800, 900],
["당기순이익", "잠정치", 700, 800]
]
df = pd.DataFrame(data=data)
df = df.set_index([0, 1])
df.index.names = ['재무연월', '']
df.columns = ['2020/06', '2020/09']
#df.loc['영업이익']
df.loc[(slice(None), '컨센서스'), :] # 특정 열만 추출
data = [
[100, 900, 800, 700],
[1200, 1400, 900, 800]
]
columns = [
['영업이익', '영업이익', '당기순이익', '당기순이익'],
['컨센서스', '잠정치', '컨센서스', '잠정치']
]
index = ["2020/06", "2020/09"]
df = pd.DataFrame(data=data, index=index, columns=columns)
df['영업이익']
# 영업이익 안의 컨센서스
#df[('영업이익', '컨센서스')]
df.T
stack : 열을 행으로 하나 내리는 것 / unstack : 행을 열로 하나 올림
# stack : 열을 행으로 하나 내리는 것 / unstack : 행을 열로 하나 올림
df.stack(level = 0)
df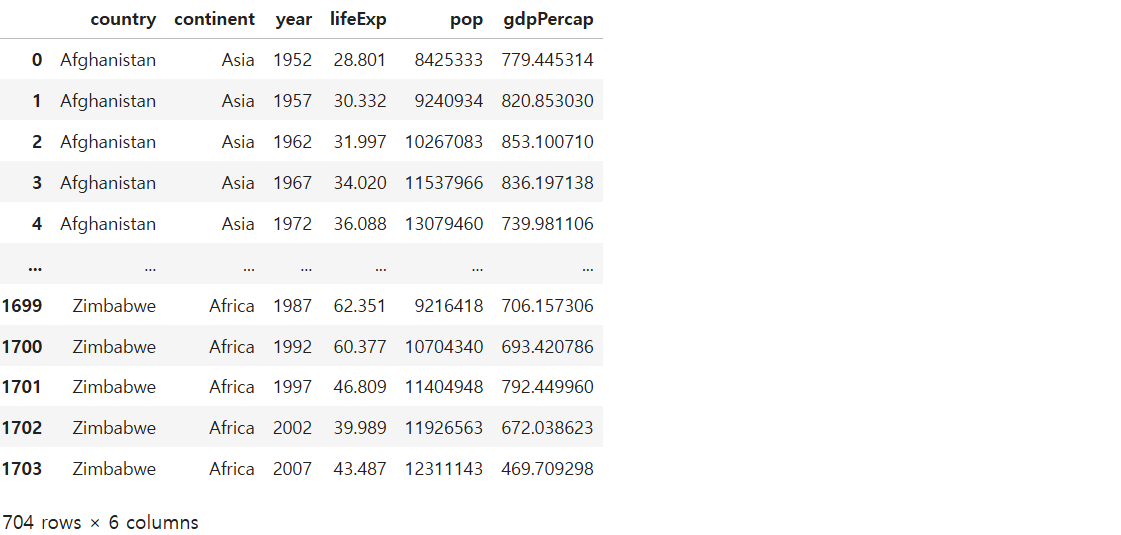
groupby
# Groupby
df = pd.read_csv('gapminder.tsv', sep = '\t')
a = df.groupby('year')['lifeExp'].mean() # 같은 년도끼리 집단화하여 기대수명 평균내기
a.plot()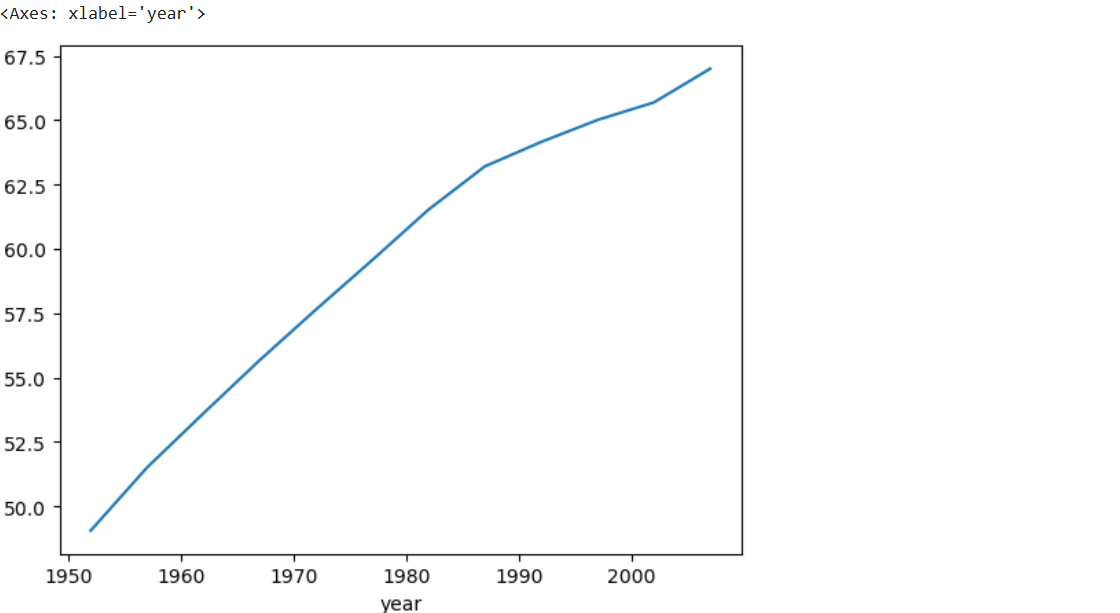
# 년도와 대륙별 기대수명 구하기
a = df.groupby(['year', 'continent'])['lifeExp'].mean()
#a.to_excel('gapminder_result.xlsx')
a
count : 중복 허용
nunique : 중복 허용하지 않고 카운트
# count : 중복 허용
# nunique : 중복 허용하지 않고 카운트
df.groupby('continent')['country'].nunique()# 년도별 인구수와 기대수명의 평균 같이 보기
df.groupby('year')[['lifeExp', 'pop']].mean()# 년도별로 기대수명은 평균, 인구수 평균, 중앙값, GDP는 최소값과 최대값
df.groupby('year').agg({'lifeExp' : 'mean',
'pop' : ['mean', 'median'],
'gdpPercap' : ['min', 'max']})# 1. 각 대륙(continent)별 평균 기대수명(lifeExp)을 구하시오.
a = df.groupby('continent')['lifeExp'].mean()
# 2. 각 연도(year)별 전 세계 인구(pop)의 총합을 계산하시오.
b = df.groupby('year')['pop'].sum()
b
# 3. 각 대륙(continent)과 연도(year)별 평균 기대수명(lifeExp)을 구하고 피벗 테이블 형태로 나타내시오.
c = df.groupby(['continent', 'year'])['lifeExp'].mean()
c = c.unstack(level = 0)
# 4. 2007년도의 데이터를 사용하여 각 대륙(continent)별 총 인구(pop)와 평균 GDP per capita(gdpPercap)를 구하시오.
d = df[df['year'] == 2007].groupby('continent').agg({'pop' : 'sum',
'gdpPercap' : 'mean'})
# 5. 각 대륙(continent)별로 기대수명(lifeExp)의 평균과 최대값, 그리고 GDP per capita(gdpPercap)의 평균과 최소값을 계산하시오
e = df.groupby('continent').agg({'lifeExp' : ['mean', 'max'],
'gdpPercap' : ['mean', 'min']})
# 6. 각 대륙(continent)과 연도(year)별로 인구(pop)의 합계와 기대수명(lifeExp)의 평균을 한 번에 계산하시오.
f = df.groupby(['continent','year']).agg({'pop' : ['sum'],
'lifeExp' : ['mean']})
# 7. 연도별로 기대수명이 가장 높았던 국가들을 구하시오.
idx = df.groupby('year')['lifeExp'].idxmax()
df.iloc[idx]
주식 데이터
월별, 분기별, 주별 데이터 집계, 거래량 변화 탐지, 모멘텀 전략 및 수익률 계산
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 데이터 불러오기
df = pd.read_excel('ss_ex_1.xlsx', parse_dates=['일자'])
df = df.sort_values('일자')
# 월별 및 분기별 데이터 집계 설정
df2 = df[['일자', '시가', '저가', '고가', '종가']].copy()
df2['year'] = df2['일자'].dt.year
df2['month'] = df2['일자'].dt.month
how = {
"시가": "first",
"저가": "min",
"고가": "max",
"종가": "last"
}
# 월별, 3개월 단위, 주별로 데이터 집계
monthly_df = df.groupby(pd.Grouper(key='일자', freq='M')).agg(how)
quarterly_df = df.groupby(pd.Grouper(key='일자', freq='3M')).agg(how)
weekly_df = df.groupby(pd.Grouper(key='일자', freq='W')).agg(how)
# 전일 거래량 컬럼 추가
df = df.set_index('일자')
df['전일거래량'] = df['거래량'].shift(1)
# 거래량이 증가한 날 계산
cond = df['거래량'] > df['전일거래량']
print(f'상승일: {len(df[cond])}')
print(f'영업일: {len(df)}')
# 간단한 모멘텀 전략: 과거 6일 대비 3% 상승한 경우
a = df['종가'] / df['종가'].shift(6)
cond = a >= 1.03
print(f"시장 참여 기회: {len(df[cond])}")
# 시그널 발생 다음날 매수하여 종가에 매도한 경우 수익률 계산
cond2 = cond.shift(1).fillna(False)
s = df.loc[cond2, '종가'] / df.loc[cond2, '시가']
print(f"누적 수익률: {s.cumprod()[-1]:.2%}")
총 127 영업일 중에서 66일 동안 거래량이 증가
과거 6일 대비 종가가 3% 이상 상승한 날이 12일
모멘텀 전략에 따른 시그널 발생 다음날 시가에 매수하여 종가에 매도했을 때, 약 91.38%의 누적 수익을 얻을 수 있었다
## 산술 평균 : 특정 구간의 주가를 산술 평균에서 여러 구간의 평균값을 연결한 선
df = pd.read_excel('ss_ex_1.xlsx', parse_dates = ['일자'])
df = df.sort_values('일자')
df = df.set_index('일자')
df2 = df[['종가']]
df2['종가D-1'] = df2['종가'].shift(1)
df2['종가D-2'] = df2['종가'].shift(2)
df2['MA3'] = (df2['종가'] + df2['종가D-1'] + df2['종가D-2']) / 3
df2['rolling3'] = df2['종가'].rolling(window = 3).mean()
df2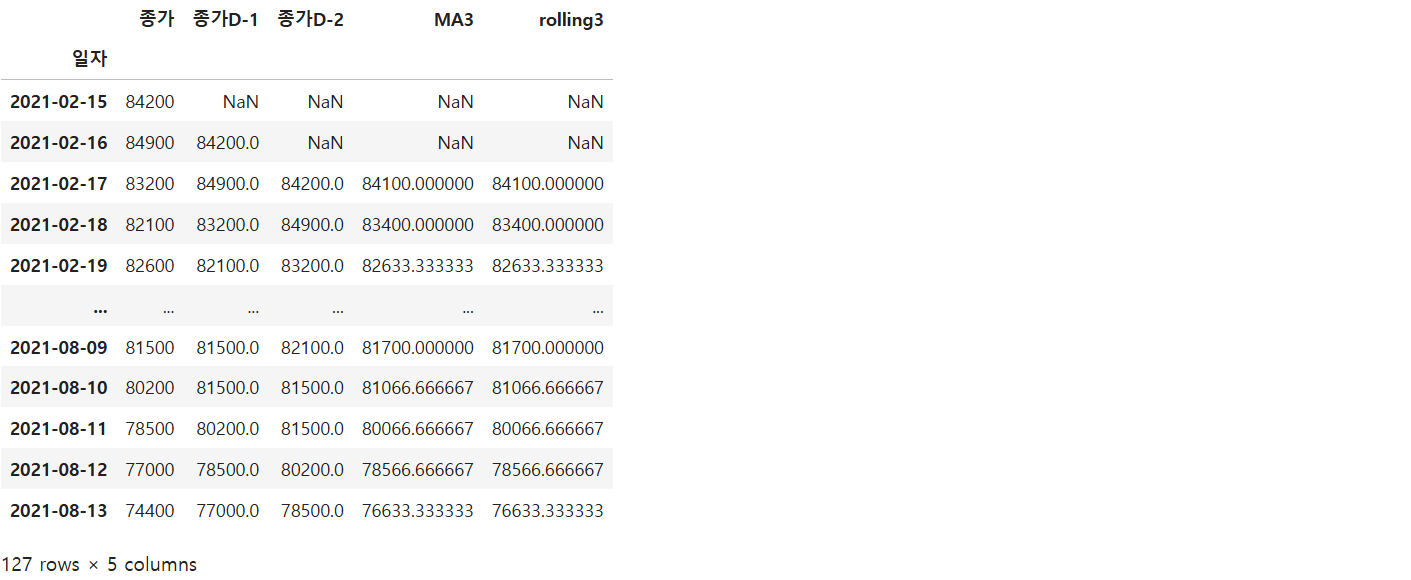
# 시가가 5일 이동평균선을 돌파하면 상승 추세라고 판단하고 참여
df = pd.read_excel('ss_ex_1.xlsx', parse_dates = ['일자'])
df = df.sort_values('일자')
df = df.set_index('일자')
df['MA5'] = df['종가'].rolling(window = 5).mean() # 5일 이동평균
cond = df['MA5'] < df['종가']
# print(len(df[cond])) # 51일 정도 시장 참여 기회가 있었다.
# print(len(df))
cond2 = cond.shift(1).fillna(False)
# 5일 > 20일 > 60일 > 120일
s = df.loc[cond2, '종가'] / df.loc[cond2, '시가']
s.cumprod()
볼린저 밴드
표준편차 * 2 < 값 < 값 + 표준편차 * 2
볼린저 밴드는 주식 가격의 변동성을 측정하는 기술적 분석 도구로, 주가가 일정한 범위 내에서 움직이는지를 판단
가의 평균과 표준편차를 이용하여 주가의 상한선과 하한선을 설정하고, 이를 기반으로 주식의 매매 타이밍을 예측
- 주가가 상단 밴드에 도달하면 과매수(overbought) 상태로 볼 수 있으며, 이는 주가가 너무 많이 오른 상황일 수 있어서 하락 가능성이 있다고 해석
- 반대로 주가가 하단 밴드에 도달하면 과매도(oversold) 상태로 간주되어 상승 가능성이 있는 매수 신호로 볼 수 있다.
- 주가가 상단과 하단 밴드 사이에서 횡보하는 경우는 안정적인 흐름을 의미
# 볼린저 밴드 계산을 위한 설정
window = 20 # 이동 평균을 계산할 기간 (20일 기준)
std = 2 # 표준편차를 2배로 사용하여 상한선과 하한선을 계산
# 20일 이동 평균 계산
mean = samsung['Close'].rolling(window=window).mean()
# 20일 이동 표준편차 계산
std = samsung['Close'].rolling(window=window).std()
# 계산된 평균과 표준편차를 데이터프레임에 추가
samsung['mean'] = mean
samsung['std'] = std
# 상단 밴드 (Upper Bollinger Band) 계산: 평균 + 2배 표준편차
samsung['UB'] = samsung['mean'] + 2 * samsung['std']
# 하단 밴드 (Lower Bollinger Band) 계산: 평균 - 2배 표준편차
samsung['LB'] = samsung['mean'] - 2 * samsung['std']
# 2024년 데이터만 필터링
samsung2 = samsung[samsung.index.year == 2024]
# 차트에 주가 및 볼린저 밴드 추가
plt.plot(samsung2['Close'], color='b') # 파란색 선으로 주가 그리기
plt.plot(samsung2['mean']) # 이동 평균 그리기
plt.plot(samsung2['UB'], color='r') # 상단 밴드 그리기 (빨간색)
plt.plot(samsung2['LB'], color='r') # 하단 밴드 그리기 (빨간색)
# 차트 보여주기
plt.show()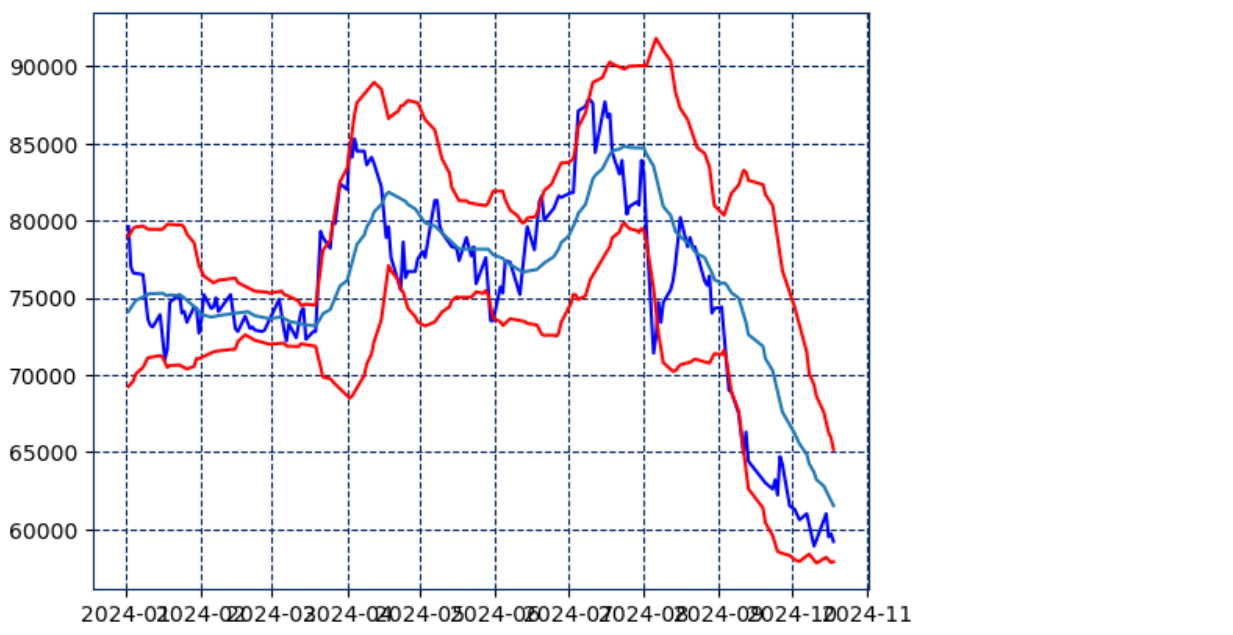
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 변동성 돌파 전략, 마켓 타이밍 전략 (4) | 2024.10.23 |
|---|---|
| 주식 포트폴리오 분석을 위한 시뮬레이션 - 몬테카를로 시뮬레이션, 샤프지수, KOSPI 통계분석, 종목간 상관관계, 최대 낙폭, 할로윈 투자 전략 (2) | 2024.10.21 |
| Okt 형태소 분석기(빈도기반), 워드클라우드, 상대빈도분석(오즈비 분석), TF-IDF 분석 (1) | 2024.10.14 |
| 자연어 처리(NLP) - 감성분석, OpenAI (6) | 2024.10.11 |
| 자연어 처리 - 소문자 변환, 토큰화, 빈도 분석 (7) | 2024.10.10 |



