웹데이터 수집
이때까지는 가져온 데이터로 실습했는데 확보하기 힘들어 데이터를 하나하나 입력을 해야하는 경우
그때 사용할 수 있는 방식이 웹스크래핑
웹스크래핑 : 조직적이고 자동화된 방법으로 웹사이트들을 탐색해서 원하는 정보를 획득하기
(웹크롤링이라고 할 수 없음)
웹 스크래핑을 위해 필요한 패키지
requests 패키지 - 웹페이지 다운로드
beautifulsoup 패키지 - 웹페이지 구조 분석
pandas 패키지 - 데이터 저장, 처리 및 분석
Web이 어떻게 동작?
web은 web server가 필요
각각의 web server에는 홈페이지에 관한 정보를 파일로 갖고 있음 (준비된 상태)
내 pc(client)에 web browser이 있고 주소창에 주소를 쳐서 웹페이지에 가서 원하는 페이지를 요청함 -> request
요청이 정상적이면 웹페이지는 파일을 내 PC에 전달해줌 -> responce
이 과정을 반복
-> 웹페이지의 정보를 스크래핑 하기 위해서는 web서버에서 오는 responce에 있는 파일 분석이 필요
주소창에 https://www.naver.com 주소 치고 엔터
: 네이버 서버에 첫번째 페이지를 보고싶다고 request를 보낸 것
웹페이지 구성 요소
HTML : 웹페이지의 골격 구조 및 콘텐트
CSS : 웹페이지 디자인
JAVA Script : 웹페이지의 동적 동작
주요 웹스크래핑 대상
웹페이지에서 주요 데이터 정보를 표현하고 있는 HTML이 웹스크랩핑의 대상이 되는 경우가 대부분
HTML(HyperText Markup Language)
웹페이지를 위한 지배적인 마크업 언어, 구조적 문서를 만들 수 있는 방법 제공
- 하이퍼텍스트 : 서로 연결되어 있는 링크를 통해 읽는 순서가 결정되어 있지 않는 형태로 한 문서에서 다른 문서로 접근할 수 있는 텍스트
- 마크업 언어 : 태그(문서의 구조를 표현하는 역할)를 이용해 문서와 데이터의 구조를 표시하는 언어
HTML 기본 구조
- 가장 기본 구조
<html> 태그를 사용해 <html> 과 </html> 사이의 모든 텍스트가 HTML 이라고 선언됨
(태그는 대소문자 구분 x)
- HTML은 크게 두 부분 head와 body로 구분됨
- head : 타이틀이나, 메타데이터등의 웹페이지 자체 정보를 담고 있음
- body : 주요 웹페이지 컨텐트를 담고 있음, 주요 크롤링 대상
<HTML> <HEAD> </HEAD> <BODY> </BODY> <HTML>
주요 HTML 태그
<P> : 본문 태그, 문단 태그
<BP> : 줄바꾸기
<HR> : 수평줄삽입
<UL>, <LI> : 글머리 기호 목록 생성, 목록 요소 생성
<OL>,<LI> : 순서 번호 목록 생성, 목록 요소 생성
<DIV> : 공간 분할 태그
위치에 따른 Tag 관계
- Parent : 다른 태그를 포함하고 있는 태그
- Child : 다른 태그 내부에 있는 태그
- Sibling
HTML Tag의 ID, Class 속성
- 웹 브라우저 화면에는 변화가 없음
- HTML 각 태그에 특별한 속성이 ID 와 CLASS 속성을 부여할 수 있다.
- CSS 등에서 특정 태그를 지칭하기 위해 주로 활용됨
- 웹스크래핑에도 특정 태그를 지칭하기 위해 자주 활용됨
- ID : 중복될 수 없음
웹페이지 다운로드
requests 패키지 : 다양한 형태의 request를 웹서버에 보내 웹페이지를 다운로드한다.
get, post, put, delete 를 할 수 있다.
r = request.get("http://www.yu.ac.kr")
다운로드 성공 여부 확인
status_code 속성으로 확인 가능
요청 후 다운로드 상태 확인
항상 정상적으로 웹 요청이 끝나고 난 후 다음 단계로 진행해야한다.
웹스크래핑 기초 실습


접속한 페이지가
영문을 사용한 웹브라우저에서 접속하면 영문으로 나오고
한글을 사용한 웹브라우저에서 접속하면 한글로 나오는 페이지임
-> /index.do 가 붙은 한글페이지로 url 수정하여 한글페이지에 직접 접근

BeautifulSoup 사용해보기
text를 html구조에 맞춰서 파싱 -> beutifulsoup 사용
from bs4 import BeautifulSoup 선언
soup이 root이고 자식들 출력해보기

html코드만 저장

p태그 검색

p태그 중에서 mini-title만 찾기

YU 뉴스룸 제목 정보 모아보기
페이지 우클릭 - 검사 -> element에서 html 소스 코드를 볼 수 있다.
왼쪽 상단 화살표 아이콘 선택시 검사할 페이지 요소 선택 가능
import requests 선언


BeautifulSoup : html 코드로 분석해서 text를 html구조에 맞춰서 파싱

yu뉴스룸 구분해보기
-> class_ = mini-title이 적용된 p태그 정보 출력


CSS Selector (CSS 선택자)
css가 없어지면 html이 남아있어도 일렬로 전부 출력됨
css : html의 특정 부분을 선택해 어디에 넣어줘야할 지 결정
p태그 중에서 mini-title 클래스를 가진 것만 선택 -> select()


-> '.' 은 클래스를 나타냄
텍스트만 가져와 리스트 만들기
get_text() 사용

위 처럼 for문을 사용하지 않고 문자열만 가져와보기

날짜도 제목과 같이 가져와보기


날짜와 제목을 튜플로 저장

Pandas의 DataFrame으로 만들어 저장

1. 컬럼인덱스를 '제목', '게시날짜' 로 변경

2. 정보를 수집한 날짜를 추가해보기
today() : 현재 시간을 저장
strftime('%Y-%m-%d') : 날짜만 가져오기

주기적 프로그램 실행
● crontab : 리눅스나 유닉스 서버에서 주기적으로 프로그램을 실행 시킬 때 사용


뉴스 이미지 파일 다운로드 하기
각각의 기사마다 이미지들도 다운받아 저장해보기
이미지의 위치 : .news-img-box 클래스 안에 있는 div태그에 포함
이미지 파일 자체를 Pandas에 넣을 수는 없다. 별도의 폴더에 저장
1. 이미지 주소 확보



전체이미지 주소 한 번에 구하기

2. 이미지 다운로드




현재 시간을 활용해 이미지 파일명 설정

기상데이터 자동 다운로드
주소창에 넣어서 전달하는 방식 : get
뒤에서 안보이게 전달하는 방식 : post
기상자료개방포털 url 가져오기


csv 다운로드를 눌렀을때 payload


전달 받은 payload로 다시 출력

이 데이터를 파일로 저장


payload 바꾸기
: 1990에서 2000으로 시작일 바꿔보기

payload를 변경하는 함수 만들어보기

-> 원하는 정보를 갖기 위해 payload의 특정 부분을 바꾸면 된다.

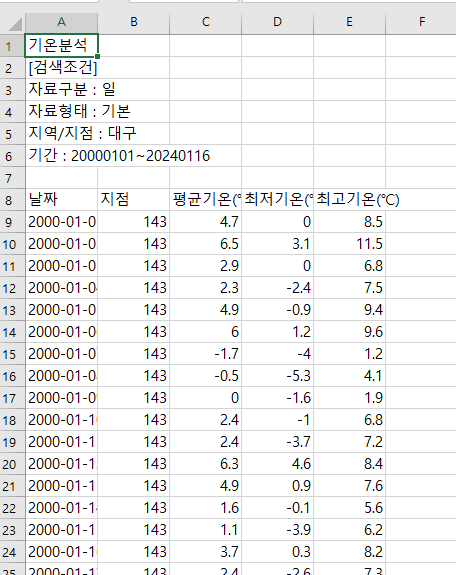
원하는 날짜의 기상데이터 다운받기


미니프로젝트
● 기상청 데이터를 처리해서 출력해주는 프로그램을 작성
● 지점, 지점이름, 시작날짜, 끝날짜를 입력받으면 자동으로 기상청 데이터를 다운받고
● 각 월별 최고, 최저 기온을 출력하는 프로그램을 작성하시오.
● 추가로, 각 월별 최고, 최저 기온을 그래프로도 출력하시오.
stnID 아는 법 : 페이지 우클릭 소스코드 보기



결과

최종코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#폰트적용
plt.rcParams['font.family'] = 'New Gulim'
plt.rcParams['font.size'] = 14
plt. rcParams['axes.unicode_minus'] = False # '-'나오는 거 설정
import requests
def genPayload(stnID, txtStnNm, startDay, endDay): # payload 변경
payload = {
'fileType': 'csv',
'pgmNo': 70,
'menuNo': 432,
'serviceSe': 'F00101',
'stdrMg': 99999,
'startDt': startDay, # 시작하는 년도월일
'endDt': endDay, # 끝나는 년도월일
'taElement': 'MIN',
'taElement': 'AVG',
'taElement': 'MAX',
'stnGroupSns': '' ,
'selectType': 1,
'mddlClssCd': 'SFC01',
'dataFormCd': 'F00501',
'dataTypeCd': 'standard',
'startDay': startDay,
'startYear': 2000,
'endDay': endDay,
'endYear': 2024,
'startMonth': '01',
'endMonth': 12,
'sesnCd': 0,
'txtStnNm': txtStnNm, # 지점정보에 해당하는 문자열
'stnId': stnID, # 지점정보
'areaId': '',
'gFontSize': ''
}
return payload
# 원하는 날짜의 기상데이터 다운받기
def downloadTempCSV(stdID, txtStnNm, startDay, endDay):
url = 'https://data.kma.go.kr/stcs/grnd/downloadGrndTaList.do'
payload = genPayload(stdID, txtStnNm, startDay, endDay)
filename = txtStnNm + str(startDay) + str(endDay) + ".csv"
r = requests.post(url, data=payload)
if r.status_code == 200:
with open(filename, 'wb') as f:
f.write(r.content)
print(filename + "다운로드 완료!")
return filename # 파일 이름 리턴하도록
else:
print(filename + "다운로드 실패!")
return None
def getMaxMinTempPerMonth(csv_filename):
df = pd.read_csv(csv_filename, skiprows =7, encoding='ms949', index_col = '날짜',
parse_dates=['날짜'])
max_temp = df['최고기온(℃)'].to_period('M').groupby('날짜').max() # 최고기온(℃) 그룹화
min_temp = df['최저기온(℃)'].to_period('M').groupby('날짜').min() # 최저기온(℃) 그룹화
result = pd.merge(max_temp, min_temp, on='날짜') # 날짜를 기준으로 합병
return result
def main():
while True:
stnID = input('지점 ID를 입력하세요(0:종료) :')
if stnID == '0':
break
stnname = input('지점 이름 : ')
startDay = input('시작 날짜 : ')
endDay = input('끝 날짜 : ')
filename = downloadTempCSV(stnID, stnname, startDay, endDay)
if filename: # 파일이름 참인 경우
result = getMaxMinTempPerMonth(filename)
print(result)
result.plot()
plt.show()
else:
print("입력값 에러")
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 12일차 - k-최근접 이웃 회귀, 선형회귀, 다항 회귀, 다중 분류, 특성공학, 규제 선형 모델 (0) | 2024.01.26 |
|---|---|
| 11일차 - 머신러닝과 딥러닝의 기본 원리, 훈련세트와 테스트세트, 데이터 전처리 (1) | 2024.01.25 |
| 9일차 - 서울시 CCTV 현황, 인구현황, 범죄현황을 기반으로 데이터 분석 실습 (0) | 2024.01.16 |
| 8일차 - 시계열 데이터를 위한 Pandas 응용 및 각종 데이터 시각화 기법 학습 및 실습 (1) | 2024.01.15 |
| 7일차 - Series, DataFrame 등과 함께 Pandas 학습 및 영화 캐스팅 정보를 활용한 실습 (0) | 2024.01.12 |



