drive.google.com/drive/folders/1dTVoapDe9bwqDwCO6HZzrXFAAWSH6K9J
Calaboratory
https://scikit-learn.org/
1-1. 인공지능
머신러닝
- 지도학습
- 비지도학습
- 강화학습
머신러닝 : 인공지능의 하위 분야, 지능을 구현하기 위한 소프트웨어를 담당하는 분야
딥러닝 : 머신러닝의 하위 분야 (머신러닝의 다양한 알고리즘 중 하나)
머신러닝의 대표적인 라이브러리 : scikit-learn (사이킷런)
TensorFlow : 인공지능에서 데이터를 처리하는 묶음의 단위,
신경망이 처리하는 단위로 흘러가게 만들어준다.
1-2 개발환경
구글 코랩
코랩 노트북 : 프로그램 작성 단위
사이킷런에서 검색하면
Parameter : 파라미터
Attributes : 학습해서 찾아낸 값
Methods : 이 클래스가 사용할 수 있는 함수들의 리스트
1-3 머신러닝의 시작
첫번째 머신러닝 프로그램
생선 이름을 자동으로 알려주는 인공지능 프로그램을 만들어 보자.
-> 생선 이름 자동 생성 프로그램
전통적인 프로그램 (software 1.0)
: data에 대해서 알고리즘을 내가 짜면 답을 줌 (data-> 알고리즘 -> 답)
누군가가 정해준 기준 (알고리즘) 대로 일을 함
인공지능 프로그램 (software 2.0)
: data하고 답을 주면 이게 뭔지는 모르겠지만 학습을 해서 관계를 만들어냄, 이 관계가 AI (data+답 -> 관계)
그 후 data를 주면 관계가 답을 줌 (data -> 답)
관계를 찾아내는 여러가지 방법이 머신러닝 -> 머신러닝은 데이터에서 규칙을 스스로 찾는다.
-> 더 나아가 기준을 찾은 뒤 스스로 판별할 수 있는 것
prompt eng (software 3.0)
: 인공지능한테 인공지능 모델을 만들라고 시키기
Kaggle.com (머신러닝 경진대회 사이트)
: https://www.kaggle.com/datasets/aungpyaeap/fish-market
생선데이터의 출처가 Kaggle
다양한 데이터셋과 코드 정보 제공
머신 러닝에서의 종류를 구분 : 클래스(class)
-> 도미/ 빙어 2개의 클래스 구분
-> 분류 문제
지도 학습 -> 분류, 회귀 로 나누어짐 (회귀는 선을 구해 어떤 값을 예측하는 것)
분류 : 합격 아니면 불합격 예측, 남자인지 여자인지 예측
회귀 : 공부한 시간에 따른 성적으로 합격, 불합격을 예측, 사진을 보고 몇 살인지 예측
-> 답을 주고 가르치는 지도 학습이 필요하다.
분류 -> 2진 분류, N진 분류 로 나누어짐
분류 중에서도 2진 분류를 해보자
도미 (bream) 데이터 준비하기

bream_length와 bream_weight 의 관계를 알고싶다.
35개의 데이터로 이루어진 파이썬 리스트
샘플 : 35마리의 도미
특성(feature) : 길이(length), 무게(weight)와 같은 특징
-> feature로 target을 알고 싶다.
문제는 feature가 많음 -> 일단 하나의 feature만 보자
도미데이터로 산점도 그려보기
산점도 (scatter plot)
: 2개의 특성을 그래프로 점으로 표시
맷플로립 라이브러리 : scatter(), show(), xlabel(), ylabel()

빙어 (smelt) 데이터 준비하기

특성(feature) : smelt_length와 smelt_weight
샘플 : 14마리의 빙어
2개의 산점도 그려보기

-> 하나의 그래프에 2개 연속 다른 색깔로 자동 표시
데이터를 사전에 시각화해서 이에 대한 식견을 얻을 수 있음

결과
도미 : 무게와 길이 비례
빙어 : 길이에 비해 무게가 크게 늘지 않음.
산점도를 통해 insight를 제공 받은 모습
첫 번째 머신러닝 프로그램
도미와 빙어 합치기

리스트 변수와 더하기 연산자로 오버로딩
도미와 빙어의 데이터를 하나의 파이선 데이터로 결합
사이킷런이 기대하는 데이터 형태 : 2차원 리스트

하나의 row가 아니라 여러 개의 row로 표시 (이중리스트의 형태) 하는 디자인
-> 리스트 내포

zip() 함수 : 나열된 리스트 각각에서 하나씩 원소를 꺼내서 반환
-> zip() 함수와 리스트 내포를 사용하여 2차원 리스트로 생성

지도 학습 : 규칙을 찾도록 정답을 알려 주어야 함
lengh와 weight는 특성(feature) 이고 이를 통해 정답을 판단

-> 연산자 오버로딩(+)을 활용한 정답 데이터 준비
-> 찾으려는 대상을 1로 설정, 그 외에는 0 (이진 분류)
KNN : K 최근접 이웃
KNN은 C(분류) 혹은 Regression(회귀) 로 사용될 수 있다.
KneighborsClassifier : KNN 분류 알고리즘

-> 객체를 kn으로 선언
kn : 해당 클래스 객체로 머신러닝 모델 역할
K 최근접 이웃은 어떻게 동작?
그래프 상에서 산점도를 그렸을 때 자기와 가까운 k개의 이웃을 구함
자기와 모든 이웃의 거리를 다 구해 짧은 거리 순서대로 나온 것 중 앞부터 K의 개수만큼 선택
- 모든 샘플에 대한 거리 구하기
- 거리가 가장 가까운 K개 선정
- 선정된 K개의 다수결

fit() : 실제로 학습하고 관계를 찾는 것, 모든 샘플과의 거리를 알아서 구해줌
-> 학습하는 훈련 함수

score() : 모델 평가(정확도, accuracy ) 함수,
fit에서 인자로 준 무게와 길이와 정답데이터를 줘서 잘 찾은지 구분
-> 0과 1사이 값 반환 (분류 문제의 맞은 개수(%))
(회귀에 있어서 score은 얼마나 비슷하게 맞췄나임)
k-최근접 이웃 알고리즘
새로운 생선 (세모 예측)
새로운 생선(30, 600)이 포함된 그래프 그려보기

predict() : 2차원 리스트 입력 및 새로운 데이터에 대한 예측 출력

실행결과 -> 1번 클래스(도미)이다 라는 의미
사이킷런에서 넘파이 array라는 의미
K-최근접 이웃
가장 가까운 직선 거리에 어떠한 데이터가 있는지 살핌
단점 : 데이터가 아주 많은 경우 계산량 증가로 오버헤드 발생
무조건 도미
전체에 대한 다수결을 보겠다.
K의 개수를 49로 하면 도미의 개수가 더 많아 무조건 도미로 봄

이웃을 49로 하겠다.
fit하고 score한 결과 0.71.. 이 나옴
-> 71퍼만 맞혔다.
K-최근접 이웃의 기본 참조 이웃값 : 5개
전체 데이터 = 49 (도미 35, 빙어 14)에 대해 판단 (기본값은 5)
이 경우 모든 데이터를 사용하여 다수결로 판단
0.71(71%)가 1에 가까워 무조건 도미로 판단
매개변수를 48로 사용하는 것 보다는 5로 사용하자.
확인 문제

이웃이 17까지는 괜찮았다.
2-1 훈련세트와 테스트세트
이전 방식의 문제점 두가지
(문제1) 규칙을 찾는 것이 아닌, 가까운 이웃을 골라 다수의 클래스 예측?
인공지능인가 단순 통계인가?
(문제2) 예상 문제를 주고, 예상 문제로 시험을 보는 상황?
fit 에서 사용된 데이터와는 별도로, score 함수를 위한 별도의 테스트 데이터가 필요
지도 학습과 비지도 학습
지도 학습
: 데이터와 정답을 입력과 타겟이라고 함 이를 합하여 훈련 데이터
지도 학습은 분류와 회귀 2개의 카테고리로 나누어짐
(K-최근접 이웃 분류는 앞서 한 훈련데이터로 한 도미와 빙어)
(K-최근접 이웃 회귀는 특정한 값을 예측, 가까운 K개의 값을 구한 후 평균 내기)
비지도 학습
: 정답 없음, 전체 데이터 파악/ 변형에 도움을 줌
훈련 세트와 테스트 세트
출제될 시험 문제와 정답을 미리 주고 시험을 본다? 당연히 100점
연습 문제와 시험 문제가 달라야함
훈련 세트 35개, 테스트 세트 14개로 별도로 테스트용 데이터 준비
혹은, 훈련 데이터의 일부를 테스트로 사용
훈련 세트 vs 테스트 세트

-> 1장에서는 fish_data 와 fish_target을 사용했으나,
이를 train/test.input & train/test.target으로 4가지 형태로 구분하여 사용
훈련 세트에서 훈련하고 테스트 세트에서 평가하기

훈련된 것을 kn 객체가 attribute 속성으로 갖고 있음
train 데이터로 fit() 함수 호출, test 데이터로 score() 함수 호출
-> 0 나옴 (다 틀렸다.)
-> 훈련 세트에는 빙어가 없고 테스트 세트에는 도미가 없다.
앞에선 테스트 세트가 없었고 이번엔 쪼갰는데 이렇게 쪼개면 안된다
-> 즉, 샘플링 편향 (sampling bias) 이 발생하면 안된다.
샘플링 편향 (sampling bias)
훈련 세트에는 빙어가 없고 테스트 세트에는 도미가 없다.
수업 시간에는 미분적분 가르치고, 시험에서는 확률통계를 출제하는 꼴
-> 35 + 14가 적절히 분배되어 있어야함
넘파이 사용하기
넘파이
: 파이썬의 대표적인 배열 라이브러리
고차원의 배열을 손쉽게 생성 및 조작
생선 데이터를 2차원 넘파이 배열로 변환해보자
(기존에는 zip() 함수로 생성된 2차원 리스트를 사용했음)

-> np.array() : 파이썬 리스트를 넘파이 배열로 변환
넘파이는 자동으로 행과 열을 가지런히 출력해줌
파이썬 리스트와 넘파이 배열과의 외형적 차이는 없음
데이터 섞기
넘파이 배열로 생성된 데이터를 랜덤하게 샘플링해보자
(단, 입력과 정답의 같은 위치가 상호 샘플링 되어야 함.)
절차 : 인덱스 배열 생성 -> 인덱스 배열 shuffle -> 인덱스 배열 slicing w/ 배열 인덱싱
-> 배열의 인덱스 생성 후, 인덱스를 섞은 후 배열 슬라이싱
입력과 타겟이 같이 섞여야함

-> 데이터를 섞지 않고, 배열 인덱스 생성 후 인덱스를 섞음
arange() : 인덱스 생성
shuffle() : 인덱스를 42번 seed로 랜덤하게 섞음

-> index[:35] : 넘파이의 '배열 인덱싱' 기능
: 한 개의 인덱스가 아닌 여러개의 인덱스로 한 번에 여러 개의 원소 선택 가능 기능
데이터 나누고 확인하기
앞 슬라이드 35개와 함께 나머지 14개로는 테스트 세트 생성

train_input[ :, 0 ] : 테스트에 대한 모든 길이와 무게
[ : , 0] : 전체 행에 대한 첫번째 열 (length)
[ : , 1] : 전체 행에 대한 두번째 열 (weight)
데이터가 잘 섞였는지 시각적으로 확인 가능
두 번째 머신러닝 프로그램
데이터를 구분한 뒤, 다시 모델 훈련
train과 test를 잘 섞어 앞엔 파란색 점으로만 학습
빨간색 점도 활용하기
fit() 함수는 실행할 때마다 이전에 학습한 내용을 잃어 버림
이전 모델을 그대로 두고 싶다면 객체 새로 만들기!
훈련 세트와 테스트를 구분하여 학습시켰으며 결과는 100% 정확한 예측 제공

2-2 데이터 전처리
100% 정확한 모델을 달성했는가?
조금 작은 도미, 길이가 25cm이고 무게가 150g 이면 누가봐도 도미인데 주어진 모델이 빙어로 예측
(빙어 길이는 10cm, 무게는 10~20g 정도)
넘파이로 데이터 준비하기
기존 파이썬 작업을 넘파이 함수 작업으로 수행
np.column_stack() : 두 리스트를 하나로 합하는 zip 말고 또 다른 방법

-> 넘파이 배열의 또 다른 장점 : 리스트 형태가 아닌 가지런히 정렬된 모습으로 출력
(fish_data = [[l, w] for l, w in zip(length, weight)] 대신 사용 )

concatenate() : 연산자 오버로딩 같이 갖다붙이는 다른 방법
(fish_target = [1] * 35 + [0] * 14 대신 사용)
- np.zeros
- np.ones((2, 3)) : 1로 2by3 행렬을 초기화
- np.full((2, 3), 9) : 특정 값으로 생성
사이킷런으로 훈련 세트와 테스트 세트 나누기
훈련 세트와 테스트 세트의 구분
앞장에서의 배열 셔플/ 슬라이싱 외의 일반적인 방법
train_test_split : 자기가 알아서 train 세트와 test 세트로 쪼개줌
2개의 배열 입력으로 4개의 배열 반환
기본적으로 25%를 테스트 세트로 떼어냄
(test size/ train size 옵션으로 실제 비율을 25% 외 다른 것으로 조절 가능)


stratify
: 샘플링 편향이 생기지 않도록 target class를 섞는데 타겟 배열을 보고 잘 섞이도록 만들어줌
-> 타겟 레이블의 비율을 고려하자
random으로 데이터를 나누어도 샘플이 골고루 섞이지 않을 수 있음 (일부 클래스의 개수가 적은 경우)
클래스 비율에 맞게 무작위로 데이터를 나누어 주는 역할
-> 완전 random vs 비율 유지 random (여기서 처럼 비율 유지 대상 지정 = fish_target)
수상한 도미 한마리 (작은 도미)
실제 이웃이 무엇인지 확인해보자



kneighbors() : 최근접 알고리즘이 바라보는 이웃 거리와 인덱스 반환
-> 최근접으로 바라보는 인덱스와 각각의 인덱스의 제일 짧은 거리 반환
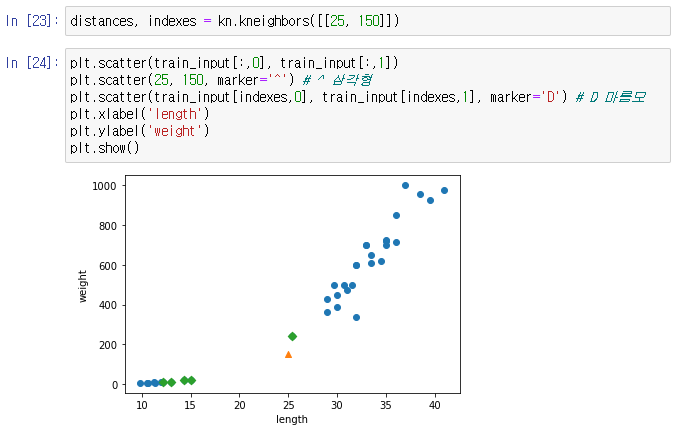
-> 시각적으로는 가깝지만 스케일이 문제
length는 10 차이씩이지만 weight는 scale이 100
기준을 맞춰라
축간의 스케일이 문제
멀어보이지만 130 밖에 안되고 위쪽은 200 이상
즉, x축은 범위가 좁고(0~40) y축은 범위가 넓다(0~1000)

-> distance 배열을 출력하여 실제 거리값 확인
scale을 1000으로 조정해보기
lim() : x축의 범위 지정 함수

무게가 생선을 결정하는데 길이보다 더 큰 영향을 주는 상황
스케일이 큰 특성에 영향을 받는다 (단, 회귀, 트리는 스케일에 영향 받지 않음, 회귀는 관계성에만 영향 받음)
-> 특성 값으로 관계를 파악하는데 어떤건 0~1 이고 어떤건 0~1000 이면 0~1000에 좌우될 수 밖에 없다.
-> 분류는 특성 사이의 스케일을 통일화 시키는 것이 필요하다.
-> 축의 scale을 통일하여도, 출력된 그림이 좋아보이지 않음
스케일을 통일하는 방법
데이터 전처리
: 특성이 가지는 가중치가 영향을 끼치기 때문에 데이터 전처리 필수
두 개의 특성의 스케일이 달라도 일정한 영향력을 주기 위해 특성값을 일정한 기준에 맞춤
-> 표준 점수 (혹은 z 점수) 사용
표준 점수 = ( 특성 - 평균 ) / 표준 편차 : 평균에서 표준편차의 몇 배 만큼 떨어져있는가
(표준 편차 : ((데이터 - 평균)의 제곱의 평균 -> 분산)의 제곱근)
- axis = 0 : 행을 바꿔가면서 특정한 열의 통계적인 값 구하는 것
- axis = 1 : 열을 바꿔가면서 특정한 행의 통계적인 값 구하는 것
train_input은 numpy 배열로 만들었음
NumPy Broadcasting : 넘파이 배열 연산의 특징


수상한 도미 다시 표시하기
new 데이터(수상한 도미) 도 다시 스케일링을 해야함
훈련 세트와 평균과 표준 편차로 테스트 세트(샘플) 도 변환하기

전처리 데이터에서 모델 훈련
train_target 은 0아님 1이라 스케일 조정 필요 X
입력 값만 스케일 조정
테스트 세트도 훈련 세트와 동일한 스케일 값으로 변환

-> 스케일 조정으로 거리상 가까운 생선이 재선정됨
데이터 전처리
train_test를 문제가 있어 쪼개야한다.
-> 데이터 상관관계가 데이터 특성에 따라 달라 조정해야한다
-> 스케일 통일 기법 : 표준 점수로 조정 (= 정규화) 해야한다.
표준 점수 = (특성 - 평균) / 표준 편차
: 평균에서 표준편차의 몇 배 만큼 떨어져 있나?
훈련 세트 방색 그대로 테스트 세트도 스케일 조정 해야한다.
(훈련 세트의 평균과 표준편차 값 그대로 사용)
분류 문제는 스케일 조정 작업이 필수
회귀 문제는 스케일 과정 필요 없다.
사진 출처 : 혼자 공부하는 머신러닝 + 딥러닝 강의자료
'파이썬 & 머신러닝과 딥러닝' 카테고리의 다른 글
| 13일차 - 로지스틱 회귀, 딥러닝을 위한 기초수학, 선형 회귀, 경사하강, 다중 선형 회귀 (1) | 2024.01.29 |
|---|---|
| 12일차 - k-최근접 이웃 회귀, 선형회귀, 다항 회귀, 다중 분류, 특성공학, 규제 선형 모델 (0) | 2024.01.26 |
| 10일차 - 웹스크래핑 기법 학습 및 이를 기반으로 한 미니프로젝트 수행 (0) | 2024.01.17 |
| 9일차 - 서울시 CCTV 현황, 인구현황, 범죄현황을 기반으로 데이터 분석 실습 (0) | 2024.01.16 |
| 8일차 - 시계열 데이터를 위한 Pandas 응용 및 각종 데이터 시각화 기법 학습 및 실습 (1) | 2024.01.15 |



